통계 자동 갱신 조건과 별개로 옵티마이저 판단 SQL Server는 통계가 오래되거나 변경되면 자동으로 갱신하고 그때 계획을 다시 컴파일합니다. 하지만 통계 갱신이 없더라도, 데이터 분포 변화가 심해 기존 계획이 비효율적이라고 판단되면 옵티마이저가 강제 Recompile을 트리거할 수 있습니다.
DML로 인한 데이터 양 변화 예를 들어, 특정 테이블에 대량의 INSERT/DELETE가 발생해 행 수가 급격히 변하면, 기존 계획의 조인 전략(예: Nested Loop vs Hash Join)이 더 이상 적합하지 않을 수 있습니다. 이 경우 옵티마이저는 계획 캐시를 무효화하고 새 계획을 생성합니다. ü 대량 DML로 인해 통계 임계치 초과 시 자동 갱신 → 기존 계획의 카디널리티 추정이 틀려서 재컴파일 발생
옵션 및 힌트 영향 OPTION(RECOMPILE) 힌트가 있거나, 저장 프로시저에 WITH RECOMPILE이 설정된 경우 매 실행마다 새 계획을 생성합니다. 파라미터 스니핑으로 인해 특정 값에서 기존 계획이 비효율적일 때도 Recompile이 발생합니다.
메모리 압박 또는 캐시 제거 DBCC FREEPROCCACHE 실행, 메모리 부족으로 인한 캐시 제거 등도 재컴파일을 유발합니다.
스키마 변경 o ALTER TABLE, ALTER VIEW, 인덱스 생성/삭제 o 제약조건, 열 추가/삭제 → 계획이 참조하는 객체 구조가 바뀌면 무효화
SET 옵션 변경 ANSI_NULLS, QUOTED_IDENTIFIER 등 세션 옵션 변경 시
임시 테이블 변경 Temp Table 구조 변경, 인덱스 추가/삭제
기타 Query Store 강제 계획 적용 실패 데이터베이스 버전 변경 파티션 뷰 변경 등
또한 통계 갱신이 없더라도 옵티마이저는 내부 임계값을 기준으로 판단합니다.
예를 들어 특정 테이블에서 수백만 건의 INSERT가 발생하게 될 경우, 통계는 아직 갱신되지 않았지만, 옵티마이저는 기존 계획이 잘못될 가능성이 높다고 판단하여 Recompile을 수행할 수 있고, 파라미터 값 변화로 인해 기존 Plan이 비효율적으로 판단될 경우 Recompile을 수행할 수 있습니다.
Recompile이 발생하는 경우는 여러가지 이유가 있으며 테이블의 컬럼 및 인덱스 변경, Set옵션의 변경, 서버 재시작, 플랜캐시의 상황으로 캐시에서 밀려난 후 Compile, RECOMPILE 힌트, 명시적인 SP_Recompile등의 요소에 의해 발생할 수 있습니다.
해당 시간 전환 전/후로 아래와 같이 쿼리하여 현재SQL Server가 인지하는 시간값을retrieve하실 수 있으며,
혹시 해당 시간 전환이 잘 안 될 경우 서버에서 제대로 시간 변경이 안 되는 것이므로 이 때NTP서버와의 통신 상태 점검 및Windows레벨에서의 시간 설정을 확인해 보실 수 있습니다.
--1.현재 시간 확인 SELECT SYSDATETIMEOFFSET() AS now_with_offset; --2.조회 시점 폴란드Timezone DST적용 여부 확인 SELECT * FROM sys.time_zone_info WHERE name LIKE 'Central European%';
WRITELOG대기 원인 분석을 위해 성능 모니터와 세션 정보 수집을 권장 드립니다. 성능 카운터는 전반적인 시스템 상태를 확인하는 데 유용하며,세션 정보는 어떤 쿼리나 트랜잭션이WRITELOG대기를 발생시키는지 파악하고 세부 분석하는 데 도움이 됩니다. 수집 방법은 아래와 같습니다.
1. SQL성능 카운터 수집
Step1 cmd를 관리자권한으로 실행한 뒤 아래 명령을 실행하면 성능 수집기가 생성됩니다. 1초 주기로 최대 1024MB까지 수집되며,수집 경로는 환경에 맞게 수정해 주시기 바랍니다. WRITELOG대기 발생 시점을 알고 있는 경우,해당 짧은 기간 동안1초 간격으로 수집할 것을 권장 드립니다. 발생 시점을 알 수 없는 경우에는10~15초 간격으로 하루 정도 수집하는 것을 권장 드립니다.
CREATE DATABASE tmpMonitoringDB GO use tmpMonitoringDB GO select top(1) getdate() as ctime, db_name(der.database_id) as database_name, der.*, dest.text, des.program_name into dm_exec_requests_history from sys.dm_exec_requests as der inner join sys.dm_exec_sessions as des on der.session_id = des.session_id cross apply sys.dm_exec_sql_text(der.sql_handle) as dest GO truncate table dm_exec_requests_history GO
Step2 1초 단위로 루프를 수행하면서 세션 정보를 수집합니다. 무한 루프이므로 상황이 종료된 이후 쿼리를 직접 취소하시면 됩니다.
declare @startTime datetime = getdate() while 1=1 begin insert into dm_exec_requests_history select getdate() as ctime, db_name(der.database_id) as database_name, der.*, dest.text, des.program_name from sys.dm_exec_requests as der inner join sys.dm_exec_sessions as des on der.session_id = des.session_id cross apply sys.dm_exec_sql_text(der.sql_handle) as dest where der.session_id <> @@spid waitfor delay '00:00:01' end
DB_01 / DB_02서버와 관련하여, (UTC+9) 03:29 ~ 04:42구간DB_02서버로의Failover시도5회 진행 하였으나, RESOLVING_PENDING_FAILOVER상태에서DB_01으로Fail back및DB_02서버는Resolving상태에 빠진 이후 다시Secondary Online되었습니다.
03:29:32.770 spid142 The state of the local availability replica in availability group 'DB_AVG' has changed from 'SECONDARY_NORMAL'to 'RESOLVING_PENDING_FAILOVER'....... 03:35:45.550 spid111 The state of the local availability replica in availability group 'DB_AVG' has changed from 'SECONDARY_NORMAL'to 'RESOLVING_PENDING_FAILOVER'....... 03:44:16.190 spid70 The state of the local availability replica in availability group 'DB_AVG' has changed from 'SECONDARY_NORMAL'to 'RESOLVING_PENDING_FAILOVER'....... 03:46:32.790 spid111 The state of the local availability replica in availability group 'DB_AVG' has changed from 'SECONDARY_NORMAL'to 'RESOLVING_PENDING_FAILOVER'....... 04:37:00.190 spid135 The state of the local availability replica in availability group 'DB_AVG' has changed from 'SECONDARY_NORMAL'to 'RESOLVING_PENDING_FAILOVER'.......
이와 관련하여03:35:45 ~ 03:40:50구간의Failover이력 확인 시, DB_ 01 > DB_ 02방향의Manual Failover과정에서DB_02 > DB_ 01방향의Connection Timeout이슈로Failover가 실패한 것으로 확인됩니다.
spid111 The state of the local availability replica in availability group'DB_AVG' has changedfrom'SECONDARY_NORMAL' to 'RESOLVING_PENDING_FAILOVER'. The state changed because of auser initiated failover. ...... ......
03:35:45.570
The state of the local availability replica in availability group'DB_AVG' has changed from 'PRIMARY_NORMAL' to 'RESOLVING_NORMAL'. The state changed because the availability group is going offline. ............ ...... ......
03:35:45.570
The availability group database"DB_NAME" is changing roles from "PRIMARY" to "RESOLVING"because the mirroring session or availability group failed over due to role synchronization. ......
Aconnection timeout has occurred on a previously established connection to availability replica ' DB_ 01'with id [82A59128-5DE5-45B0-9D84-0A3B2E3DCBCD]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
03:36:00.580
Always On Availability Groups connection withprimary database terminated for secondary database 'DB_NAME'on theavailability replica ' DB_ 01'with Replica ID: {82a59128-5de5-45b0-9d84-0a3b2e3dcbcd}. ......
03:36:05 ~ 03:36:25
Remote harden of transaction 'GhostCleanupTask' (ID 0x0000004f44ca32ed 0001:ea796d64) started at Aug 17 2025 3:36AM in database 'DB_NAME' at LSN (521452:7796:2) failed. …… Remote harden of transaction 'GhostCleanupTask' (ID 0x0000004f44ca4f41 0001:ea796d89) started at Aug 17 2025 3:36AM in database 'DB_NAME' at LSN (521452:8261:3) failed.
03:36:15.590 : DB_02 > DB_ 01방향의 Connection Timeout계속 발생
Aconnection timeout has occurred while attempting to establish a connection to availability replica ' DB_ 01'with id [82A59128-5DE5-45B0-9D84-0A3B2E3DCBCD]. Either a networking or firewall issue exists, or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance.
03:36:27.410 : DB_ 01 Node가 Primary_Normal로 복귀
The state of the local availability replica in availability group'DB_AVG' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'. The state changed because the local replica has completed processing Online command from Windows Server Failover Clustering (WSFC). ...... ......
03:36:39.650 : DB_ 01 Node와 재연결 확인
Always On Availability Groups connection withprimary database established for secondary database 'DB_NAME' on the availability replica ' DB_ 01'with Replica ID: {82a59128-5de5-45b0-9d84-0a3b2e3dcbcd}. This is an informational message only. No user action is required.
03:40:50.570 : DB_ 02 Node가 Resolving_Normal로 복귀
The state of the local availability replica in availability group'DB_AVG' has changed from 'RESOLVING_PENDING_FAILOVER' to 'RESOLVING_NORMAL'. The state changed because of a user initiated failover. ...... ......
03:40:50.600 : DB_ 02 Node가 Secondary_Normal로 복귀
The state of the local availability replica in availability group'DB_AVG' has changed from 'RESOLVING_NORMAL' to 'SECONDARY_NORMAL'. The state changed because the availability group state has changed in Windows Server Failover Clustering (WSFC). ...... ......
원인
-SQL Login [NT Authority\System]의 필수 권한 누락 이슈 확인
ü[NT AUTHORITY\SYSTEM]사용자에 대해 “ALTER ANY AVAILABILITY GROUP” 권한 및 “VIEW SERVER STATE” 권한이 누락된 경우, 고객환경과 동일하게 “Failover를 받는 기존Secondary Replica”에서 “기존의Primary Replica“ 방향의Connection Timeout오류가 재현 되었습니다.
“VIEW SERVER STATE” 누락 시–EXEC sp_server_diagnostics실행 실패로 인한Failover실패 확인
“ALTER ANY AVAILABILITY GROUP” 누락 시–EXEC sp_availability_group_command_internal실행 실패로 인한Failover실패 확인
ü고객환경의Cluster Log를 통해, Failover실패구간을 포함한 전체 구간에서 “VIEW SERVER STATE” 권한 누락으로 인해'EXEC sp_server_diagnostics 10'명령이 반복적으로 실패하는 것을 확인할 수 있었으므로, [NT AUTHORITY\SYSTEM]사용자에 대한 권한 누락은Failover실패 상황에 대한 원인으로 확인 되는 점 안내 드립니다.
…… [Verbose] 000024e4.00000b10::2025/08/17-03:35:54.663 INFO [RES] SQL Server Availability Group: [hadrag] Connect to SQL Server ... [Verbose] 000024e4.00000b10::2025/08/17-03:35:54.665 INFO [RES] SQL Server Availability Group: [hadrag] The connection was established successfully [Verbose] 000024e4.00000b10::2025/08/17-03:35:54.666 INFO [RES] SQL Server Availability Group: [hadrag] Run 'EXEC sp_server_diagnostics 10' returns following information [Verbose] 000024e4.00000b10::2025/08/17-03:35:54.666 ERR [RES] SQL Server Availability Group: [hadrag]ODBC Error: [42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]The user does not have permission to perform this action. (297) [Verbose] 000024e4.00000b10::2025/08/17-03:35:54.666 ERR [RES] SQL Server Availability Group: [hadrag] Failed to run diagnostics command. See previous log for error message [Verbose] 000024e4.00000b10::2025/08/17-03:35:54.666 INFO [RES] SQL Server Availability Group: [hadrag] Disconnect from SQL Server ……
[Resolution]
[NT AUTHORITY\SYSTEM]사용자의 누락된 권한 추가(적용 완료)
-Failover실패 상황을 예방하기 위해, SQL Server Always on Availability group구성된 모든 서버에서[NT AUTHORITY\SYSTEM] SQL Login에 대해 다음의 권한을 부여하여 주십시오.
다음3개의 권한은SQL Server의Default권한으로,해당 권한이 누락될 경우OS와의Interaction이 필요한 상황에서SQL Server의 정상 동작을 보장받지 못할 수 있습니다.
USE[master] GO GRANTALTERANYAVAILABILITYGROUPTO[NT AUTHORITY\SYSTEM] GO GRANTCONNECTSQLTO[NT AUTHORITY\SYSTEM] GO GRANTVIEWSERVERSTATETO[NT AUTHORITY\SYSTEM] GO
NT SERVICE\MSSQLSERVER사용자의Sysadmin권한 부여(적용 완료)
-엔지니어의 환경에서 테스트 시 서비스 가상계정의sysadmin권한이Failover실패에 직접적인 영향을 미치지는 않는 것으로 보이며,
해당 권한의 누락이SQL Server의 일상적인 운영에 큰 영향을 주지는 않으나,해당 권한은SQL Server설치시 부여되는Default권한으로 제거 시 예기치 못한 영향을 발생시킬 수 있어,가급적 동 권한을 모든 노드에도 추가하실 것을SQL Server설정에 대한Best Practice로서 권장 드립니다.
ALTERSERVERROLE[sysadmin]ADDMEMBER[NT Service\MSSQLSERVER] GO
SQL Server Audit구성을 통한Server/Data Principal의 변경사항 기록
-SQL Server의Server Audit을 구성하여 다음과 같이Server/Data Principal에 대한 변경이력을 수집/조회 할 수 있습니다.
-다음은Server/Database Principal에 대한Role, Permission에 대한 작업을 차단하는DDL Trigger의 예제입니다.
해당 예제를 참고하고,필요한DDL이벤트를 추가/제거하여 고객환경에서 허가받지 않은 작업을 차단하는DDL Trigger를 활용하실 수 있을 것으로 의견 드립니다.
--Trigger생성예제 CREATETRIGGERSRTI__PreventPermissionChangeONALLSERVER FORREVOKE_DATABASE,GRANT_DATABASE,DENY_DATABASE , REVOKE_SERVER ,GRANT_SERVER ,DENY_SERVER , CREATE_ROLE,DROP_ROLE,ALTER_ROLE , CREATE_USER,DROP_USER,ALTER_USER , ADD_ROLE_MEMBER ,DROP_ROLE_MEMBER , ADD_SERVER_ROLE_MEMBER,DROP_SERVER_ROLE_MEMBER AS BEGIN PRINT'!!! Change permission is now allowed !!!'; ROLLBACK; END; GO --Trigger가Enable된상태에서Grant시도 GRANTALTERANYAVAILABILITYGROUPTO[NT AUTHORITY\SYSTEM] GO
--Maintenance수행시Trigger를잠시Disable하고권한변경을수행 DISABLETRIGGERSRTI__PreventPermissionChangeONALLSERVER GO GRANTALTERANYAVAILABILITYGROUPTO[NT AUTHORITY\SYSTEM] GO ENABLETRIGGERSRTI__PreventPermissionChangeONALLSERVER GO
[추가 안내사항]
하기 내용은 본 문의 건을 지원 드리는 과정에서 문의주신 추가 안내사항을 취합/정리한 내용입니다.
DB서비스 계정에서sysadmin권한이 누락 되었을 때Fail over와 관련이 있을까요(lchdgqms01, lchdgqms02노드 둘다 권한이 없었습니다.현재는sysadmin권한 부여된 상태 입니다.)
-엔지니어의 테스트 환경에서 테스트 시,기 구성된Always on Availability group에 대해SQL Server서비스 계정및서비스 가상 계정에 대해Sysadmin권한이 누락되었다고 하여Failover에 직접적인 영향을 주지는 않는 것으로 확인 됩니다.
다만 이는 엔지니어의 테스트 환경에 제한된 사항이며,SQL Server서비스 가상계정에 대한sysadmin권한은 필수사항으로 누락 시 정상적인Failover를 보장하지 않습니다.
-서비스 계정에 대한 직접적인Sysadmin의 부여가 필수 권한은 아닙니다만,서비스계정의 운영상 편의를 위해Sysadmin권한을 부여하는 경우가 많습니다. 참고로SQL Server Service가상 계정에 대한Sysadmin은 필수 권한입니다.
-아래와 같이SQL Server를 설치한 직후 기본 권한을 확인 시,테스트환경의 서비스 가상 계정인 ”NT SERVICE\MSSQL$MSSQLSERVER2'”만Sysadmin을 보유하고 있으며, SQL Server시작 계정인 “CONTOSO\SQLAdmin”는 아무런 권한도 보유하고 있지 않은 상태(아직 로그인이 생성되지 않음)임을 확인할 수 있습니다.
로컬Administrators그룹에서DB서비스 계정이 누락 되었을 때Fail over실패와 관련이 있을까요 (lchdgqms01, lchdgqms02두 서버 누락된 상태 였습니다.현재는 서비스 계정이 추가되었습니다.)
-SQL Server서비스계정에 대한Local Administrator권한 또한 일반적으로 운영상 편의를 위해 부여하는 권한으로, SQL Server Always on Availability group의Failover실패와 직접적인 연관이 없어야 합니다.
다른 엔지니어분이 전달 주신 권한 관련 쿼리 입니다.해당 쿼리가Fail over실패와 관련이 있을까요
GRANT ALTER ANY AVAILABILITY GROUP TO [NT AUTHORITY\SYSTEM] GO GRANT CONNECT SQL TO [NT AUTHORITY\SYSTEM] GO GRANT VIEW SERVER STATE TO [NT AUTHORITY\SYSTEM] GO
-네,해당 권한은Windows Server Failover Cluster가SQL Server Always on Availability group을 핸들링 하기 위한 최소 권한입니다.
각각“ALTER ANY AVAILABILITY GROUP” 권한은AG의 컨트롤,“CONNECT SQL”권한은 쿼리 실행,“VIEW SERVER STATE”은 서버 상태 확인을 위한sp_server_diagnostics실행을 위한필수 권한입니다.
-테스트환경에서[NT AUTHORITY\SYSTEM]에 대한ALTER ANY AVAILABILITY GROUP권한 제거 후 테스트 수행 시,고객 환경에서 발생하였던 동일 오류가 동일하게 재연되는것으로 확인됩니다.
#테스트환경의Secondary에서REVOKE ALTER ANY AVAILABILITY GROUP TO [NT AUTHORITY\SYSTEM]수행 후Failover Test시 고객 오류 재현 # W22SQL22-AG01 > W22SQL22-AG02로Failover시작 2025-08-18 09:34:55.500 spid75 The state of the local availabilityreplica in availability group 'W22SQL22-AG' has changed from 'SECONDARY_NORMAL' to 'RESOLVING_PENDING_FAILOVER'. The state changed because of a user initiated failover. …… # Failover과정에서W22SQL22-AG02 > W22SQL22-AG01방향의Timeout발생 2025-08-18 09:36:14.200 spid51s Aconnection timeout has occurred on a previously established connection to availability replica 'W22SQL22-AG01' with id [25700621-07A8-4D19-ACDB-4A43B5352199]. Either a networking or a firewall issue exists or the availability replica has transitioned to the resolving role. 2025-08-18 09:36:14.200 spid51s Always OnAvailability Groups connection with primary database terminated for secondary database 'OneDataFile' on the availability replica 'W22SQL22-AG01' with Replica ID: {25700621-07a8-4d19-acdb-4a43b5352199}. This is an informational message only. No user action is required. 2025-08-18 09:36:14.200 spid60s Always OnAvailability Groups connection with primary database terminated for secondary database 'AGDB01' on the availability replica 'W22SQL22-AG01' with Replica ID: {25700621-07a8-4d19-acdb-4a43b5352199}. This is an informational message only. No user action is required. 2025-08-18 09:36:24.200 spid51s Aconnection timeout has occurred while attempting to establish a connection to availability replica 'W22SQL22-AG01' with id [25700621-07A8-4D19-ACDB-4A43B5352199]. Either a networking or firewall issue exists, or the endpoint address provided for the replica is not the database mirroring endpoint of the host server instance. # Secondary(W22SQL22-AG02) <-> Primary(W22SQL22-AG01)간의TCP 5022통신 정상 확인
-참고로,해당 권한은 아래와 같이SQL Server설치 이후Default로 할당되는 권한임을 확인하실 수 있습니다.
-테스트를 통해SQL Server서비스계정에 대한OS의Administrators권한 제거와"NT AUTHORITY\SYSTEM"의 계정 권한 회수는 관계가 없는 것으로 확인하였습니다.
서버 역할에서 제외 시 권한 회수 여부(예:원래sysadmin이었는데 보안 강화로 제거)=>해당 작업은 권한 회수되지 않는 것으로 내부 테스트 완료했습니다만, 검토 요청 드립니다.
-ALTER ANY AVAILABILITY GROUP, CONNECT SQL및VIEW SERVER STATE권한은SQL Server설치시"NT AUTHORITY\SYSTEM"에 부여되는Default권한입니다.
단순sysadmin권한 회수로는"NT AUTHORITY\SYSTEM"의Default권한 회수가 일어나지 않는 것으로 확인하였습니다.
엔드포인트 권한 초기화 스크립트 적용시 권한 회수 여부
-단순Endpoint에 대한 권한 초기화는"NT AUTHORITY\SYSTEM"의Default권한 회수가 일어나지 않는 것으로 확인하였습니다.
보안 하드닝/감사 패키지가GRANT/REVOKE템플릿을 일괄 적용하면서 의도치 않게 회수. ->해당 작업을 할 수 있는 기능이 혹시DB기본기능으로 내장되어 있다면,점검 방법을 알려주시면 점검해보겠습니다.
-3rdparty tool에 대한 보안점검결과 반영 시 필수 권한이 회수되어 장애 발생으로 케이스가 생성되는 사례가 간혹 발생합니다.
이와 같은 경우, Server Audit을 구성하여 추적을 진행할 수 있습니다.
Server Audit과 관련하여서는 아래 본문에서 관련 안내 드리겠습니다.
혹시 추가로 다른 작업에 연계해서 변경이 될만한 부분이 있는지도 한번 체크 부탁드립니다.
-일반적으로 보안점검 지적사항 반영과 연계하여 권한 문제가 발생하는 것이 가장 자주 발생하는 이슈입니다.
또한 보안점검 지적사항으로 인해"NT AUTHORITY\SYSTEM"사용자를 삭제하였다가 다시 추가하면서 필수 권한을 추가하지 않아 문제가 발생하는 사례또한 함께 공유 드립니다.
저희가2022버전도 일부 운영을 하고 있는데 관련 내용을 검색하다보니 아래와 같은 내용도 확인을 했습니다. SQL 2022역시SQL 2012이후의 정책을 이어받아, SYSTEM계정보다는 서비스SID(NT SERVICE\<InstanceName>, NT SERVICE\SQLSERVERAGENT)를 권한 부여 대상으로 사용합니다.
2022버전에는NT AUTHORITY\SYSTEM계정이 아닌 별도의 계정을 사용하는지도 확인 요청 드립니다.
Windows Server Failover Cluster가SQL Server에 접근할 때, SQL Server 2022에서도 기존 버전과 마찬가지로 “NT AUTHORITY\SYSTEM”를 사용하는 것으로 확인 하였습니다.
Always-on Availability group(AG) 구성의 SQL Server에서 Primary replica가 병렬 Index Rebuild 수행 시 Secondary도 동일한 수량의 병렬 Index Rebuild를 수행하는지를 문의주신 건으로 이해됩니다.
AG의 데이터 동기화는 Primary Replica에서 발생한 Transaction log를 Secondary Replica에서 Redo하는 단계로 진행됩니다.
참고로 SQL Server 2016 이후 Parallel redo thread(Instance당 최대 100개, Database당 최대 16개)를 지원합니다.
다만, 이 Parallel redo thread의 개수는 Primary replica에서 Transaction log를 발생시킨 쿼리의 DoP와 관계 없이, 현재 Secondary replica에서 Transaction log를 Redo하는 부하 상황에 따라 달라지게 됩니다.
이 때문에, Primary replica에서 병렬 Index Rebuild 수행 시 Secondary replica에서 병렬로 Redo를 수행할 가능성은 높으나, Index Rebuild 상황을 Redo하는 Secondary Replica의 Redo Thread 개수는, 일반적으로 Primary replica의 Index Rebuild Thread 개수보다 적게 됩니다.
예를 들어 다음과 같이 테스트환경에서 약 10GB 크기의 테이블에 대해, MAXDOP 4의 병렬 Index Rebuild를 수행하여 Secondary Replica에서 Redo thread를 모니터링 하면, Primary Replica는 DoP 4로 Index Rebuild를 수행하고 있으나, 같은 시점의 Secondary Replica는 3개의 Redo thread로 Transaction을 Redo 하고 있음을 확인할 수 있습니다.
Case
Result
Test Scenario - 약 10GB 크기의 테이블에 Maxdop=4로 Index Rebuild를 수행
EXECsys.sp_spaceused'dbo.tbl_Index_ParallelBuild' GO
ALTERINDEX UCL__tbl_Index_ParallelBuild__01 ON dbo.tbl_Index_ParallelBuild REBUILDWITH (MAXDOP= 4) GO
Primary Replica - 첨부드리는 Monitor_IndexRebuild_ParallelRedo.sql 쿼리를 통해 74번 세션에서 수행중인 Index Rebuild 수행 상황을 모니터링 하면, 2개의 Consumer thread를 제외하고, 4개의 Thread로 Parallel Rebuild 수행중임을 확인할 수 있습니다.
Secondary Replica - 첨부드리는 Monitor_IndexRebuild_ParallelRedo.sql 쿼리를 통해 AG의 Redo 수행 상황을 모니터링 하면, AGDB01 데이터베이스에 대해 3개의 Parallel redo thread가 Index rebuild를 수행중임을 확인할 수 있습니다.
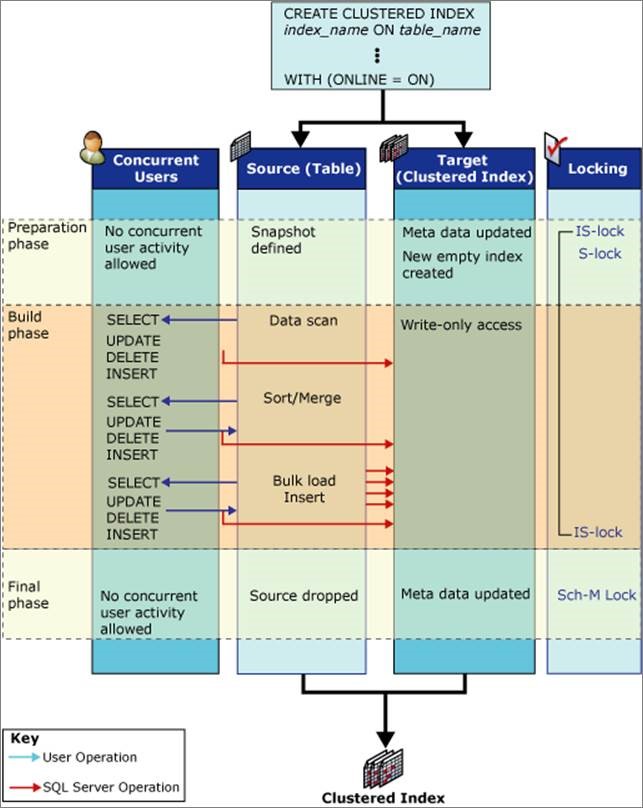
-System metadata preparation to create the new empty index structure. -A snapshot of the table is defined. That is, row versioning is used to provide transaction-level read consistency. -Concurrent user write operations on the source are blocked for a short period. No concurrent DDL operations are allowed except creating multiple nonclustered indexes.
-S (Shared) on the table* -IS (Intent Shared) -INDEX_BUILD_INTERNAL_RESOURCE**
Build : Main phase
-The data is scanned, sorted, merged, and inserted into the target in bulk load operations. -Concurrent user select, insert, update, and delete operations are applied to both the pre-existing indexes and any new indexes being built.
-IS -INDEX_BUILD_INTERNAL_RESOURCE**
Final : Short phase
-All uncommitted update transactions must complete before this phase starts. -Depending on the acquired lock, all new user read or write transactions are blocked for a short period until this phase is completed. -System metadata is updated to replace the source with the target. -The source is dropped if it is required. For example, after rebuilding or dropping a clustered index.
-INDEX_BUILD_INTERNAL_RESOURCE** -S on the table if creating a nonclustered index.* -SCH-M (Schema Modification) if any source structure (index or table) is dropped.*
-다음은 온라인 인덱싱 작업에 대한 일반적인 가이드라인입니다. Online Indexing 작업 중 발생할 수 있는 여러가지 이슈사항과 사전 고려사항을 정리하고 있으며, Update 부하가 높은 환경에서 Online Indexing 중, 종종 발생하는 Deadlock(자동으로 해소)과 같은 증상도 해당 문서를 통해 확인할 수 있습니다.
##SQL Version :Microsoft SQL Server 2019 (RTM-CU17) (KB5016394) - 15.0.4249.2 (X64)
확인사항]
먼저 DTC실패(Error: 8509)기록된후 Rollback하는 과정에서 Dump가 생성으며, 해당 이슈는 이미 알려진 이슈로 CU21에서 FIX가 되었습니다.
해당 Dump는 in-memory Table사용과정에서 발생할수있으며, 고객사같은 경우는 DTC Transaction이 Rollback 되는 과정에서 해당 known issue로 인한 Dump가 생성었고 이로인한 가용성그룹이 Resolving상태로 빠지게됩니다.
이후 Leasetime out이 발생하나 FailureConditionLevel(2)로 Failover가 자동적으로 Triggered되지 않았습니다.
#ErrorLog.2 2024-04-02 14:01:03.93 spid62 Error: 8509, Severity: 16, State: 1. 2024-04-02 14:01:03.93 spid62 Import of Microsoft Distributed Transaction Coordinator (MS DTC) transaction failed: 0x8004d00e(XACT_E_NOTRANSACTION). 2024-04-02 14:01:35.11 spid156 Error: 8509, Severity: 16, State: 1. 2024-04-02 14:01:35.11 spid156 Import of Microsoft Distributed Transaction Coordinator (MS DTC) transaction failed: 0x8004d00e(XACT_E_NOTRANSACTION). 2024-04-02 14:02:01.15 spid853 Error: 8509, Severity: 16, State: 1. 2024-04-02 14:02:01.15 spid853 Import of Microsoft Distributed Transaction Coordinator (MS DTC) transaction failed: 0x8004d00e(XACT_E_NOTRANSACTION). 2024-04-02 14:02:35.74 spid35s CImageHelper::Init () Version-specific dbghelp.dll is not used 2024-04-02 14:02:35.74 spid35s Using 'dbghelp.dll' version '4.0.5' 2024-04-02 14:02:35.75 spid35s **Dump thread - spid = 0, EC = 0x0000020BD57C1E10 ..중략.. 2024-04-02 14:02:35.75 spid35s ***Stack Dump being sent to \SQLDump0017.txt 2024-04-02 14:02:35.75 spid35s * ******************************************************************************* 2024-04-02 14:02:35.75 spid35s * 2024-04-02 14:02:35.75 spid35s * BEGIN STACK DUMP: 2024-04-02 14:02:35.75 spid35s * 04/02/24 14:02:35 spid 35 2024-04-02 14:02:35.75 spid35s * 2024-04-02 14:02:35.75 spid35s * Location: "sql\\ntdbms\\hekaton\\engine\\core\\tx.cpp":6337 2024-04-02 14:02:35.75 spid35s * Expression: Dependencies.CommitDepCountOut >= 1 2024-04-02 14:02:35.75 spid35s * SPID: 35 2024-04-02 14:02:35.75 spid35s * Process ID: 5652 2024-04-02 14:03:23.88 spid35s Timeout waiting for external dump process 21796. 2024-04-02 14:03:23.88 spid35s Error: 17066, Severity: 16, State: 1. 2024-04-02 14:03:23.88 spid35s SQL Server Assertion: File: <"sql\\ntdbms\\hekaton\\engine\\core\\tx.cpp">, line=6337 Failed Assertion = 'Dependencies.CommitDepCountOut >= 1'. This error may be timing-related. If the error persists after rerunning the statement, use DBCC CHECKDB to check the database for structural integrity, or restart the server to ensure in-memory data structures are not corrupted. ..중략.. 2024-04-02 14:03:23.88 Server The state of the local availability replica in availability group 'L_AVG' has changed from 'PRIMARY_NORMAL' to 'RESOLVING_NORMAL'. The state changed because the lease between the local availability replica and Windows Server Failover Clustering (WSFC) has expired. For more information, see the SQL Server error log or cluster log. If this is a Windows Server Failover Clustering (WSFC) availability group, you can also see the WSFC management console. 2024-04-02 14:03:23.88 spid189s The availability group database "DATABASE_P03" is changing roles from "PRIMARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required. 2024-04-02 14:03:23.88 spid325s The availability group database " DATABASE_03 _IF" is changing roles from "PRIMARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required. 2024-04-02 14:03:23.88 spid851s The availability group database " DATABASE_03_HMI_2" is changing roles from "PRIMARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required. 2024-04-02 14:03:23.88 spid849s The availability group database " DATABASE_03_P03" is changing roles from "PRIMARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required. #ClusterLog 00002c40.00003588::2024/04/02-14:02:40.450 INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'clean' to 'warning' at 2024-04-02 14:02:40.447 00002c40.00003588::2024/04/02-14:02:40.453 INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'query_processing' health state has been changed from 'clean' to 'warning' at 2024-04-02 14:02:40.447 00002c40.00000844::2024/04/02-14:02:57.490 ERR [RES] SQL Server Availability Group <L_AVG>: [hadrag] Lease renewal failed with timeout error 00002c40.00000844::2024/04/02-14:02:57.490 ERR [RES] SQL Server Availability Group <L_AVG>: [hadrag] The lease is expired. The lease should have been renewed by 2024/04/02-12:02:47.490 00002c40.00003858::2024/04/02-14:02:58.046 ERR [RES] SQL Server Availability Group <L_AVG>: [hadrag] Availability Group lease is no longer valid 00002c40.00003858::2024/04/02-14:02:58.046 ERR [RES] SQL Server Availability Group <L_AVG>: [hadrag] Resource Alive result 0. 00002c40.00003858::2024/04/02-14:02:58.046 ERR [RES] SQL Server Availability Group <L_AVG>: [hadrag] Availability Group lease is no longer valid 00002c40.00003858::2024/04/02-14:02:58.046 ERR [RES] SQL Server Availability Group <L_AVG>: [hadrag] Resource Alive result 0. 00002c40.00003858::2024/04/02-14:02:58.046 WARN [RHS] Resource L_AVG IsAlive has indicated failure. 00001cec.00002838::2024/04/02-14:02:58.046 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'L_AVG', gen(0) result 1/0. 00002c40.00003858::2024/04/02-14:02:58.046 INFO [RHS-WER] Scheduling WER ERROR report in 10.000. ReportId 2f1efff4-5677-4f46-8c8c-9162e4c155db; 00001cec.00002838::2024/04/02-14:02:58.046 INFO [RCM] Res L_AVG: Online -> ProcessingFailure( StateUnknown ) 00001cec.00002838::2024/04/02-14:02:58.046 INFO [RCM] TransitionToState(L_AVG) Online-->ProcessingFailure.
해당 이슈가 Failover를 Trigger하는 부차적인 이슈가 있으며, 이로인한 failover를 반복적으로 수행되나 해당 역할을 Online시키지 못함에 따라 반복적으로 dump로 인한 failover가 수행되었습니다.
이과정에서 large transaction rollback및 반복적인 failover시도로인한 DB연결이슈(983)가 발생한 것으로 확인하였습니다.
2024/04/02-14:03:23.916 INFO [RCM] rcm::RcmApi::MoveGroup: (Group:L_AVG Dest:1 Flags:0 MoveType:MoveType::ManualCur.State:Pending, ContextSize:0) 2024/04/02-14:03:23.917 ERR [RCM] rcm::RcmApi::OnlineResource: (5023)' because of 'The API call is not valid while resource is in the [Terminating to DelayRestartingResource] state.'
2024-04-02 14:03:23.93 spid725s Error: 3624, Severity: 20, State: 1. 2024-04-02 14:03:23.93 spid725s A system assertion check has failed. Check the SQL Server error log for details. Typically, an assertion failure is caused by a software bug or data corruption. To check for database corruption, consider running DBCC CHECKDB. If you agreed to send dumps to Microsoft during setup, a mini dump will be sent to Microsoft. An update might be available from Microsoft in the latest Service Pack or in a Hotfix from Technical Support. 2024-04-02 14:03:23.93 spid725s Error: 3314, Severity: 21, State: 3. 2024-04-02 14:03:23.93 spid725s During undoing of a logged operation in database 'tempdb' (page (1:139) if any), an error occurred at log record ID (17626:408077:603). Typically, the specific failure is logged previously as an error in the operating system error log. Restore the database or file from a backup, or repair the database. ..중략.. 2024-04-02 14:04:22.71 Logon Error: 983, Severity: 14, State: 1. 2024-04-02 14:04:22.71 Logon Unable to access availability database 'DATABASE_P03' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later. 2024-04-02 14:04:30.07 spid189s Nonqualified transactions are being rolled back in database DATABASE_P03 for an Always On Availability Groups state change. Estimated rollback completion: 0%. This is an informational message only. No user action is required. 2024-04-02 14:04:32.07 spid189s Nonqualified transactions are being rolled back in database DATABASE_P03 for an Always On Availability Groups state change. Estimated rollback completion: 0%. This is an informational message only. No user action is required. 2024-04-02 14:04:32.99 spid653s Remote harden of transaction 'GhostCleanupTask' (ID 0x00000072638fd8cd 0001:3a728b14) started at Apr 2 2024 2:04PM in database 'DATABASE_P03' at LSN (170966:295662:202) failed. 2024-04-02 14:04:33.67 spid325s Attempting to recover in-doubt distributed transactions involving Microsoft Distributed Transaction Coordinator (MS DTC). This is an informational message only. No user action is required. 2024-04-02 14:04:33.67 spid37s Always On: DebugTraceVarArgs AR '[HADR] [Primary] operation on replicas [5777243E-1C2F-4399-8B8F-8F006F9FD4EE]->[CFF305E1-8C94-4DB3-85D7-0EDD5502E88E], database [DATABASE_P03_IF], remote endpoint [TCP://LES.es.net:5022], source operation [8909B701-63D0-4C65-BE06-CE7BC04DD049]: Transitioning from [CATCHUP] to [COMPLETED].' 2024-04-02 14:04:33.67 spid46s Always On: DebugTraceVarArgs AR '[HADR] [Primary] operation on replicas [5777243E-1C2F-4399-8B8F-8F006F9FD4EE]->[7ED01BC6-97DF-41C4-84E9-737FE70CB40B], database [DATABASE_P03_IF], remote endpoint [TCP://LES.es.net:5022], source operation [79597AD0-EB94-4E28-ACC6-0E791C5BB0E0]: Transitioning from [CATCHUP] to [COMPLETED].' 2024-04-02 14:04:33.67 spid974s [DbMgrPartnerCommitPolicy::SetReplicaInfoInAg] DbMgrPartnerCommitPolicy::SetSyncAndRecoveryPoint: CFF305E1-8C94-4DB3-85D7-0EDD5502E88E:10:4 2024-04-02 14:04:34.07 spid189s Nonqualified transactions are being rolled back in database DATABASE_P03 for an Always On Availability Groups state change. Estimated rollback completion: 0%. This is an informational message only. No user action is required.
이후 고객사에서 LES Server재시작(2024-04-02 14:49)이후 정상적으로 'DATABASE_P03' Online되며 AG가 정상적으로 Online되었습니다.
2024-04-02 14:49:51.76 Server SQL Server is terminating because of a system shutdown. This is an informational message only. No user action is required. 2024-04-02 15:00:39.69 spid46s Always On Availability Groups connection with secondary database established for primary database 'DATABASE_P03' on the availability replica 'LES2' with Replica ID: {cff305e1-8c94-4db3-85d7-0edd5502e88e}. This is an informational message only. No user action is required. 2024-04-02 15:00:39.81 spid139s Always On Availability Groups connection with secondary database established for primary database 'DATABASE_P03' on the availability replica 'LES2' with Replica ID: {cff305e1-8c94-4db3-85d7-0edd5502e88e}. This is an informational message only. No user action is required. 2024-04-02 15:00:52.81 spid79s Always On: DebugTraceVarArgs AR '[HADR] [Primary] operation on replicas [5777243E-1C2F-4399-8B8F-8F006F9FD4EE]->[CFF305E1-8C94-4DB3-85D7-0EDD5502E88E], database [DATABASE_P03], remote endpoint [TCP://LES2.es.net:5022], source operation [719D2611-5566-404F-A02F-B08684AE5A07]: Transitioning from [CATCHUP] to [COMPLETED].' 2024-04-02 15:00:57.02 spid46s [DbMgrPartnerCommitPolicy::SetReplicaInfoInAg] DbMgrPartnerCommitPolicy::SetSyncAndRecoveryPoint: CFF305E1-8C94-4DB3-85D7-0EDD5502E88E:11:4 2024-04-02 15:00:57.02 spid46s DbMgrPartnerCommitPolicy::SetSyncState: CFF305E1-8C94-4DB3-85D7-0EDD5502E88E:11:4
[제안사항]
해당 이슈는 CU21에서 FIX되었으며, 최소 CU21로 patch하시는 것을 제안드립니다.
일반적으로 백업은 DML을 blocking 하지 않으나 백업이 진행중일 때는 database/file을 shrink 할 수 없으며,
Primary에서 Log shrink 를 진행해도 Secondary에도 적용이 되기 때문에 위와 같은 Lock wait이 발생하게 됩니다.
Limitations and restrictions
The database can't be made smaller than the minimum size of the database. The minimum size is the size specified when the database was originally created, or the last explicit size set by using a file-size-changing operation, such as DBCC SHRINKFILE. For example, if a database was originally created with a size of 10 MB and grew to 100 MB, the smallest size the database could be reduced to is 10 MB, even if all the data in the database has been deleted. You can't shrink a database while the database is being backed up. Conversely, you can't back up a database while a shrink operation on the database is in process. You cannot shrink files while database Backups are happening. You might also notice that these commands encounter a wait_type = LCK_M_U and a wait_resource = DATABASE: <id> [BULKOP_BACKUP_DB] when the status of these commands is viewed from the various dynamic management views (DMVs), such as from sys.dm_exec_requests or sys.dm_os_waiting_tasks.