동적 데이터 마스킹 (DDM)SQL Server 2016에 추가 된 유용한 기능입니다. DDM을 사용하면 인증되지 않은 사용자의 민감한 데이터를 숨길 수 있습니다. 가장 중요한 것은 데이터 마스킹과 암호화는 데이터를 보호하는 두 가지 방법입니다. 동적 데이터 마스킹은 여러 가지 전략을 사용하여 데이터를 숨 깁니다. SQL Server에서 저장된 데이터를 암호화 기능으로 수정하지 않으면 도움이됩니다.
다이내믹 데이터 마스킹은 헬스 케어, 뱅킹 도메인에서 광범위하게 사용되어 권한이없는 엔티티의 데이터 기밀성을 유지하기위한 엄격한 조치를 취할 수 있습니다. DDM을 통해 우리는 응용 프로그램 코드 및 쿼리를 수정하지 않고 기존 저장된 데이터를 보호.
사례 연구로서 개발자는신원, 연락처, 신용 카드 번호 및 재무 기록과 같은 고객의 건강 및 은행 기록이있는 생산 데이터에 노출됩니다. 타사 영업 담당자는 자신의 제품을 마케팅하는 데 사용할 수있는 고객의 보험 내역을 알고 있어야합니다.
따라서 동적 데이터 마스킹은 기밀 데이터를 일반 텍스트 형식으로 무단 사용자에게 노출하는 것을 제한 읽기 권한이 있어도.
마스킹 기능을 테스트 할 새 사용자 작성
동적 데이터 마스킹 쿼리를 진행하기 전에. 우리는 새로운 사용자를 만들 것입니다 MaskedTestUser 갖는 것 고르다 아래에 생성 된 테이블에 대한 권한 dbo 사용자. 마스크 된 열 기능을 사용하여 dbo 사용자 아래에 테이블을 만들고 MaskedTestUser를 사용하여 쿼리하여 마스크 된 데이터를 봅니다. MaskedTestUser는 실제 데이터에 액세스 할 수없는 권한이없는 사용자라고 가정합니다.
DROP USER IF EXISTS MaskedTestUser;
CREATE USER MaskedTestUser WITHOUT LOGIN;
SQL Server에서 마스킹 기능 및 지원되는 데이터 형식
SQL Server는 서로 다른 네 가지를 통합했습니다민감한 데이터를 마스크하는 기능. XML, varbinary 및 hierarchyid와 같은 일부 특수 데이터 유형과 함께 문자열, 숫자 및 날짜와 같은 가능한 모든 데이터 유형과 작동하도록 설계되었습니다.

기능과 사용법을 이해하기 위해 각각을 살펴 보겠습니다.
1. 태만
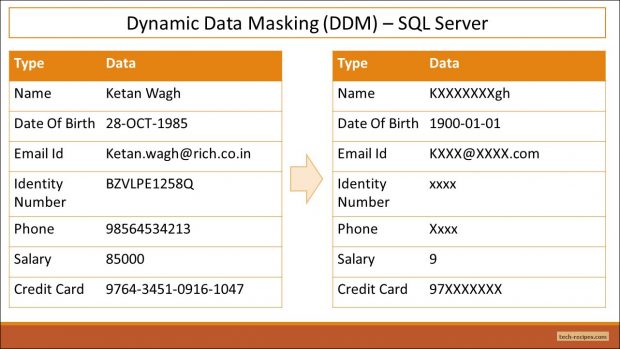
데이터의 전체 마스킹 기본 마스킹 기능을 사용하여 달성 할 수 있습니다. 가능한 모든 데이터 유형과 호환 SQL Server에서. 마스크 된 데이터는 마스크 된 열의 데이터 유형에 따라 표시됩니다. 문자열 데이터 유형은 IdentityNumber 및 Phone 열과 같은 XXXX 문자를 사용하여 표시됩니다. 숫자 데이터 유형은 0으로 표시됩니다. 날짜는 DateOfBirth 열과 같은 기본 날짜 '1900-01-01'로 표시됩니다.
데모 목적으로 샘플 데이터를 마스킹 열로 채 웁니다.
DROP TABLE IF EXISTS DefaultMaskTest;
CREATE TABLE DefaultMaskTest
(
ID INT IDENTITY (1,1) PRIMARY KEY NOT NULL
,DefaultMask_Varchar VARCHAR(255) MASKED WITH (FUNCTION = 'default()') NULL
,DefaultMask_Char CHAR(1) MASKED WITH (FUNCTION = 'default()') NOT NULL
,DefaultMask_Bit BIT MASKED WITH (FUNCTION = 'default()') NOT NULL
,DefaultMask_Date DATE MASKED WITH (FUNCTION = 'default()') NOT NULL
,DefaultMask_DateTime DATETIME MASKED WITH (FUNCTION = 'default()') NOT NULL
,DefaultMask_Time TIME MASKED WITH (FUNCTION = 'default()') NOT NULL
,DefaultMask_Integer BIGINT MASKED WITH (FUNCTION = 'default()') NOT NULL
,DefaultMask_Decimal DECIMAL(9,2) MASKED WITH (FUNCTION = 'default()') NOT NULL
,DefaultMask_XML XML MASKED WITH (FUNCTION = 'default()') NOT NULL
);
GO
INSERT INTO DefaultMaskTest
(
DefaultMask_Varchar, DefaultMask_Char, DefaultMask_Bit, DefaultMask_Date, DefaultMask_DateTime, DefaultMask_Time
, DefaultMask_Integer, DefaultMask_Decimal, DefaultMask_XML
)
VALUES
(
'Chetan Sharma', 'M', 1, '2020-06-12', '2021-06-12 12:23:32:543', '08:12:46:342'
, 5282991, 45628.39,'<root>Tech-Recipes</root>'
);
다음 쿼리는 MaskedTestUser 및 dbo 사용자에게 마스크 된 데이터가 표시되는 방법을 보여줍니다.
--Drop & Create User - MaskedTestUser
DROP USER IF EXISTS MaskedTestUser;
CREATE USER MaskedTestUser WITHOUT LOGIN;
--Query table using dbo user
SELECT * FROM DefaultMaskTest;
--Grant SELECT permission to MaskedTestUser
GRANT SELECT ON DefaultMaskTest TO MaskedTestUser;
--Query table using MaskedTestUser
EXECUTE AS USER = 'MaskedTestUser';
SELECT * FROM DefaultMaskTest;
--Revert user impersonation to dbo user
REVERT;

2.부분
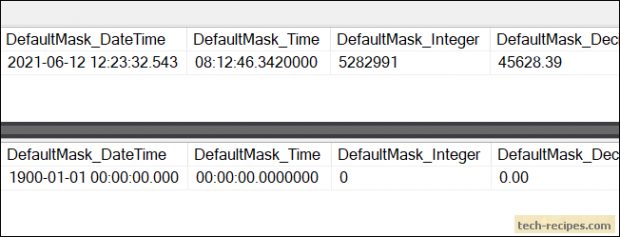
부분 기능 문자열 데이터 유형에서만 작동. 데이터의 부분 마스킹에 문자가 거의 없음문자열의 시작 또는 끝에서 기본 'XXXX'문자를 사용하는 대신 맞춤 문자열을 사이에 삽입 할 수 있습니다. 위의 예에서 CreditCard 열은 partial (2,“XXXXXXX”, 0) 방법을 사용하여 마스킹되어 처음 두 문자 만 표시하고 사용자 정의 가능한 X 문자를 추가합니다.
데모 목적으로 샘플 데이터를 마스킹 열로 채 웁니다.
DROP TABLE IF EXISTS PartialMaskTest;
CREATE TABLE PartialMaskTest
(
ID INT IDENTITY(1,1) PRIMARY KEY NOT NULL
,PartialMask_Varchar VARCHAR(255) MASKED WITH (FUNCTION = 'partial(1, "XXXX",1)') NOT NULL
,PartialMask_Nvarchar NVARCHAR(255)MASKED WITH (FUNCTION = 'partial(2, "ABCDEFG",3)') NOT NULL
);
GO
INSERT INTO PartialMaskTest
(
PartialMask_Varchar
,PartialMask_Nvarchar
)
VALUES
(
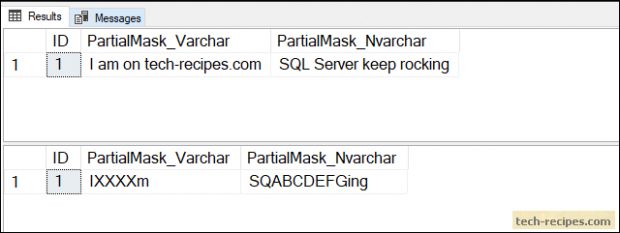
'I am on tech-recipes.com'
,'SQL Server keep rocking'
);
다음 쿼리는 MaskedTestUser 및 dbo 사용자에게 마스크 된 데이터가 표시되는 방법을 보여줍니다.
--Drop & Create User - MaskedTestUser
DROP USER IF EXISTS MaskedTestUser;
CREATE USER MaskedTestUser WITHOUT LOGIN;
--Query table using dbo (owner) user
SELECT * FROM PartialMaskTest;
--Grant SELECT permission to MaskedTestUser
GRANT SELECT ON PartialMaskTest TO MaskedTestUser;
--Query table using MaskedTestUser
EXECUTE AS USER = 'MaskedTestUser';
SELECT * FROM PartialMaskTest;
--Revert user impersonation to dbo user
REVERT;
3.이메일
이메일, 중요한 기능을 고려하여 이메일 ID를 마스킹하는 특정 기능인 이메일. 이메일 기능은 문자열 데이터 유형에서만 작동합니다. 에 이메일 ID 및 도메인 이름 마스킹 ‘[이메일 보호]’ 첫 문자를 그대로 유지하고 도메인 이름을 .COM으로 변경합니다. 고객 테이블의 EmailId 열이에서 마스크되었습니다. [이메일 보호] 에 [이메일 보호]. 부분 기능조차도 이메일 기능 사용을 다음과 같이 복제 할 수 있습니다 부분적 (1, '[이메일 보호]’, 0).
이메일 기능이 작동하는지 확인하기 위해 샘플 데이터를 마스킹 열로 채 웁니다.
DROP TABLE IF EXISTS EmailMaskTest;
CREATE TABLE EmailMaskTest
(
ID INT IDENTITY (1,1) PRIMARY KEY NOT NULL
,EmailMask VARCHAR(255) MASKED WITH (FUNCTION = 'email()') NOT NULL
);
GO
INSERT INTO EmailMaskTest
(
EmailMask
)
VALUES ('[email protected]'),
('[email protected]'),
('[email protected]');
다음 쿼리는 MaskedTestUser 및 dbo 사용자에게 마스크 된 데이터가 표시되는 방법을 보여줍니다.
--Drop & Create User - MaskedTestUser
DROP USER IF EXISTS MaskedTestUser;
CREATE USER MaskedTestUser WITHOUT LOGIN;
--Query table using dbo (owner) user
SELECT * FROM EmailMaskTest;
--Grant SELECT permission to MaskedTestUser
GRANT SELECT ON EmailMaskTest TO MaskedTestUser;
--Query table using MaskedTestUser
EXECUTE AS USER = 'MaskedTestUser';
SELECT * FROM EmailMaskTest;
--Revert user impersonation to dbo user
REVERT;

4.무작위
마스킹 숫자 데이터 유형 열 원래 값에 난수를 사용합니다. 정의 된 범위 사이에서 난수를 생성 할 수 있습니다. 고객 테이블의 급여 열이 랜덤 (1,10) – 1에서 10 사이의 난수 만 생성합니다. 우리는 다음을 사용하여 소수 범위를 정의 할 수 있습니다 무작위 (0.1,0.75).
DROP TABLE IF EXISTS RandomMaskTest;
CREATE TABLE RandomMaskTest
(
ID INT IDENTITY (1,1) PRIMARY KEY NOT NULL
,RandomMask_INT INT MASKED WITH (FUNCTION = 'random(1,999)') NOT NULL
,RandomMask_BIGINT BIGINT MASKED WITH (FUNCTION = 'random(1000,2000)') NOT NULL
,RandomMask_DECIMAL DECIMAL(9,2) MASKED WITH (FUNCTION = 'random(1.1,10.5)') NOT NULL
);
GO
INSERT INTO RandomMaskTest
(
RandomMask_INT
,RandomMask_BIGINT
,RandomMask_DECIMAL
)
VALUES
(33405691, 401204193524, 311531.56);
다음 쿼리는 MaskedTestUser 및 dbo 사용자에게 마스크 된 데이터가 표시되는 방법을 보여줍니다.
--Drop & Create User - MaskedTestUser
DROP USER IF EXISTS MaskedTestUser;
CREATE USER MaskedTestUser WITHOUT LOGIN;
--Query table using dbo (owner) user
SELECT * FROM RandomMaskTest;
--Grant SELECT permission to MaskedTestUser
GRANT SELECT ON RandomMaskTest TO MaskedTestUser;
--Query table using MaskedTestUser
EXECUTE AS USER = 'MaskedTestUser';
SELECT * FROM RandomMaskTest;
--Revert user impersonation to dbo user
REVERT;

마스킹 기능 및 데이터 유형 호환성
마스킹 기능은 지원되는 데이터와 작동유형 만. 호환되지 않는 데이터 형식으로 마스킹 기능을 사용하려고하면 SQL Server에서 다음 오류가 발생합니다. 문자 데이터 유형에 임의의 함수를 사용하려고 할 때. 임의 함수는 숫자 데이터 유형과 만 호환됩니다.
16003 메시지, 수준 16, 상태 0, 줄 21열 'IdentityNumber'의 데이터 유형은 데이터 마스킹 기능 'random'을 지원하지 않습니다.</br>
데이터베이스에서 마스크 된 열 쿼리
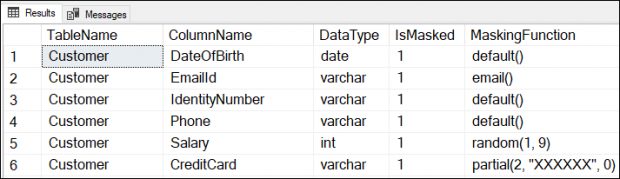
추가 sys.masked_columns 뷰는 데이터베이스의 모든 마스크 열을 포함합니다. 이를 사용하여 마스크 된 열 이름, 마스킹 기능 및 관련 테이블 이름을 쿼리 할 수 있습니다.
SELECT OBJECT_NAME(mc.object_id) as TableName
,mc.name as ColumnName
,TYPE_NAME(system_type_id) as DataType
,mc.is_masked as IsMasked
,mc.masking_function as MaskingFunction
FROM sys.masked_columns as mc
WHERE mc.is_masked = 1;
테이블 문을 만들기 위해 다중 마스킹 기능 추가
우리는 이미 유용한 예제를 통해 각 마스킹 기능을 자세히 살펴 보았습니다. 요구 사항에 따라 모든 마스킹 기능이 포함 된 테이블을 만들고 출력을 봅시다.
사용자 역할 및 권한 이해는중대한. MaskedTestUser는 실제 데이터를 볼 수있는 권한이 없으므로 마스크 된 데이터가 그에게 표시되지만 권한이있는 사용자 및 고객 테이블 소유자 인 dbo는 사용 가능한 모든 데이터를 일반 텍스트로 볼 수 있습니다.</br>
Use tempdb;
DROP TABLE IF EXISTS Customer;
CREATE TABLE Customer
(
Id INT IDENTITY(1,1)
,DateOfBirth DATE MASKED WITH (FUNCTION = 'default()') NOT NULL
,EmailId VARCHAR(255) MASKED WITH (FUNCTION = 'email()') NOT NULL
,IdentityNumber VARCHAR(11) MASKED WITH (FUNCTION = 'default()') NOT NULL
,Phone VARCHAR(11) MASKED WITH (FUNCTION = 'default()') NOT NULL
,Salary INT MASKED WITH (FUNCTION = 'random(1,9)') NOT NULL
,CreditCard VARCHAR(20) MASKED WITH (FUNCTION = 'partial(2,"XXXXXX",0)') NOT NULL
);
INSERT INTO Customer (DateOfBirth, EmailId, IdentityNumber, Phone, Salary, CreditCard)
VALUES ('1985-10-28', '[email protected]', 'BZVLPE1258Q', '98564533213', 85000, '9764-3451-0916-1047');
다음 쿼리는 MaskedTestUser 및 dbo 사용자에게 마스크 된 데이터가 표시되는 방법을 보여줍니다.
--Drop and Create MaskedTestUser
DROP USER IF EXISTS MaskedTestUser;
CREATE USER MaskedTestUser WITHOUT LOGIN;
--Query table using dbo user
SELECT * FROM Customer;
--Grant SELECT permission to MaskedTestUser
GRANT SELECT ON Customer TO MaskedTestUser;
--Query table using MaskedTestUser
EXECUTE AS USER = 'MaskedTestUser';
SELECT * FROM Customer;
--Revert user impersonation to dbo user
REVERT;

테이블의 기존 열에 마스킹 기능 추가
ALTER TABLE Customer DROP COLUMN IF EXISTS AccountNumber;
ALTER TABLE Customer
ADD AccountNumber INT;
ALTER TABLE Customer
ALTER COLUMN AccountNumber ADD MASKED WITH (FUNCTION = 'random(1000,5000)');
개요
동적 데이터 마스킹은 권한이 없는 사용자로부터 민감한 데이터를 숨기는 데 유용합니다. 데이터 기밀성이 비즈니스에 중요한 경우에 사용할 수 있습니다.
'Database > SQL Server' 카테고리의 다른 글
| 조인 조건자 없음 (0) | 2020.08.27 |
|---|---|
| DB 보안 (0) | 2020.08.27 |
| Missing Index (0) | 2020.08.27 |
| 인덱스 리빌드는 통계를 업데이트 할까? (0) | 2020.08.27 |
| INDEX 인덱스 상세 정보 확인 (0) | 2020.08.27 |



