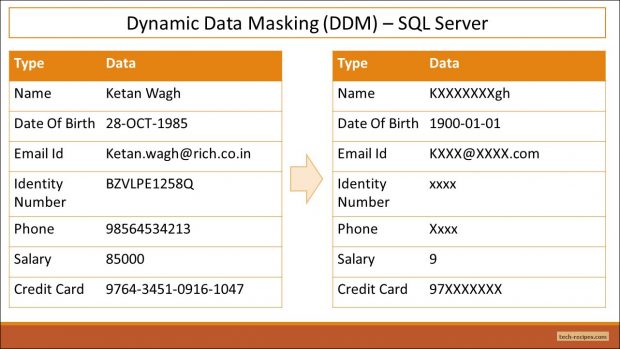
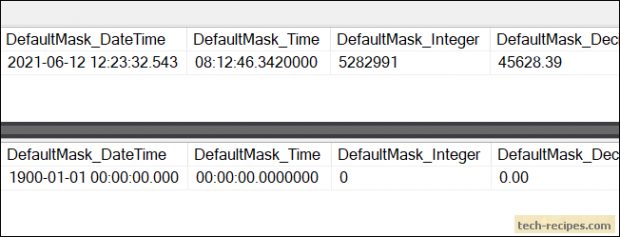
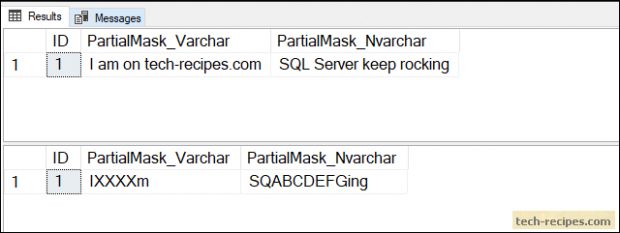
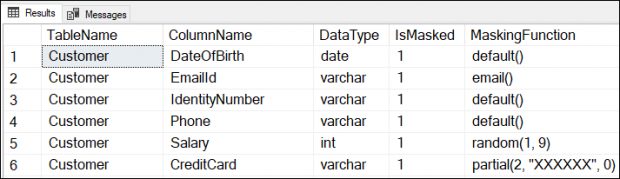
DB 보안 설정
- 인증 방법에 따른 차이점
- 윈도우 인증과 로그인 인증의 차이점
1. 윈도우 인증은 SQL Server로 하여금 운영체제의 보안 기능 (암호 암호화(encryption), 암호 사용 기간, 암호의 최소/최대 길이 제한) 이 사용 가능합니다.
2. 윈도우 인증은 트러스트된 연결을 사용하여 기존 윈도우의 연결 방식에 의존한다.
3. 윈도우 인증은 액티브 디렉터리 사용자 및 로컬 사용자 인증이 가능합니다.
- 계정 관리
1. DB 최소권한의 유저로 운영하라.
2. 사용하지 않는 저장된 프로시저와 기능들은 제거하거나 관리자에게 제한된 접근권한을 주어라.
3. 퍼미션을 변경하고, 공개된 시스템 객체에 접근을 제거 하라.
4. 모든 사용자 계정의 패스워드를 강화 시켜라
- SQL Injection
1.저장된 프로시저를 사용할 때 매개변수화 된 API를 이용하라.
모든 입력 값 검증은 일반적인 루틴을 이용하고, 최소한의 권한을 DB 사용자 에게 적용하라.
2.프로시저로 변경 하고 동적 쿼리를 사용하지 않는다.
3.데이터베이스와 연동을 하는 스크립트의 모든 파라미터들을 점검하여 사용자의 입력 값이 SQL injection을 발생시키지 않도록 수정한다.
4.사용자 입력이 SQL injection을 발생시키지 않도록 사용자 입력 시 특수문자(' " / \ ; : Space -- +등)가 포함되어 있는지 검사하여 허용되지 않은 문자열이나 문자가 포함된 경우에는 에러로 처리한다.
5.SQL 서버의 에러 메시지를 사용자에게 보여주지 않도록 설정한다.
공격자는 리턴 되는 에러 메시지에 대한 분석을 통하여 공격에 성공할 수 있는 SQL Injection 스트링을 알아낼 수 있다. 따라서 SQL 서버의 에러 메시지를 외부에 제공하지 않도록 한다.
6.웹 애플리케이션이 사용하는 데이터베이스 사용자의 권한을 제한한다.
가능하면 일반 사용자 권한으로는 모든 system stored procedures에 접근하지 못하도록 하여 웹 애플리케이션의 SQL Injection 취약점을 이용하여 데이터베이스 전체에 대한 제어권을 얻거나 데이터베이스를 운용중인 서버에 대한 접근이 불가능하도록 한다.
7. 위험한 확장 저장 프로시저들을 제거한다. (확장 프로시저를 생성 할수 있는 dll도 같이 삭제)
(xp_cmdshell, Xp_regread, xp_regwrite , Xp_makewebtask ,Xp_enumdsn)
1. 인증
윈도우 인증
윈도우의 인증 방법만을 사용한 인증
사용자가 SQL 서버에 연결할 때는 별도의 로그인 절차 없이 윈도우 계정 정보로 SQL 서버에 연결한다.
SQL 서버 MASTER 데이터베이스 안에 있는 syslogin 테이블이 모든 윈도우 사용자 계정이나 그룹 계정에 관한 정보들을 SQL 서버 로그인 계정으로 가지고 있다.
윈도우의 액티브 디렉토리 서비스에 지원되는 단일 로그인 기능을 사용할 수도 있다.
SQL 서버 인증
운영체제와는 별개의 아이디 패스워드를 가지고 있으면서 사용자의 인증을 관리하는 방식
운영체제의 강력한 보안체계를 전혀 활용할 수 없다는 단점이 있다.
혼합 인증
윈도우, SQL 서버 인증 방식을 동시에 사용 하는 방식
2가지의 장점을 잘 조화하여 사용 하는 방식
2. 로그인 과 유저
로그인 : SQL 서버에 접속한다는 의미
유저: 데이터베이스를 사용하기 위한
로그인 관련정보는 syslogins 테이블에 저장
유저의 관련정보는 sysusers 테이블에 저장
SQL 서버 설치시 기본적으로 만들어지는 로그인 계정
- Sa: System Administrator, sql 서버와 모든 데이터베이스에서 사용 가능한 모든 권한 소유
- BUILTIN/Administrator : Adminstrator 그룹으로 SQL 서버에 접속하는 사용자들을 위한 윈도우 인증 방법으로 접속할 때의 최고의 권한을 가지는 계정이다. (윈도우를 서버로 사용할 때만 등록되어 있다.)
- 새로운 로그인 생성
1. SP
sp_addlogin [ @loginame = ] 'login'
[ , [ @passwd = ] 'password' ] -- 빈암호 사용을 자제해야함 Default NULL
[ , [ @defdb = ] 'database' ] - Default master
[ , [ @deflanguage = ] 'language' ] Default NULL, 서버의 현재 기본 언어
[ , [ @sid = ] sid ] Default Null
[ , [ @encryptopt= ] 'encryption_option' ]
2. CREATE
CREATE LOGIN login_name { WITH <option_list1> | FROM <sources> }
<sources> ::=
WINDOWS [ WITH <windows_options> [ ,... ] ]
| CERTIFICATE certificateName
| ASYMMETRIC KEY asym_key_name
<option_list1> ::=
PASSWORD = { 'password' | hashed_password HASHED } [ MUST_CHANGE ]
[ , <option_list2> [ ,... ] ]
<option_list2> ::=
SID = sid
| DEFAULT_DATABASE = database
| DEFAULT_LANGUAGE = language
| CHECK_EXPIRATION = { ON | OFF}
| CHECK_POLICY = { ON | OFF}
| CREDENTIAL = credential_name
<windows_options> ::=
DEFAULT_DATABASE = database
| DEFAULT_LANGUAGE = language
SQL 서버 인증 방식
USE [master]
GO
CREATE LOGIN [SA_TEST] WITH PASSWORD=N'1235_111', DEFAULT_DATABASE=[master], CHECK_EXPIRATION=ON, CHECK_POLICY=ON
GO
윈도우 인증 방식
USE [master]
GO
CREATE LOGIN [TAEK\TaekSu] FROM WINDOWS WITH DEFAULT_DATABASE=[test], DEFAULT_LANGUAGE=[한국어]
GO
USE [test]
GO
CREATE USER [TAEK\TaekSu] FOR LOGIN [TAEK\TaekSu]
GO
- 유저 생성
모든 데이터베이스 마다 자동적으로 만들어지는 유저는 dbo 하나 밖에 없다.
모든 데이터베이스에 공통적으로 생성해주어야 하는 유저가 있다면 model 데이터베이스 안에 원하는 유저를 생성해주면 된다.
SP
sp_adduser [ @loginame = ] 'login'
[ , [ @name_in_db = ] 'user' ]
[ , [ @grpname = ] 'role' ]
CREATE
CREATE USER user_name [ { { FOR | FROM }
{
LOGIN login_name
| CERTIFICATE cert_name
| ASYMMETRIC KEY asym_key_name
}
| WITHOUT LOGIN
]
[ WITH DEFAULT_SCHEMA = schema_name ]
동일한 SP에 대해 2000, 20005 , 2008의 처리 방식이 다름.
SYSTEM 테이블
master.dbo.syslogins
master.dbo.syslanguages
master.dbo.sysxlogins
sys.schemas
sys.database_permissions
3. 역할 ROLE
- 시스템 정의 역할
시스템 정의 역할은 SQL 서버에서 미리 정의해 놓은 역할.
- 서버역할
서버 역할은 SQL 서버에서 로그인 계정들을 그룹화 하고 정해진 권한을 부여하기 위해 사용
서버 역할은 사용자가 새로운 역할을 추가하거나 기존의 역할에 설정되어 있는 권한을 변경할 수 없다.
역할 설명
Bulkadmin BULK INSERT 문을 실행
Dbcreator 데이터베이스 생성, 삭제, 변경, 복원 가능
Diskadmin 디스크 파일 관리
Processadmin 프로세스 종료 가능
Securityadmin 로그인 및 속성 관리, 데이터베이스 수준의 사용 권한 허가 및 거부 등 가능
Serveradmin 서버 차원의 구성 옵션 변경 가능, 서버 종료 가능
Setupadmin 링크드 서버 추가 및 제거, 일부 시스템 저장 프로시저 실행 가능
sysadmin 서버의 모든 작업 수행 가능
SP_ADDSRVROLEMEMBER 시스템 저장 프로시저를 사용하는 문법
Sp_addsrvrolemember [ @loginame = ] 'login'
, [ @rolename = ] 'role'
- 데이터베이스 역할
DB role이라고 부르며 각 데이터베이스 안에서 유저에 부여하는 것이다.
권한 변경이 불가능한 고정된 역할과, 권한을 변경할 수 있고 모든 유저가 속해 있는 public 역할이 있다.
역할 설명
Db_accessadmin 윈도우 로그인, 그룹 및 sql 서버 로그인 관리
Db_backupadmin 데이터베이스 백업 관리
Db_datareader 테이블 조회 권한 관리
Db_datawriter 테이블 데이터 변경 가능
Db_ddladmin 모든 DDL 명령 실행 가능
Db_denydatareader 테이블 조회 구너한을 제거
Db_denydatawriter 테이블 데이터 변경 권한을 제거
Db_owner 데이터베이스 내 모든 권한 사용
Db_securityadmin 사용 권한 관리
Public 데이터베이스 사용자가 가지는 가장 최소한의 권리
SP_ADDROLEMEMBER
Sp_addrolemember [ @rolename = ] 'role' ,
[ @membername = ] 'security_account'
SYSTEM TABLE , DBCC
2000 sysusers
2005 sys.database_principals
dbcc auditevent
- 사용자 정의 역할
동일한 권한을 가진 유저 그룹을 만들 수 있게 해주는 것으로서 실제로 db role의 일부분이
라고 할 수 있다.
SP
p_addrole [ @rolename = ] 'role' [ , [ @ownername = ] 'owner' ]
CREATE
USE [test]
GO
CREATE ROLE [MyRole] - Role 생성
GO
USE [test]
GO
EXEC sp_addrolemember N'MyRole', N'SA_TEST' - 데이터베이스 역할 생성
GO
use [test]
GO
GRANT ALTER ON [dbo].[a] TO [MyRole] - 권한 생성
GO
use [test]
GO
GRANT SELECT ON [dbo].[c] TO [MyRole] WITH GRANT OPTION
GO
use [test]
GO
GRANT VIEW DEFINITION ON [dbo].[d] TO [MyRole]
GO
Db_decurityadmin이나 db_owner 역할을 가진 유저만 추가 가능
SSMS , sp_addrole, sp_droprole 로 추가가 가능
- 애플리케이션 역할
애플리케이션 역할 역시 db Role의 일부분이라고 볼 수 있다.
특정한 응용 프로그램에 따라 사용할 수 있는 권한을 제한하는 것.
주의사항: 한번 설정된 애플리케이션 역할은 해당 세션이 끝날 때까지 계속 유효하며, 일반 역할이나 유저에 부여된 모든 권한이나 역할은 해당 세션에서 모두 무시된다.
SP 활용
sp_addapprole [ @rolename = ] 'role' , [ @password = ] 'password'
CREATE APPLICATION ROLE application_role_name
WITH PASSWORD = 'password' [ , DEFAULT_SCHEMA = schema_name ]
USE [test]
GO
CREATE APPLICATION ROLE [AppRoleTest] WITH PASSWORD = N'1234'
GO
use [test]
GO
GRANT EXECUTE ON [sys].[sp_ActiveDirectory_SCP] TO [AppRoleTest]
GO
use [test]
GO
GRANT INSERT ON [dbo].[c] TO [AppRoleTest]
GO
EXEC sp_setapprole 'AppRoleTest','1234';
SETUSER [ 'username' [ WITH NORESET ] ]
데이터베이스에 대한 ALTER ANY APPLICATION ROLE 권한이 필요합니다.
보안 카탈로그 뷰
http://msdn.microsoft.com/ko-kr/library/ms178542.aspx
보안 저장 프로시저
http://msdn.microsoft.com/ko-kr/library/ms182795.aspx
4. 데이터베이스 암호화
SQL 서버 2000까지의 암호화
- 문서화되지 않은 PWDEncrypt 함수로 복호화 되지 않는 단 방향 해시 함수로, 해당 값의 비교를 위한 PWDCompare 함수를 따로 지원한다.
DECLARE @Ciphertext varbinary(20);
DECLARE @Plaintext varchar(20);
SET @Plaintext = 'Hello'
set @Ciphertext = PWDENCRYPT(@Plaintext)
SELECT [원문] = @Plaintext , [암호문] = @ciphertext
SQL 서버 2005 암호화 방식
- 내장된 암호화 함수가 제공되고 이 함수 (MD2,MD4,MD5SHA,SHA1) 지원 (단방향 해시)
DECLARE @Ciphertext varbinary(20);
DECLARE @Plaintext varchar(20);
SET @Plaintext = 'Hello'
set @Ciphertext = HashBytes('SHA1',@Plaintext)
SELECT [원문] = @Plaintext , [암호문] = @ciphertext
- ENCRYPTBYPASSPHRASE 패스워드를 가지고서 키를 암호화 하는 방식
DECLARE @CreditCardNo varchar(20);
SET @Creditcardno = '1234567890'
DECLARE @PASS nvarchar(128);
SET @PASS = '암호화문자입니다.'
DECLARE @Enctext varbinary(8000)
set @Enctext = EncryptByPassPhrase(@Pass,@creditCardNo)
DECLARE @Dectext varbinary(8000)
set @Dectext = DecryptByPassPhrase(@Pass,@Enctext)
SELECT @creditCardNo 카드번호,
@PASS 암호화문자,
@Enctext 암호화,
@Dectext,
CONVERT(VARCHAR,@Dectext) 복호화
복호화에 반환되는 데이터는 VarBinary 형태임에 주의하여 문자열로 변환 하여야 한다.
SQL SERVER 2008
TDE (Transparent Data Encrypt)
http://msdn.microsoft.com/ko-kr/library/bb934049.aspx
http://optimizer.tistory.com/48
5. 보안 이슈
1. Windows Server, SQL Server Patch
2. JS/Spida 1443포트를 사용하는 SQL 서버에 sa 계정의 패스워드가 NULL인 경우 감염되는 바이러스이다.
JS/Spida, JS.Spida, JS_SQLSPIDA, JScript/SQLSpida, Worm, SQLsnake, Digispid로 불리고 5월 말에 주로 행동했던 것은 이 웜 바이러스의 변종인 JS/Spida.B이다.
3. 윈도우 인증모드라고 하여도 SA 패스워드를 NULL로 남겨두지 않는다.
4. DBMS 포트를 기본 1433에서 다른 포트로 변경하거나 필터링 한다.
5. SA 패스워드를 잘 보관한다. ASP 혹은 ASA 파일들, Connect.inc와 같은 데이터베이스 연결 문자열을 담아주는 파일들, 레지스트리에 패스워드를 넣어놓는 것은 sa의 패스워드를 노출할 위험이 있는 것이다. 암호화 되거나 컴포넌트와 같은 컴파일 된 파일에 보관하도록 한다.
6. 위험한 확장 저장 프로시저들을 제거하라.
- Xp_cmdshell (쉘 상의 모든 명령들을 수행할 수 있다.)
USE master
GO
IF OBJECT_ID('[dbo].[xp_cmdshell]') IS NOT NULL BEGIN
EXEC sp_dropextendedproc 'xp_cmdshell'
END
GO
-
- Xp_regread, xp_regwrite (레지스트리를 읽거나 쓰기가 가능)
- Xp_makewebtask (데이터베이스 내의 정보들을 인터넷에 게시할 수 있다.)
- Xp_enumdsn (DNS 정보들을 보고자 하는 경우 사용)
- Sp_dropextendedproc 시스템 프로시저로 제거 할수 있다. Ex) sp_dropextendedproc 'xp_cmdshell'
1) master database
· 확장 프로시저 퍼미션 삭제
· REVOKE EXECUTE ON xp_regread FROM public
· REVOKE EXECUTE ON xp_instance_regread FROM public GO
· sp_runwebtask 접근을 통한 web task 실행 권한 획득 방지
· REVOKE EXECUTE ON dbo.sp_runwebtask FROM public GO
2) msdb database
· Agent Job 접근을 통한 권한 확대 방지
· REVOKE EXECUTE ON sp_add_job FROM public
· REVOKE EXECUTE ON sp_add_jobstep FROM public
· REVOKE EXECUTE ON sp_add_jobserver FROM public
· REVOKE EXECUTE ON sp_start_job FROM public
· mswebtasks 테이블을 통한 web task 관리 권한 획득 방지
· REVOKE ALL ON dbo.mswebtasks FROM public
· DTS packages 를 통한 administrator 패스워드 유출 방지
· REVOKE EXECUTE ON sp_enum_dtspackages FROM public
· REVOKE EXECUTE ON sp_get_dtspackage FROM public
· SQL Agent Password 노출 방지
· REVOKE EXECUTE ON sp_get_sqlagent_properties FROM public
프로시저들의 Drop후에도 dll 파일은 남아 있으니 아래 쿼리를 실행하여 제거한다.
· dbcc xp_cmdshell(free)
· dbcc xp_dirtree(free)
· dbcc xp_regdeletekey(free)
· dbcc xp_regenumvalues(free)
· dbcc xp_regread(free)
· dbcc xp_regwrite(free)
· dbcc sp_makewebtask(free)
· dbcc sp_adduser(free)
다음으로 SQL Injection을 유발시킬 수 있는 시스템 DB상에 존재하는 프로시저들의 EXCUTE권한을 DENY하겠다. 해당 프로시저들을 통해 시스템의 정보를 조회하고 변경할 수 있으니 필수적으로 DENY해야 할 권한들이다.
· DENY EXECUTE ON [master].[dbo].[xp_subdirs] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_dirtree] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_availablemedia] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_regwrite] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_regread] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_regaddmultistring] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_regdeletekey] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_regdeletevalue] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_regremovemultistring] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_regaddmultistring] TO [guest] CASCADE
마지막으로 일반 User의 물리적 파일 접근을 제한하기 위해 아래 쿼리를 실행한다.
· DENY EXECUTE ON [master].[dbo].[xp_fileexist] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_fixeddrives] TO [guest] CASCADE
· DENY EXECUTE ON [master].[dbo].[xp_getfiledetails] TO [guest] CASCADE
7. SQL 서버 에러 로그를 자주 검사하고 잘 보관해라.
6. SQL Injection
1. 저장 프로시저를 작성하여 Spooky Loing 문제를 해결 할 수 있다.
2. 저장된 프로시저를 사용할 때 매개변수화 된 API를 이용하라. 모든 입력 값 검증은 일반적인 루틴을 이용하고, 최소한의 권한을 DB 사용자 에게 적용하라.
3. 프로시저로 변경 하고 동적 쿼리를 사용하지 않는다.
4. 데이터베이스와 연동을 하는 스크립트의 모든 파라미터들을 점검하여 사용자의 입력 값이 SQL injection을 발생시키지 않도록 수정한다.
5. 사용자 입력이 SQL injection을 발생시키지 않도록 사용자 입력 시 특수문자(' " / \ ; : Space -- +등)가 포함되어 있는지 검사하여 허용되지 않은 문자열이나 문자가 포함된 경우에는 에러로 처리한다.
6. SQL 서버의 에러 메시지를 사용자에게 보여주지 않도록 설정한다. 공격자는 리턴 되는 에러 메시지에 대한 분석을 통하여 공격에 성공할 수 있는 SQL Injection 스트링을 알아낼 수 있다. 따라서 SQL 서버의 에러 메시지를 외부에 제공하지 않도록 한다.
7. 웹 애플리케이션이 사용하는 데이터베이스 사용자의 권한을 제한한다. 가능하면 일반 사용자 권한으로는 모든 system stored procedures에 접근하지 못하도록 하여 웹 애플리케이션의 SQL Injection 취약점을 이용하여 데이터베이스 전체에 대한 제어권을 얻거나 데이터베이스를 운용중인 서버에 대한 접근이 불가능하도록 한다.
Sys.object의 public 권한 제거
7. 서버를 견고하게 운영하기
1. DB 최소권한의 유저로 운영하라.
2. 사용하지 않는 저장된 프로시저와 기능들은 제거하거나 관리자에게 제한된 접근
권한을 주어라.
3. 퍼미션을 변경하고, 공개된 시스템 객체에 접근을 제거 하라.
4. 모든 사용자 계정의 패스워드를 강화 시켜라
5. 미리 승인된 서버의 링크를 제거 하라.
6. 사용하지 않는 네트워크 프로토콜을 제거하라.
7. 신뢰할 수 있는 네트워크,웹 서버, 백업 서버만 접근을 허용하라.
출처: https://taeksu.tistory.com/entry/SQL-Server-로그인-및-보안 [아ㅏㅏㅏㅏㅏㅏㅏㅏㅏ 졸려]