Always-on Availability group(AG) 구성의 SQL Server에서 Primary replica가 병렬 Index Rebuild 수행 시 Secondary도 동일한 수량의 병렬 Index Rebuild를 수행하는지를 문의주신 건으로 이해됩니다.
AG의 데이터 동기화는 Primary Replica에서 발생한 Transaction log를 Secondary Replica에서 Redo하는 단계로 진행됩니다.
참고로 SQL Server 2016 이후 Parallel redo thread(Instance당 최대 100개, Database당 최대 16개)를 지원합니다.
다만, 이 Parallel redo thread의 개수는 Primary replica에서 Transaction log를 발생시킨 쿼리의 DoP와 관계 없이, 현재 Secondary replica에서 Transaction log를 Redo하는 부하 상황에 따라 달라지게 됩니다.
이 때문에, Primary replica에서 병렬 Index Rebuild 수행 시 Secondary replica에서 병렬로 Redo를 수행할 가능성은 높으나, Index Rebuild 상황을 Redo하는 Secondary Replica의 Redo Thread 개수는, 일반적으로 Primary replica의 Index Rebuild Thread 개수보다 적게 됩니다.
예를 들어 다음과 같이 테스트환경에서 약 10GB 크기의 테이블에 대해, MAXDOP 4의 병렬 Index Rebuild를 수행하여 Secondary Replica에서 Redo thread를 모니터링 하면, Primary Replica는 DoP 4로 Index Rebuild를 수행하고 있으나, 같은 시점의 Secondary Replica는 3개의 Redo thread로 Transaction을 Redo 하고 있음을 확인할 수 있습니다.
Case
Result
Test Scenario - 약 10GB 크기의 테이블에 Maxdop=4로 Index Rebuild를 수행
EXECsys.sp_spaceused'dbo.tbl_Index_ParallelBuild' GO
ALTERINDEX UCL__tbl_Index_ParallelBuild__01 ON dbo.tbl_Index_ParallelBuild REBUILDWITH (MAXDOP= 4) GO
Primary Replica - 첨부드리는 Monitor_IndexRebuild_ParallelRedo.sql 쿼리를 통해 74번 세션에서 수행중인 Index Rebuild 수행 상황을 모니터링 하면, 2개의 Consumer thread를 제외하고, 4개의 Thread로 Parallel Rebuild 수행중임을 확인할 수 있습니다.
Secondary Replica - 첨부드리는 Monitor_IndexRebuild_ParallelRedo.sql 쿼리를 통해 AG의 Redo 수행 상황을 모니터링 하면, AGDB01 데이터베이스에 대해 3개의 Parallel redo thread가 Index rebuild를 수행중임을 확인할 수 있습니다.
일반적으로 백업은 DML을 blocking 하지 않으나 백업이 진행중일 때는 database/file을 shrink 할 수 없으며,
Primary에서 Log shrink 를 진행해도 Secondary에도 적용이 되기 때문에 위와 같은 Lock wait이 발생하게 됩니다.
Limitations and restrictions
The database can't be made smaller than the minimum size of the database. The minimum size is the size specified when the database was originally created, or the last explicit size set by using a file-size-changing operation, such as DBCC SHRINKFILE. For example, if a database was originally created with a size of 10 MB and grew to 100 MB, the smallest size the database could be reduced to is 10 MB, even if all the data in the database has been deleted. You can't shrink a database while the database is being backed up. Conversely, you can't back up a database while a shrink operation on the database is in process. You cannot shrink files while database Backups are happening. You might also notice that these commands encounter a wait_type = LCK_M_U and a wait_resource = DATABASE: <id> [BULKOP_BACKUP_DB] when the status of these commands is viewed from the various dynamic management views (DMVs), such as from sys.dm_exec_requests or sys.dm_os_waiting_tasks.
흐름 제어로 인해 높은 로그 전송 큐 크기 및 낮은 로그 전송 속도---- >SQL AG의 성능이 특정 SQL AG 데이터베이스 또는 SQL AG 복제본 수준에서 흐름 제어 게이트를 트리거하면 로그 데이터 전송이 일시적으로 종료되고 제한됩니다. 초등부터 중등까지. 흐름 제어는 일반적으로 서버 과부하 또는 느린 네트워크로 인해 발생할 수 있습니다. AG에서 흐름 제어 게이트에 진입하는 것을 지속적으로 관찰한 경우 흐름 제어를 유발하는 환경 조건을 해결해야 합니다. 아래 성능 모니터 카운터를 확인하여 SQL AG 데이터베이스 또는 SQL AG 복제본이 흐름 제어 게이트를 트리거했는지 확인할 수 있습니다.
보조 복제본의 병렬 다시 실행 스레드 부족 --- 보조 복제본에 병렬 다시 실행 스레드가 부족하면 TF3478을 사용하여 총 CPU 수에 따라 병렬 다시 실행 스레드의 최대 수가 증가하도록 허용할 수 있습니다. 기본적으로 SQL Server 인스턴스는 보조 복제본에 대한 병렬 다시 실행을 위해 최대 100개의 스레드를 사용합니다. 각 데이터베이스는 총 CPU 코어 수의 최대 절반을 사용하지만 데이터베이스당 스레드는 16개를 초과할 수 없습니다. 단일 인스턴스에 필요한 총 스레드 수가 100을 초과하면 SQL Server는 나머지 모든 데이터베이스에 대해 단일 다시 실행 스레드를 사용합니다.
디스크 또는 I/O 하위 시스템 대기 시간--> 보조 복제본의 디스크 또는 I/O 하위 시스템에 심각한 병목 현상이 있는 경우 다시 실행 속도가 영향을 받으며 보조 복제본에서는 매우 작습니다. 보조 복제본을 읽을 수 없고 SQL 데이터베이스 파일 스토리지에 대해 기본 및 이 SQL AG의 사용 전용 하드웨어와 유사한 하드웨어가 있는 경우 기본 복제본에 도달하기 전에 보조 복제본에서 이를 볼 가능성이 적습니다. 그러나 보조 복제본에 읽기 전용 워크로드의 양이 많은 경우 IO 하위 시스템에 추가 IO 오버헤드가 발생할 수 있습니다. 빈번한 데이터베이스 백업 및 VM 스냅샷은 추가 I/O 오버
각 SQL Server Always On 가용성 그룹에 대한 기존 가용성 복제본에 대한 정보를 얻습니다.예를 들어 내 랩 환경에는 [demoag] 및 [SQLAGDemo]라는 두 개의 가용성 그룹이 있습니다.각 가용성 그룹에는 2개의 복제본이 있으므로 출력에 4개의 행이 표시됩니다.
seeding_mode:직접 시드의 경우 자동 값을 표시하고 그렇지 않으면 수동 시드를 얻습니다.
read_write_routing_url:SQL Server 2019에서는 모든 읽기-쓰기 연결에 대해 보조 복제본에서 주 복제본으로 연결을 리디렉션할 수 있습니다.사용자가 보조 복제본에도 연결하는 경우 내부 연결이 기본 복제본으로 다시 라우팅되기 때문에 오류 메시지가 표시되지 않습니다.
WSFC에서 AG의 가용성 복제본에 대한 정보를 제공합니다.복제본 상태에 관계없이 가용성 복제본에 대한 정보를 얻습니다.
출력에서 복제본 서버와 인스턴스 이름을 볼 수 있습니다.
sys.dm_hadr_availability_replica_states
로컬 복제본, 원격 복제본 및 해당 동기화 상태에 대한 세부 정보를 얻는 데 유용한 DMV입니다.다음은 이 DMV의 중요한 열입니다.
role 및 role_desc:이 열에서 SQL Server Always On 가용성 그룹의 복제본 역할을 얻습니다.
0= 해결 중 - 해결 중 상태에서 Windows Server 장애 조치 클러스터는 장애 조치 중간 또는 실패 상태일 수 있습니다.WSFC에 쿼럼이 없으면 AG도 상태 확인에 표시됩니다.
1: 기본(AG 기본 복제본)
2: 보조( AG 보조 복제본)
Operational_state 및 Operational_state_desc: 이 열에서 복제본의 현재 작동 상태를 가져옵니다.이 열에 다음 값을 가질 수 있습니다.
0- 보류 중인 장애 조치
1- 보류 중:
2- 온라인
3- 오프라인
4-실패
5- No Quorum으로 인한 실패
기본: 온라인, 보류 중, 실패
보조: 온라인, 실패 및 NULL
해결 중: 오프라인, Pending_failover, 실패 및 쿼럼 없음으로 실패
recovery_health 및 recovery_health_desc:이 DMV에 대한 ONLINE_IN_PROGRESS 및 ONLINE 값을 가져옵니다.DMV sys.dm_hadr_database_replica_states의 database_state 열에 대한 롤업입니다.
synchronization_health 및 synchronization_health_desc:동기 또는 비동기 커밋에서 모든 가용성 그룹 데이터베이스의 동기화 상태를 가져옵니다.이러한 열에 가능한 값은 다음과 같습니다.
0:건강하지 않음
1:부분적으로 건강함
2:건강한
가용성 데이터베이스 모니터링
이 범주에서는 SQL Server Always On 가용성 그룹의 가용성 데이터베이스와 관련된 동적 관리 보기를 살펴봅니다.
sys.dm_hadr_auto_page_repair
SQL Server Always On 가용성 그룹은 자동 페이지 복구 기능을 제공합니다.손상된 페이지의 경우 아래 이미지와 같이 다른 복제본에서 페이지를 수신합니다.
기본 및 보조 복제본 동기화, 로그 시퀀스 번호, 데이터베이스 상태, suspend\resume에 대한 정보를 얻는 데에도 유용한 DMV입니다.AG 대시보드에서 기본, 보조 복제본 상태에 대한 정보를 볼 수 있습니다.대시보드는 이 DMV에서 정보를 가져와 그래픽 형식으로 표시합니다.
기본 복제본과 보조 복제본 모두에서 AG 대시보드를 실행할 수 있습니다.기본 복제본의 AG 대시보드에는 모든 복제본에 대한 정보가 표시됩니다.그러나 보조 복제본에서 시작하면 연결된 보조 복제본에 대한 정보만 가져옵니다.
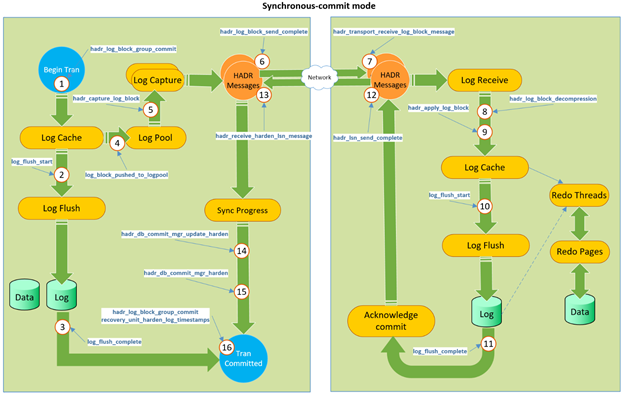
아래 그림은 동기 커밋 모드에서 로그 블록이 Replica 서버에 커밋 되는 각 단계마다 XEvent가 캡쳐 되는 흐름을 보여준다.
위 그림에서 살펴보면 XEvent 추적이 캡처되면 로그 블록 이동의 각 단계에서 중요한 시점을 알 수 있으므로 트랜잭션 대기 시간의 정확한 위치를 알 수 있다. 일반적으로 지연은 세 부분으로 나누어진다.
Primary 서버에서 log harden 지속 시간 Log_flush_start(step 2) 및 Log_flush_complete(step 3)의 델타 시간은 동일하다.
Replica 서버에서 log harden 지속 시간 Log_flush_start(step 10) 및 Log_flush_complete(step 11)의 델타 시간은 동일하다.
네트워크 트래픽의 지속 시간 Primary : hadr_log_block_send_complete ->secondary:hadr_transport_receive_log_block_message (step 6-7)Secondary : hadr_lsn_send_complete->primary:hadr_receive_harden_lsn_message (step 12-13)
아래 스크립트는XEvent를 사용하여 각 단계에 소요되는 시간을 캡처할 수 있다.
/* Note: this trace could generate very large amount of data very quickly, depends on the actual transaction rate. On a busy server it can grow several GB per minute, so do not run the script too long to avoid the impact to the production server. */CREATEEVENTSESSION [AlwaysOn_Data_Movement_Tracing] ONSERVERADDEVENT sqlserver.file_write_completed,ADDEVENT sqlserver.file_write_enqueued,ADDEVENT sqlserver.hadr_apply_log_block,ADDEVENT sqlserver.hadr_apply_vlfheader,ADDEVENT sqlserver.hadr_capture_compressed_log_cache,ADDEVENT sqlserver.hadr_capture_filestream_wait,ADDEVENT sqlserver.hadr_capture_log_block,ADDEVENT sqlserver.hadr_capture_vlfheader,ADDEVENT sqlserver.hadr_db_commit_mgr_harden,ADDEVENT sqlserver.hadr_db_commit_mgr_harden_still_waiting,ADDEVENT sqlserver.hadr_db_commit_mgr_update_harden,ADDEVENT sqlserver.hadr_filestream_processed_block,ADDEVENT sqlserver.hadr_log_block_compression,ADDEVENT sqlserver.hadr_log_block_decompression,ADDEVENT sqlserver.hadr_log_block_group_commit ,ADDEVENT sqlserver.hadr_log_block_send_complete,ADDEVENT sqlserver.hadr_lsn_send_complete,ADDEVENT sqlserver.hadr_receive_harden_lsn_message,ADDEVENT sqlserver.hadr_send_harden_lsn_message,ADDEVENT sqlserver.hadr_transport_flow_control_action,ADDEVENT sqlserver.hadr_transport_receive_log_block_message,ADDEVENT sqlserver.log_block_pushed_to_logpool,ADDEVENT sqlserver.log_flush_complete ,ADDEVENT sqlserver.log_flush_start,ADDEVENT sqlserver.recovery_unit_harden_log_timestamps ADDTARGET package0.event_file(SETfilename=N'c:\mslog\AlwaysOn_Data_Movement_Tracing.xel',max_file_size=(500),max_rollover_files=(4))WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON)GO
아래 그림은 XEvent를 실행하여 캡처한 결과이다.[Primary]
[Second synchronous replica]
참고로 hadr_receive_harden_lsn_message의 log_block_id(14602889512)가 다른 ID(146028889488)와 동일하지 않는데, 그이유는 항상 다음의 harden log block의ID를 즉시 반환하기 때문이다. hadr_db_commit_mgr_update_harden xevent를 사용하여 XEvent를 상호연관 시킬 수 있다.
위의 XEvent 로그를 사용하여 캡처한 데이터를 사용하여 아래 표처럼 만들어서 트랜잭션 커밋의 상세한 지연시간을 확인할 수 있다. 이 리스트는 네트워크 및 log harden process의 시간 델타(latency)를 나열한 것이며 로그 블록의 압축이나 해제 등 다른 시간이 발생할 수도 있다.
위에서 언급했든이 주로 발생하는 대기시간은 다음 세 부분에서 발생한다.복제본간의 네트워크 대기시간 : 3.907 + 0.857 = 4.494Primary Log harden : 0.663Secondary Log harden : 0.663 총 트랜잭션 지연시간을 얻기에는Primary 로그 플러시와 네트워크 전송이 동시에 발생하기 때문에 합산할 수 없어 쉽지 않다.
네트워크에서 4.494초가 발생하였고, Primary가 복제본으로부터 컨펌(hadr_receive_harden_lsn_message:2018-03-06 16:56:33.3732126)을 받고 완료한 시간을 (log_flush_complete : 2018-03-06 16 : 56 : 28.8785928) 시간을 계산할때 타임스탬프를 수동으로 계산할 필요가 없다.
XEvent는 두 개의 hadr_log_block_group_commit사이의 델타시간을 알 수 있기 때문이다. 아래 예시를 살펴보자.Primary: hadr_log_block_group_commit: 2018-03-06 16:56:28.2167393Primary: hadr_log_block_group_commit: 2018-03-06 16:56:33.3732847Total time to commit=delta of above two timestamps= 5.157 seconds 이 숫자는 네트워크 전송 시간과Secondary서버의 log harden을 더한것과 같다. 그 이유는Secondary 서버의log harden 가 네트워크를 사용할 수 있기를 기다려야하므 Primary와 마찬가지로 동시에 log harden를 할 수 없기 때문이다.
지금까지 AlwaysOn 동기-커밋 모드에서 복제본간 로그 블록 이동에 대해서 살펴보았다.
그런데 Primary 서버의 XEvent에서 "hadr_db_commit_mgr_harden_still_waiting"가 가끔 발생하는 것을 볼수 있는데 이 이벤트는 Primary 서버가 Secondary 복제본의 확인 메시지를 기다리고 있을때 2초 간격으로 발생(2초로 하드코딩 되어있음)한다. 2초 내에 Ack이 돌아오면 XEvent에 표시되지 않는다.
고객이 엔지니어로서 미션 크리티컬 애플리케이션을 사용하는 경우 항상 HA (고 가용성) 및 (DR) 재해 복구에 중점을 둡니다. 따라서 "Always On"은 고 가용성 및 재해 복구를 달성하기위한 단순화 된 통합 솔루션입니다. 가용성 그룹은 여러 다른 기능과 함께 여러 활성 보조 노드뿐만 아니라 여러 데이터베이스 장애 조치를 지원하는 새로운 개념입니다.
간단히 말해서 고객 데이터를 보호하기 위해 여러 개의 SQL Server와 동기화 된 데이터베이스가 있습니다. 우리는 이미 소프트웨어가 요구 사항 및 새로운 기능 추가와 일치하기 위해 항상 업그레이드 및 패치가 필요하다는 것을 알고 있으며, 프로덕션 환경에서도 독립형 SQL Server를 쉽게 업그레이드 할 수 있습니다. 가용성 그룹의 경우 까다 롭습니다. 따라서 중단 시간없이 SQL Server 인스턴스를 업그레이드하는 데 도움이되는 단계를 제공하려고 생각했습니다.
업계에는 여러 유형의 가용성 그룹 토폴로지가 있습니다. 다음은 몇 가지 예입니다.
원격 보조 복제본이있는 가용성 그룹
장애 조치 클러스터 인스턴스 노드가있는 가용성 그룹
보조 복제본이 여러 개인 가용성 그룹 (복제본 중 하나에 대한 비동기 커밋)
간단한 토폴로지를 보자. 이 다이어그램은 고객 설정을 설명합니다.
업그레이드 단계
SQL Server에서 AG 속성으로 이동
자동 장애 조치를 피하려면 가용성 모드를 "비동기"로 변경하십시오.
이러한 단계는 SSMS (SQL Management Studio)에 연결하여 기본 복제본 (노드)에서 수행해야합니다.
두 번째 단계는 보조 복제본을 업그레이드하는 것입니다. [2014 년에서 2016 년으로 업그레이드 할 수 있습니다]