데이터를 INSERT 하게 된다면 페이지에 들어가게 되고, 테이블에 쿼리를 날려 조회하는 것이 아니라 페이지에서 SELECT하는 것으로 생각하면 됩니다. 그러므로 페이지라는 것을 숙지해야합니다.
인덱스(Index) 는 왜 사용하고 장점은 무엇인가?
빠른 데이터를 검색하기 위해서입니다. 찾는 데이터를 가지고 있다면 직접 주거나, 없다면 어디 있는지 알려줍니다.
데이터의 중복을 방지할 수 있습니다. (Primary Key, Unique)
잠금을 최소화 시켜줍니다. (동시성을 높여줍니다.)
인덱스(Index) 의 단점은 무엇인가?
물리적인 공간을 차지하게 됩니다. (인덱스도 테이블처럼 데이터를 가지므로 물리적인 공간을 차지하게 됩니다.)
페이지를 가지고 있는 존재는 데이터와 인덱스 두가지입니다. (프로시져/뷰는 사이즈가 없습니다.)
인덱스에 대한 유지관리 부담이 존재합니다.
데이터가 극히 적다면은 얻는 효과보다 유지관리 부담이 더 클 수 있습니다.
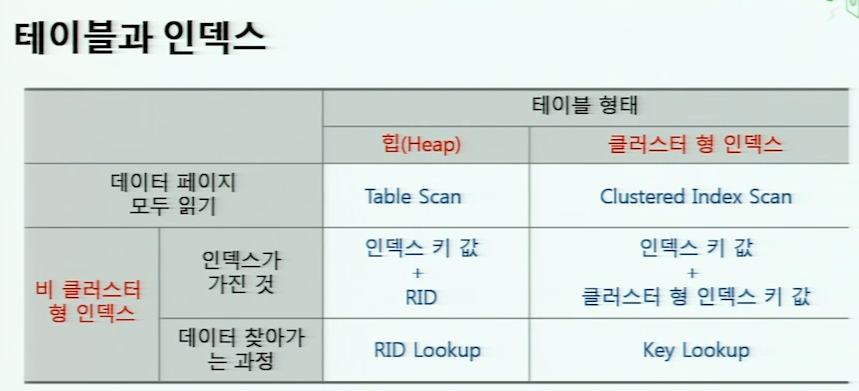
테이블의 존재 형태는 아래 그림 처럼 두 가지로 나뉩니다. 힙(heap)과 클러스터 형 인덱스 입니다.
힙(Heap) 이란?
정렬의 기준이 없이 저장 된 테이블의 형태를 말합니다.
데이터 페이지 내의 행들 간에 순서가 없고, 페이들 간에도 순서가 없습니다.
클러스터 형 인덱스가 없는 테이블이라고 생각하시면 쉽습니다.
힙의 장점과 단점은 무엇인가?
장점은 INSERT 문이 좋아하는 테이블 형태입니다. 새로운 행을 기존 페이지의 빈 곳에 추가하면 되고, 빈 공간이 없으면 새로운 페이지에 추가하면 되기 때문입니다.
단점은 SELECT 문이 싫어하는 테이블 형태입니다. 데이터가 극히 적으면 상관없겠지만, 데이터가 많으면 전체적으로 모든 테이블을 스캔해야하기 때문에 데이터를 찾기가 어렵습니다.
위에서도 말했듯이, 원하는 데이터를 찾기 위해서는 Table Scan 을 해야 합니다. 전체적으로 페이지를 다 읽는겁니다. 전체적으로 모든 페이지를 다 읽는다고 하니, 당연히 좋지 않습니다.
클러스터 형 인덱스란?
특정 열(또는 열들)을 기준으로 데이터가 정렬되어 있습니다. (물리적 정렬이 아닌, 논리적 정렬)
테이블 당 하나의 클러스터 형 인덱스를 설정 가능합니다.
다시 한번 말하면, 테이블의 형태는 두가지로 나뉘게 됩니다.
정렬되어 있지 않은 힙과 특수한 Key 값으로 정렬되어진 클러스터 형 인덱스로 나누어집니다. 우리는 선택을 해야 합니다. 힙을 사용할지, 클러스터 형 인덱스를 선택할지. 힙이 무조건 좋지 않다라고 말할 수 없습니다. 상황마다 다르기 때문에 그 상황에 맞게 테이블을 설계하는 것이 개발자의 몫입니다.
클러스트 형의 데이터 찾기
이제부터 많은 용어가 나옵니다. 그러한 용어는 필수적으로 숙지해야합니다.
Clustered Index Seek : Root 페이지부터 찾아가서, 아주 빠른 성능을 보여줍니다.
Clustered Index Scan : 모든 데이터 페이지를 읽기 때문에 힙에서 사용했던 방식인 Table Scan과 다를바 없습니다.
힙 + 비 클러스터 형 인덱스
비 클러스터 형 인덱스에는 인덱스 키 열의 모든 데이터와 RID(행의 주소)를 가지고 있습니다.
RID를 가지고 있는 이유는 RID는 거의 변하지 않고 크기가 크지 않기 때문에 한번에 찾아갈 수 있기 때문입니다.
999개 까지 만들 수 있습니다.
Index Seek : NonClustered 가 생략되어졌고, Root 페이지를 이용하기 때문에 성능이 좋습니다.
RID Lookup : 비 클러스터형 인덱스에 RID 값이 저장되어 있기 때문에, 힙을 검색할때에는 RID값을 이용해서 검색하기 때문에 RID Lookup이 됩니다.
클러스터 형 인덱스 + 비 클러스터 형 인덱스
비 클러스터 형 인덱스에는 클러스터 형 인덱스 키 열과 인덱스 키 열의 모든 데이터를 가지고 있습니다.
클러스터 형 인덱스의 키 열은 거의 변하지 않습니다. (힙의 RID는 변할 가능성이 높습니다.)
999개 까지 만들 수 있습니다.
Key Lookup : 비 클러스터 형 인덱스가 가지지 못한 데이터를 찾아가는 과정입니다.
결론
아래 그림으로 한방에 정리됩니다. 테이블은 클러스터 형 인덱스가 잡혀있는 테이블과 아닌 테이블로 구성되어 진다는 것을 알 수 있습니다.
그리고 비 클러스터 형 인덱스가 결합되어지면, 힙에는 RID 값을 가지고 있고 클러스터 형 인덱스는 키 값을 가지고 있습니다. 비 클러스터 형 인덱스에서 힙으로 검색될 때에는 RID Lookup, 클러스터 형 인덱스에 검색 되어 질 때에는 Key Loopup 이라는 용어가 사용되어 집니다.
현업에서 RID Lookup 으로 검색되어지는 테이블이 있다면, 그 테이블이 왜 힙을 사용하고 있는지 원인 분석이 필요한 것으로 보여집니다.
-- <<관련 Command >>
-- Query Store 설정 확인
SELECT actual_state, actual_state_desc, readonly_reason, current_storage_size_mb, max_storage_size_mb
FROM sys.database_query_store_options;
-- 실행 계획 확인
SELECT Txt.query_text_id, Txt.query_sql_text, Pl.plan_id, Qry.*
FROM sys.query_store_plan AS Pl JOIN sys.query_store_query AS Qry ON Pl.query_id = Qry.query_id
JOIN sys.query_store_query_text AS Txt ON Qry.query_text_id = Txt.query_text_id ;
-- Query Store 데이터의 메모리 내 부분을 디스크로 플러시합니다.
EXEC sp_query_store_flush_db;
-- 쿼리를 삭제하고 쿼리 저장소에서 관련된 모든 계획과 런타임 통계를 제거합니다. ( Clears the runtime stats for a specific query plan from the query store )
EXEC sp_query_store_remove_query 3;
-- 쿼리 저장소에서 실행계획에 대한 실행 통계 삭제 ( Clears the runtime stats for a specific query plan from the query store )
EXEC sp_query_store_reset_exec_stats 3;
-- 쿼리 저장소에서 단일 계획을 제거합니다.
EXEC sp_query_store_remove_plan 3;
-- 특정 쿼리에 대한 특정 계획을 강제 실행합니다.
-- sp_query_store_force_plan 을 사용하면 쿼리 저장소에서 기록한 계획 만 해당 쿼리의 계획으로 강제 실행할 수 있습니다.
-- 즉, 쿼리에 사용할 수있는 유일한 계획은 쿼리 저장소가 활성화되어있는 동안 해당 쿼리를 실행하는 데 이미 사용 된 계획뿐입니다.
-- QUERY_ID , PLAN_ID 순서
EXEC sp_query_store_force_plan 3, 3;
-- 특정 쿼리에 대해 특정 PLAN 설정 해제 하기 ( Enables unforcing a particular plan for a particular query )
-- QUERY_ID , PLAN_ID 순서
EXEC sp_query_store_unforce_plan 3, 3;
-- 실행 계획 확인
SELECT Txt.query_text_id, Txt.query_sql_text, Pl.plan_id, Qry.*
FROM sys.query_store_plan AS Pl JOIN sys.query_store_query AS Qry ON Pl.query_id = Qry.query_id
JOIN sys.query_store_query_text AS Txt ON Qry.query_text_id = Txt.query_text_id ;
ALTER DATABASE TGTEST SET QUERY_STORE (INTERVAL_LENGTH_MINUTES = 30);
ALTER DATABASE TGTEST SET QUERY_STORE (MAX_STORAGE_SIZE_MB = 200);
ALTER DATABASE TGTEST SET QUERY_STORE
( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30)
, DATA_FLUSH_INTERVAL_SECONDS = 300
, MAX_STORAGE_SIZE_MB = 500
, INTERVAL_LENGTH_MINUTES = 15
, SIZE_BASED_CLEANUP_MODE = AUTO
, QUERY_CAPTURE_MODE = AUTO
, MAX_PLANS_PER_QUERY = 1000
, WAIT_STATS_CAPTURE_MODE = ON );
SELECT * FROM sys.database_query_store_options;
-- 수행 횟수가 2보다 작고, 마지막 수행이 24전 보다 오랜 쿼리를 QUERY STORE 에서 삭제하기
DECLARE @id int
DECLARE adhoc_queries_cursor
CURSOR FOR SELECT q.query_id
FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q
ON q.query_text_id = qt.query_text_id JOIN sys.query_store_plan AS p
ON p.query_id = q.query_id JOIN sys.query_store_runtime_stats AS rs
ON rs.plan_id = p.plan_id
GROUP BY q.query_id
HAVING SUM(rs.count_executions) < 2 -- 수행 횟수가 2보다 작고
AND MAX(rs.last_execution_time) < DATEADD (hour, -24, GETUTCDATE()) -- 마지막 수행 시간이 24간 이전
ORDER BY q.query_id ;
OPEN adhoc_queries_cursor ;
FETCH NEXT FROM adhoc_queries_cursor INTO @id;
WHILE @@fetch_status = 0
BEGIN PRINT @id EXEC sp_query_store_remove_query @id
FETCH NEXT FROM adhoc_queries_cursor INTO @id
END
CLOSE adhoc_queries_cursor ;
DEALLOCATE adhoc_queries_cursor;
-- 가장 최근까지 수행 쿼리
SELECT TOP 10 qt.query_sql_text, q.query_id, qt.query_text_id, p.plan_id, rs.last_execution_time
FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
ORDER BY rs.last_execution_time DESC;
-- 자주 수행되는 쿼리
SELECT q.query_id, qt.query_text_id, qt.query_sql_text, SUM(rs.count_executions) AS total_execution_count
FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
GROUP BY q.query_id, qt.query_text_id, qt.query_sql_text
ORDER BY total_execution_count DESC;
-- 최근 1시간 동안 평균 수행 시간이 가장 오래 걸린 쿼리
SELECT TOP 10 rs.avg_duration, qt.query_sql_text, q.query_id, qt.query_text_id, p.plan_id
, GETUTCDATE() AS CurrentUTCTime, rs.last_execution_time
FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id
WHERE rs.last_execution_time > DATEADD(hour, -1, GETUTCDATE())
ORDER BY rs.avg_duration DESC;
-- 최근 24시간 내에 IO가 가장 높은 쿼리 10
SELECT TOP 10 rs.avg_physical_io_reads, qt.query_sql_text, q.query_id, qt.query_text_id, p.plan_id
, rs.runtime_stats_id, rsi.start_time, rsi.end_time, rs.avg_rowcount, rs.count_executions
FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id JOIN sys.query_store_runtime_stats AS rs
ON p.plan_id = rs.plan_id JOIN sys.query_store_runtime_stats_interval AS rsi
ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rsi.start_time >= DATEADD(hour, -24, GETUTCDATE())
ORDER BY rs.avg_physical_io_reads DESC;
-- 실행계획이 여러개인 쿼리
WITH Query_MultPlans AS
( SELECT COUNT(*) AS cnt, q.query_id
FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p
ON p.query_id = q.query_id
GROUP BY q.query_id
HAVING COUNT(distinct plan_id) > 1 )
SELECT q.query_id, object_name(object_id) AS ContainingObject, query_sql_text, plan_id
, p.query_plan AS plan_xml, p.last_compile_start_time, p.last_execution_time
FROM Query_MultPlans AS qm JOIN sys.query_store_query AS q
ON qm.query_id = q.query_id JOIN sys.query_store_plan AS p
ON q.query_id = p.query_id JOIN sys.query_store_query_text qt
ON qt.query_text_id = q.query_text_id
ORDER BY query_id, plan_id;
-- 실행계획 변경으로 성능 저하 쿼리 ( 수행이 48 이내, 실행계획이 변경되며, 평균 수행 시간이 더 오래 걸린 쿼리 )
SELECT qt.query_sql_text, q.query_id, qt.query_text_id, rs1.runtime_stats_id AS runtime_stats_id_1
,rsi1.start_time AS interval_1, p1.plan_id AS plan_1, rs1.avg_duration AS avg_duration_1
,rs2.avg_duration AS avg_duration_2, p2.plan_id AS plan_2, rsi2.start_time AS interval_2
, rs2.runtime_stats_id AS runtime_stats_id_2
FROM sys.query_store_query_text AS qt JOIN sys.query_store_query AS q
ON qt.query_text_id = q.query_text_id JOIN sys.query_store_plan AS p1
ON q.query_id = p1.query_id JOIN sys.query_store_runtime_stats AS rs1
ON p1.plan_id = rs1.plan_id JOIN sys.query_store_runtime_stats_interval AS rsi1
ON rsi1.runtime_stats_interval_id = rs1.runtime_stats_interval_id JOIN sys.query_store_plan AS p2
ON q.query_id = p2.query_id JOIN sys.query_store_runtime_stats AS rs2
ON p2.plan_id = rs2.plan_id JOIN sys.query_store_runtime_stats_interval AS rsi2
ON rsi2.runtime_stats_interval_id = rs2.runtime_stats_interval_id
WHERE rsi1.start_time > DATEADD(hour, -48, GETUTCDATE())
AND rsi2.start_time > rsi1.start_time
AND p1.plan_id <> p2.plan_id
AND rs2.avg_duration > 2*rs1.avg_duration
ORDER BY q.query_id, rsi1.start_time, rsi2.start_time;
-- 가장 오래 대기한 쿼리
SELECT TOP 10 qt.query_text_id, q.query_id, p.plan_id, sum(total_query_wait_time_ms) AS sum_total_wait_ms
FROM sys.query_store_wait_stats ws JOIN sys.query_store_plan p
ON ws.plan_id = p.plan_id JOIN sys.query_store_query q
ON p.query_id = q.query_id JOIN sys.query_store_query_text qt
ON q.query_text_id = qt.query_text_id
GROUP BY qt.query_text_id, q.query_id, p.plan_id
ORDER BY sum_total_wait_ms DESC
--- 최근 1시간, 24시간 쿼리 성능 비교
--- "Recent" workload - last 1 hour
DECLARE @recent_start_time datetimeoffset;
DECLARE @recent_end_time datetimeoffset;
SET @recent_start_time = DATEADD(hour, -1, SYSUTCDATETIME()); -- 1시간전
SET @recent_end_time = SYSUTCDATETIME();
--- "History" workload
DECLARE @history_start_time datetimeoffset;
DECLARE @history_end_time datetimeoffset;
SET @history_start_time = DATEADD(hour, -24, SYSUTCDATETIME()); -- 24시간전
SET @history_end_time = SYSUTCDATETIME();
WITH hist AS
( SELECT p.query_id query_id, CONVERT(float, SUM(rs.avg_duration*rs.count_executions)) total_duration
, SUM(rs.count_executions) count_executions
, COUNT(distinct p.plan_id) num_plans
FROM sys.query_store_runtime_stats AS rs JOIN sys.query_store_plan p
ON p.plan_id = rs.plan_id
WHERE (rs.first_execution_time >= @history_start_time AND rs.last_execution_time < @history_end_time)
OR (rs.first_execution_time <= @history_start_time AND rs.last_execution_time > @history_start_time)
OR (rs.first_execution_time <= @history_end_time AND rs.last_execution_time > @history_end_time)
GROUP BY p.query_id )
, recent AS
( SELECT p.query_id query_id, CONVERT(float, SUM(rs.avg_duration*rs.count_executions)) total_duration
, SUM(rs.count_executions) count_executions, COUNT(distinct p.plan_id) num_plans
FROM sys.query_store_runtime_stats AS rs JOIN sys.query_store_plan p
ON p.plan_id = rs.plan_id
WHERE (rs.first_execution_time >= @recent_start_time AND rs.last_execution_time < @recent_end_time)
OR (rs.first_execution_time <= @recent_start_time AND rs.last_execution_time > @recent_start_time)
OR (rs.first_execution_time <= @recent_end_time AND rs.last_execution_time > @recent_end_time)
GROUP BY p.query_id )
SELECT results.query_id query_id, results.query_text query_text
, results.additional_duration_workload additional_duration_workload
, results.total_duration_recent total_duration_recent
, results.total_duration_hist total_duration_hist
, ISNULL(results.count_executions_recent, 0) count_executions_recent
, ISNULL(results.count_executions_hist, 0) count_executions_hist
FROM ( SELECT hist.query_id query_id, qt.query_sql_text query_text
, ROUND(CONVERT(float, recent.total_duration/ recent.count_executions-hist.total_duration/hist.count_executions) *(recent.count_executions), 2) AS additional_duration_workload, ROUND(recent.total_duration, 2) total_duration_recent
, ROUND(hist.total_duration, 2) total_duration_hist, recent.count_executions count_executions_recent, hist.count_executions count_executions_hist
FROM hist JOIN recent ON hist.query_id = recent.query_id JOIN sys.query_store_query AS q
ON q.query_id = hist.query_id JOIN sys.query_store_query_text AS qt
ON q.query_text_id = qt.query_text_id ) AS results
WHERE additional_duration_workload > 0
ORDER BY additional_duration_workload DESC OPTION (MERGE JOIN);
CREATE TABLE #MEMBER(
num INT,
name NVARCHAR(20),
score INT
)
INSERT INTO #MEMBER (num, name, score) VALUES(1, '홍길동', 90);
INSERT INTO #MEMBER (num, name, score) VALUES(2, '고길동', 85);
INSERT INTO #MEMBER (num, name, score) VALUES(3, '피카츄', 83);
INSERT INTO #MEMBER (num, name, score) VALUES(4, '파이리', 85);
INSERT INTO #MEMBER (num, name, score) VALUES(5, '꼬북이', 80);
테이블 예제
동적쿼리 생성 과정
-- 매개 변수들을 선언해준다.
DECLARE @sql AS NVARCHAR(MAX), -- SQL 구문
@sqlp AS NVARCHAR(MAX), -- SQL 매개 변수
@num AS INT, -- num 매개 변수
@name AS NVARCHAR(20), -- name 매개 변수
@score AS INT -- score 매개 변수
-- WHERE 절에 들어갈 변수
SET @score = 85;
-- 기본적인 SELECT 구문
SET @sql = N'SELECT * FROM #MEMBER WHERE 1=1 ';
-- IF 절로 예외처리
IF ISNULL(@num, 0) > 0 BEGIN
SET @sql = @sql + ' AND num = @num ';
END
IF ISNULL(@name, '') != '' BEGIN
SET @sql = @sql + N' AND name = ''' + @name + N'''';
END
IF ISNULL(@score, 0) > 0 BEGIN
SET @sql = @sql + ' AND score = @score';
END
-- EXECUTESQL에 들어갈 매개변수 정의
SET @sqlp = N'
@num AS INT,
@name AS NVARCHAR(20),
@score AS INT';
-- 실행
EXEC SP_EXECUTESQL @sql, @sqlp, @num=@num, @name=@name, @score=@score;
Input Parameter 값의 유무에 따라서 WHERE 조건절에 들어갈지 말아야할지 정할때 동적쿼리를 가장 많이 사용한다.
@num/@name/@score 값의 유무를 @sql에 넣어준다.
@sql 변수에 들어간 동적쿼리
@sql 변수의 값이 자유자재로 변하게 된다.
원하는 결과값이 출력
정리
이전 회사에서 동적쿼리가 좋은지?
정적쿼리가 좋은지? 에 대한 갑론을박이 있었다.
사실 동적쿼리의 장점은 속도라고 말할 수 있었는데, 진행하고 있던 프로젝트의 전체적인 프로시저를 동적쿼리에서 정적쿼리로 바꾼적이 있다.
그 이유는 실행계획에 이유가 있었는데...정확한 이유는 기억 못하겠다.
여튼, 동적쿼리든 정적쿼리든 상황에 맞게 잘 사용해야겠다. 개발에는 100%라는 것이 없기에...
데이터베이스의 사이즈를 모니터링 하는 것은 DBA의 중요한 업무중 하나 인데요. 트랜잭션 로그가 채워지지 않도록 트랜잭션 로그를 정기적으로 잘라야 합니다. 잘라야 합니다. 자르다... 어감이 마치... 10기가 짜리 로그 파일을 1기가로 줄이는... 그런거 같습니다. 근데 아니에요. 10기가를 1기가로 줄이는것은 로그 자르기가 아니고 파일 축소 작업입니다.
DBCC SHRINKFILE
명령을 이용해서 줄입니다. 이것도 맘대로 줄일 수 있는게 아니고 비활성 로그 부분만 줄일 수 있습니다. 로그를 자르고 나면 그 잘린 부분이 "비활성 로그"입니다. 그럼 로그는 언제 잘라질까요? 단순 복구 모델에서는 Checkpoint 발생이후 잘립니다. 전체 복구 모델이나 대량 로그 복구 모델에서는 일단 로그 백업이 한번 되고 난 후 Checkpoint가 발생하면 잘립니다. 로그가 잘렸다... 라는 것은 재사용 가능하게 바뀌었다라는 것을 뜻합니다. 트랜잭션 로그 파일은 내부적으로는 VLF 라는 걸로 나우어져서 사용됩니다. 예를 들어서 8기가 짜리 로그 파일을 만들었다면 대략 512메가 짜리 16개의 VLF 파일이 생깁니다. 그리고 처음부터 하나씩 사용되어 집니다. 로그가 잘릴일이 없으면 트랜잭션 로그는 계속 늘어나게 됩니다. 그러다 보면 데이터 파일은 1기가인데 로그 파일이 100기가가 되는 그런 기현상도 벌어지죠. 로그파일에 대한 정보는
DBCC LOGINFO WITH TABLERESULTS, NO_INFOMSGS
명령을 이용해서 볼 수 있습니다. 결과는 다음과 같습니다.
각각의 열은 하나의 VLF를 나타냅니다. FileSize는 KB입니다. Status가 2인 VLF가 현재 사용중이거나 아직 잘리지 않은 로그입니다. Status가 0인 VLF는 비활성 로그입니다. 잘린거죠. 잘린 로그는 재사용되어집니다.
1
DBCC SHRINKFILE (LogFileName, TRUNCATEONLY)
명령을 사용하면 마지막 활성 로그 이후의 공간을 운영체제에 반환하게 됩니다. 10기가 짜리 로그 파일이 1기가가 되는게 이 상황입니다. 만약 잘린 로그가 없다면 로그 파일은 무한정 커지게 됩니다. 무한용량 하드가 있다면 걱정없겠지만.... 포멧은 언제하나... 앞서 로그백업 후 Checkpoint가 발생하면 로그가 잘린다고 했었는데요. 로그가 잘린 이후 활성로그가 하나만 남는것이 이상적이랍니다. 활성로그가 여러개인 경우는 여러가지 경우가 있을 수 있겠는데 엄청나게 긴 트랜잭션이 VLF 여러개에 로그를 기록중인데 아직 트랜잭션이 끝나지 않은 경우 또는 그리 길지 않은 트랜잭션인데 VLF크기가 너무 작아서 좀 길다... 싶으면 여러개 잡아 먹는 경우가 있을 수 있겠는데요. 긴 트랜잭션이면 짧게 끝나도록 수정하면 되겠지만 VLF가 작은 경우는 문제가 좀 있습니다. 남아 있는 비활성 로그가 없을 경우 트랜잭션 로그를 기록 하기 위해서 로그파일을 늘려야 할텐데요. 이때 OS에 파일 크기를 늘려달라는 요청을 하게 될겁니다. 로그 기록하기도 바쁜데 파일 크기까지 늘려야 하니 쿼리 수행은 당연히 느려질겁니다. 그래서 제일 이상적인 상태는 로그 백업을 하는 주기 동안 더 이상 늘어나지 않아도 될만큼 충분한 로그 파일을 확보하고 그 안에서 VLF의 숫자가 적당히 존재하는게 최적일 겁니다. 적당히... 적당한 연봉은?? 그리고 로그 백업 후에는 활성 로그가 하나만 남아 있는것이 좋을것입니다. VLF의 크기를 수동으로 조절하면 좋겠지만 아쉽게도 그런 옵션은 없습니다. VLF의 크기는 처음 로그 파일을 만들때 결정됩니다. 대략 8기가 짜리 로그 파일을 만들면 512메가로 16개가 생깁니다. 그래서 처음부터 용량 계획을 하고 적당한 크기로 만들어 두는게 좋습니다. 만약 처음부터 적당한 용량으로 만들지 못했다면 일단 무슨 수를 쓰던 모든 로그를 비활성으로 만든 후 (백업을 하고 Checkpoint 수행) 파일을 줄이고 적당한 크기로 늘려놓으면 됩니다. 그래도 처음 두개의 vlf는 크기를 조정할 수 없습니다. 이상은 로그파일에 대한 설명이었고 다음 스크립트는 모든 DB에 대한 VLF의 갯수와 활성VLF 숫자를 조회하는 쿼리입니다.
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SET NOCOUNT ON
IF OBJECT_ID('tempdb..#LOGINFO', 'U') IS NOT NULL DROP TABLE #LOGINFO
IF OBJECT_ID('tempdb..#LOGINFOTemp', 'U') IS NOT NULL DROP TABLE #LOGINFOTemp
이번에는 뷰를 생성할 때 WITH SCHEMABINDING 옵션에 대해서 얘기를 꺼내볼까 합니다.
BOL에 찾아보면...
SCHEMABINDING
기본 테이블의 스키마에 뷰를 바인딩합니다. SCHEMABINDING을 지정하면 뷰 정의에 영향을 미치는 방법으로 기본 테이블을 수정할 수 없습니다. 뷰 정의 자체를 먼저 수정하거나 삭제하여 수정할 테이블에 대해 종속성을 제거해야 합니다. SCHEMABINDING을 사용하는 경우 select_statement에 참조되는 테이블, 뷰 또는 사용자 정의 함수의 두 부분으로 구성된 이름(schema.object)이 있어야 합니다. 참조된 개체는 모두 같은 데이터베이스에 있어야 합니다.
SCHEMABINDING 절로 만든 뷰에서 사용하는 뷰 또는 테이블은 뷰가 삭제되거나 변경되어 스키마 바인딩이 더 이상 존재하지 않는 경우에만 삭제할 수 있습니다. 그렇지 않으면 데이터베이스 엔진에서 오류가 발생합니다. 또한 ALTER TABLE 문이 뷰 정의에 영향을 미치는 경우에는 스키마 바인딩이 있는 뷰에서 사용하는 테이블에서 이러한 문을 실행할 수 없습니다.
뷰에 별칭 데이터 형식 열이 있는 경우 SCHEMABINDING을 지정할 수 없습니다.
이 글만 읽게 되면... "아... 스키마 바인딩은.. 원래 테이블을 수정할 수 없게 하기 위해서 만드는 거구나" 라는 것만 생각 하게 됩니다.
그래서.. 뷰의 스키마 바인딩에 대해서 좀 더 자세히 알아보기 위해.. 이번 아티클을 작성하게 되었습니다.
뷰는 가상의 테이블입니다... 데이터가 존재하지 않는다고 생각합니다.
하지만 스키마바인딩 옵션으로 뷰에도 데이터를 가질 수 있습니다.
즉.. 테이블과 뷰에 동시에 같은 데이터를 가질 수 있게 설정할 수 있다는 말입니다.
예제를 통해 보도록 하겠습니다.
일단 스키마 바인딩 되지 않는 뷰!
SET NOCOUNT ON
GO
IF OBJECT_ID('T1','U') IS NOT NULL
DROP TABLE t1
GO
IF OBJECT_ID('VI_T1','V') IS NOT NULL
DROP VIEW VI_T1
GO
CREATE TABLE t1
(
idx int identity
, ClusteredValue int not null
, ViewClusteredValue int not null
)
GO
--//데이터1000건삽입
INSERT INTO t1(ClusteredValue, ViewClusteredValue)
아마 디스크 개수, RAID Mode, Stripe Size, File Allocation Unit Size 등을 떠올릴 수 있을 겁니다.
그런데 이런 요소들 중 과소 평가되거나, 혹은 아예 고려하지 않는 것으로 "Disk Partition Alignment" 라는 부분이 있습니다.
우리말로 하면 "디스크 파티션 정렬" 정도가 되겠군요.
참고로 파티션을 정렬한다는 것은 파티션이 시작하는 시작점을 특정 값으로 설정하는 것을 의미합니다.
첫번째 의문
- 파티션은 원래 0번째 byte 지점에서 시작하는게 아닌가?
네, 아닙니다.
디스크에서 기록이 시작되는 맨 앞부분의 63 섹터 (= 31.5 KB)는 MBR - Master Boot Recoder - 영역이기 때문인데요.
따라서 파티션의 기본 시작 지점은 64번째 섹터부터가 됩니다.
두번째 의문
- 이게 필요한 작업이라면 SE 분들이 알아서 해주지 않나? DBA가 이런 것 까지 신경써야하는 이유가 있을까?
개인적인 경험으로는 6개국의 퍼블리셔를 통해 게임을 런칭하면서 "디스크 파티션 정렬"을 언급하거나 적용한 SE팀은 한 곳도 없었습니다.
경험많은 SE에게도 SQL Server의 스토리지 최적화를 위해 디스크 파티션을 정렬해야 한다는 것은 생소하다는 의미라는 거겠죠.
세번째 의문
- 이 작업이 성능 최적화에 도움이 되는 이유는 무엇인가?
몇 가지 배경 지식이 필요합니다.
1. Stripe Unit Size대부분의 서버 장비는 디스크를 RAID로 구성합니다.RAID 설정을 만져보신 분들은 잘 아시겠지만, Stripe Unit Size는 RAID 설정 과정에서 결정하게 되는 값 중 하나죠.글로 설명하면 장황할 것 같으니 좀 더 자세한 내용을 알고 싶으시다면, 잠깐 구글링하고 오시면 되겠습니다. ^^2. Cluster Size = File Allocation Unit SizeFAT, FAT32, NTFS.. 이게 무엇인지 잘 아실겁니다. Windows OS에서 사용하는 File System이죠.이제는 PC에서도 NTFS를 사용하기 때문에 각각의 차이를 굳이 언급하진 않겠습니다.여기서 중요한건 우리가 NTFS를 선택하여 파티션을 포맷할 때 클러스터 사이즈를 얼마로 정할 것인가 입니다.역시 클러스터 사이즈에 대한 자세한 내용은 구글링을 추천합니다.참고로 NTFS의 기본 클러스터 사이즈는 4KB입니다.3. SQL Server에 적절한 Stripe Unit Size 및 Cluster Size 는?SQL Server가 디스크에 데이터를 입출력하는 I/O의 단위는 extent입니다.1 extent = 8 pages = 64KB하드웨어 공급자가 특별히 권고하는 값이 없다면, Stripe Unit Size와 Cluster Size는 모두 64KB로 설정하는 것이 일반적입니다.단, 이 내용이 절대적으로 옳은 것은 아닙니다.예를 들어 Stripe Unit Size = 128KB & Cluster Size = 32KB와 같은 조합에서 성능이 더 좋은 경우도 있습니다.하지만 일반적인 권고를 따랐을 때, 보통은 상위의 성능이 나온다고 볼 수 있습니다.
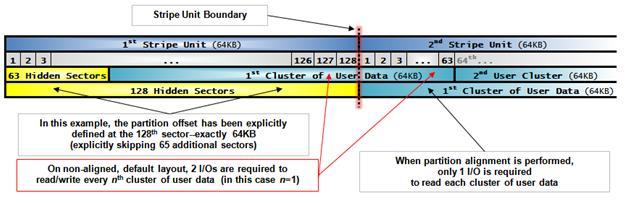
위 그림은 Stripe Unit Size와 Cluster Size가 모두 64KB일 때의 상황입니다.
세번째 줄은 정렬되지 않은 파티션이고, 네번째 줄은 정렬된 파티션이군요.
세번째 줄을 보시면 파티션이 64번째 섹터에서 시작합니다.
어떤 문제가 생길까요?
1개의 클러스터를 읽거나 쓸때마다 2개의 Stripe Unit에 대한 I/O가 발생합니다.
이에 비해 네번째 줄은 파티션의 offset 값이 64KB (= 128 sector)로 정렬되어 있습니다.
따라서, 1개의 클러스터를 읽을 때 오직 한번의 I/O가 발생하고 있습니다.
이게 파티션 정렬이 필요한 이유입니다.
이론 적으로는 위 그림처럼 파티션의 시작 offset 값으로 64를 지정하는게 적절해 보입니다.하지만, 하드웨어 벤더의 권고로 Stripe Unit Size를 128KB 또는 256KB를 선택할 수도 있습니다.그 밖에도 미처 예상하지 못한 예외가 있을 수 있는데요.그래서 offset을 1024로 설정하는 것이 일반적인 권고입니다.1024는 여타의 설정값이 예상 가능한 범주에서 조금 유동적이라고해도 파티션이 잘 정렬되는 값이기 때문입니다.
네번째 의문
- MS가 이런 사실을 모를리 없을텐데, 이 문제가 여전히 발생하고 있나?
엄밀히 말해 파티션의 offset이 31.5KB인 것은 Windows 2003을 포함한 이전 버전에 한합니다.
Windows 2008부터는 offset 값이 1024KB이므로, 맨 앞 1024KB가 끝나는 직후부터 파티션이 시작하도록 변경되었죠.
하지만 상황에 따라 이 기본값이 지켜지지 않는 경우도 존재하기 때문에, Windows 2008 이후의 버전을 사용한다해도 디스크 파티션의 offset 값은 명시적으로 지정해 주는 것을 권장하고 있습니다.
마치며...SQL Server의 디스크 구성을 잘 하느냐 못 하느냐에 따라 큰 성능 차이가 발생합니다.디스크도 여러개 사용하고 심지어 DAS까지 붙였는데 제 성능을 내지 못한다면 정말 안타까운 일이겠죠.SE 분들이 챙겨 주신다면 고마운 일이지만, 미리 이런 내용을 안내해 주는 것이 더 좋겠습니다. ^^