반복자란 무엇입니까?
정의는 반복기 (또는 연산자)가 쿼리의 기본 구성 요소라고 말합니다.
이것은 무엇을 의미 하는가? 이는 반복기가 단일 작업을 수행하는 객체임을 의미합니다. 예를 들어 테이블의 데이터를 스캔하거나 테이블의 데이터를 업데이트 할 수 있지만 둘 다 수행 할 수는 없습니다.
그래서 반복자 당 하나의 데이터베이스 작업 , 그것이 우리가 기억해야 할 정의입니다.
단일 연산자가 그다지 유용하지 않다고 상상할 수 있습니다. 일반적으로 아무도 단일 작업을 수행하지 않습니다.
이것이 반복자가 쿼리 계획이라고하는 트리에서 결합되는 이유입니다. 쿼리 계획은 각각 자체 작업을 수행하는 여러 반복기 (또는 연산자)로 구성됩니다.
쿼리 계획은 트리 구조이므로 연산자는 자식 (0 개 이상)을 가질 수 있습니다.
SQL Server는 각 쿼리를 최적화하려고합니다. 즉, 가장 저렴하거나 가장 빠르게 수행 할 수있는 특정 쿼리에 대해 최상의 반복기 조합을 찾으려고합니다.
반복자는 무엇을합니까?
각 연산자는 다음 세 가지를 수행합니다.
- 먼저 입력 행을 읽습니다. 행은 데이터 소스 또는 연산자의 하위에서 올 수 있습니다.
- 그런 다음 행을 처리합니다. 이것은 반복기의 유형에 따라 다른 것을 의미 할 수 있습니다.
- 마지막으로 출력을 부모에게 반환합니다.
처리 유형
반복자가 수행 할 수있는 두 가지 유형의 처리가 있습니다.
- 한 번에 한 행 (또는 행 기반 처리 ). 즉, 해당 반복기에 해당하는 작업이 반복기에 들어가는 각 행에 적용됨을 의미합니다.
- 그리고 배치 모드 처리 . 이는 연산자가 한 번에 한 행이 아닌 전체 행 일괄 처리를 처리하는 SQL Server 2012에 도입 된 접근 방식입니다.
행 기반 모델
반복기는 메서드와 속성의 공통 인터페이스를 공유하는 코드 개체입니다. 가장 자주 사용되는 방법은 행을 처리하고, 속성 정보를 설정 및 검색하고, 최적화 프로그램이 사용할 비용 추정치를 생성하는 데 사용되는 방법입니다.
행 기반 모델에서 모든 반복기는 다음과 같은 동일한 핵심 메서드 집합을 구현합니다.
- Open (출력 행 생성을 시작할 때임을 운영자에게 알리는 메서드)
- GetRow (연산자에게 새 행을 생성하도록 요청)
- 그리고 Close 메서드 는 반복기의 부모가 행 요청을 완료했음을 나타냅니다.
모든 반복기는 동일한 구조를 갖기 때문에 서로 독립적으로 작동 할 수 있음을 의미합니다.
이제 쿼리 계획을 살펴보고 하나 이상의 반복기와 이들이 결합되는 방식을 살펴 보겠습니다.
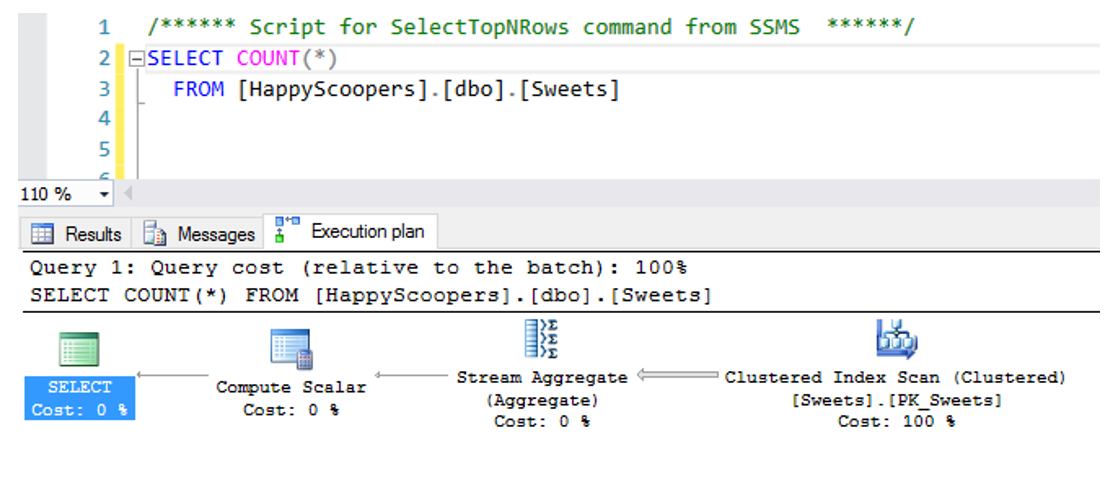
예를 들어 SELECT COUNT (*) FROM Products를 수행하면 내 계획이 이렇게 생겼습니다.
지금 당장 익숙하지 않더라도 걱정하지 마세요. 몇 개의 클립을 더 추가하면 모두 이해하기 시작합니다.
계획을 읽는 방법에는 두 가지가 있습니다.
- 다음 제어 흐름 왼쪽에서 오른쪽으로. 즉, Open, GetRow 및 Close 메서드가 쿼리 트리의 루트 노드부터 호출되고 결과가 리프 반복기로 전파됩니다.
- 그리고 오른쪽 하단에서 왼쪽 상단까지 의 데이터 흐름을 따릅니다. 이것은 데이터가 검색되는 방식입니다.
그래서 우리의 예로 돌아갑니다. 내 Products 테이블의 모든 행을 계산하기 위해 두 개의 연산자가 사용됩니다.
- 테이블에서 모든 행을 가져 오는 하나. 이것은 Products 테이블이 스캔 됨을 의미합니다 .
- 그리고 그들을 세는 하나 . 앞서 말했듯이 운영자 당 하나의 작업 만 수행 할 수 있습니다.
여기서 무슨 일이 일어나고 있습니까?
작업 순서가있는 그림을 살펴보면 각 단계에 대한 설명이 아래에 있습니다.

- 먼저 SQL Server 는 계획의 루트 반복기에서 Open 을 호출 합니다.이 예에서는 COUNT (*) 반복기입니다. COUNT (*) 반복기는 Open 메서드에서 다음 작업을 수행합니다 . 스캔 반복기에서 Open 을 호출 하여 행을 생성 할 시간임을 스캔에 알립니다. 비. 검색 반복기에서 GetRow를 반복적으로 호출 하여 반환 된 행을 계산하고 GetRow가 모든 행을 반환했음을 나타내는 경우에만 중지합니다. C. 스캔 반복기에서 Close 를 호출 하여 행 가져 오기를 완료했음을 나타냅니다.
- COUNT (*) 반복자의 Open 메서드에서 반환 될 때 이미 Products 테이블의 행 수를 알고 있습니다.
- 그러면 COUNT (*)의 GetRow 메서드가 실행되어 결과를 반환합니다.
- SQL Server는 COUNT (*)가 단일 행을 생성한다는 사실을 모르기 때문에 다른 GetRow 메서드 호출이 이어집니다. 그만한 가치는 다른 모든 행과 마찬가지로 더 이상이 없을 때까지 모든 행을 처리하는 연산자입니다.
- 두 번째 GetRow 호출에 대한 응답으로 COUNT (*) 반복기는 결과 집합의 끝에 도달했음을 반환합니다. 마지막으로 이것은 Close 메서드 의 호출을 의미합니다 . COUNT (*) 반복기는 스캔 반복기에서 행을 계산하고 있다는 사실을 신경 쓰거나 알 필요가 없습니다. 하위 트리가 얼마나 단순하거나 복잡한 지에 관계없이 SQL Server가 하위 트리에 배치하는 모든 하위 트리의 행을 계산합니다.
'Database > SQL Server' 카테고리의 다른 글
| Login을 각 Database의 User와 동기화 하기 (0) | 2021.02.09 |
|---|---|
| Showplan Operator of the Week – Merge Interval (0) | 2021.02.02 |
| SORT WARNING & HASH WARNING (0) | 2021.02.02 |
| SQL Server 버퍼 캐시에 대한 통찰력 (0) | 2021.01.27 |
| SQL 에이전트 작업 삭제 오류 ( 유지관리계획 삭제 오류 ) DELETE 문이 REFERENCE 제약 조건 “FK_subplan_job_id”과(와) 충돌했습니다. Microsoft SQL Server, 오류: 547 (0) | 2021.01.27 |