샘플 데이터 생성
Merge Join operator을 설명하기 위해 "Pedidos"(포르투갈어로 '주문'을 의미 함)라는 하나의 테이블을 만드는 것으로 시작하겠습니다. 다음 스크립트는 테이블을 만들고 일부 가비지 데이터로 채 웁니다.
|
USE tempdb GO
IF OBJECT_ID('Pedidos') IS NOT NULL DROP TABLE Pedidos GO
CREATE TABLE Pedidos (ID INT IDENTITY(1,1) PRIMARY KEY, ID_Cliente INT NOT NULL, Quantidade SmallInt NOT NULL, Valor Numeric(18,2) NOT NULL, Data DATETIME NOT NULL) GO
DECLARE @I SmallInt SET @I = 0
WHILE @I < 10000 BEGIN INSERT INTO Pedidos(ID_Cliente, Quantidade, Valor, Data) SELECT ABS(CheckSUM(NEWID()) / 100000000), ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), GETDATE() - (CheckSUM(NEWID()) / 1000000) SET @I = @I + 1 END GO |
이제 테이블이 있으므로 두 개의 비 클러스터형 인덱스를 만들어야합니다. 첫 번째는 쿼리에 적용되는 인덱스를 생성하기 위해 Valor 열을 포함하여 ID_Cliente 열을 키로 사용합니다 . 다른 하나는 Data 열을 Key로 사용하고 Valor 열을 포함합니다 .
|
CREATE NONCLUSTERED INDEX ix_ID_Cliente ON Pedidos(ID_Cliente) INCLUDE (Valor) GO CREATE NONCLUSTERED INDEX ix_Data ON Pedidos(Data) INCLUDE (Valor) GO |
Merge Interval
이제 데이터가 있으므로 merge interval을 확인하는 쿼리를 작성할 수 있습니다. 다음 쿼리는 4 명의 고객에 대한 매출액을 선택합니다.
|
SELECT SUM(Valor) AS Val FROM Pedidos WHERE ID_Cliente IN (1,2,3,4) GO |
위 쿼리의 경우 다음과 같은 실행 계획이 있습니다.
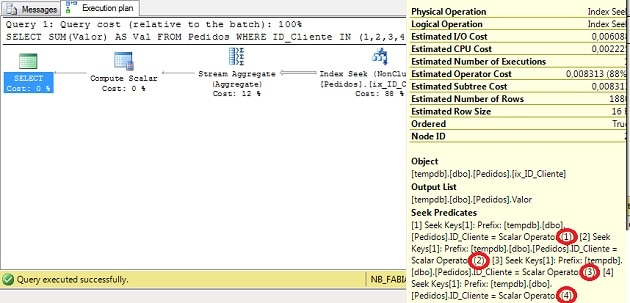
그림 1 – 실행 계획 (전체 크기로 보려면 클릭)
위의 실행 계획에서 QO가 인덱스 ix_ID_Cliente 를 사용 하여 IN 절에 지정된 각 ID_Cliente에 대한 데이터를 검색 한 다음 Stream Aggregate 를 사용하여 합계를 수행하는 것을 볼 수 있습니다.
이것은 고전적인 Index Seek 작업으로, 각 값에 대해 SQL Server는 데이터를 읽고 균형 잡힌 인덱스 트리에서 ID_Cliente를 검색합니다 . 지금은 merge interval이 필요하지 않습니다.
이제 유사한 쿼리를 살펴 보겠습니다.
|
DECLARE @v1 Int = 1, @v2 Int = 2, @v3 Int = 3, @v4 Int = 4
SELECT SUM(Valor) AS Val FROM Pedidos WHERE ID_Cliente IN (@v1, @v2, @v3, @v4) GO |
위 쿼리의 경우 다음과 같은 실행 계획이 있습니다.
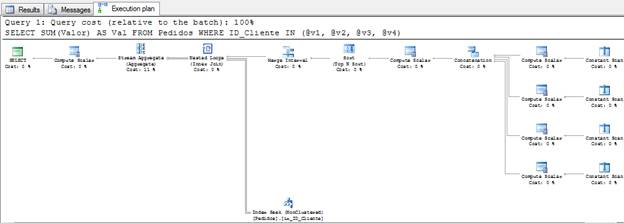
그림 2 – 실행 계획 (전체 크기로 보려면 클릭)
보시다시피 쿼리 간의 유일한 차이점은 이제 상수 값 대신 변수를 사용하고 있지만 쿼리 최적화 프로그램은이 쿼리에 대해 매우 다른 실행 계획을 생성한다는 것입니다. 그래서 질문 : 당신은 어떻게 생각하십니까? SQL이이 쿼리에 대해 동일한 실행 계획을 사용해야한다고 생각하십니까?
정답은 아니오입니다. 왜 안됩니까? 컴파일 타임에 SQL Server는 상수 값을 모르고 값이 중복 된 것으로 판명되면 동일한 데이터를 두 번 읽습니다. @ v2 의 값 도 "1"이라고 가정하면 SQL이 ID 1을 두 번 읽습니다. 하나는 변수 @ v1 이고 다른 하나는 변수 @ v2입니다 . 성능을 기대하기 때문에 볼 수 없을 것입니다. 같은 데이터가 두 번이면 좋지 않습니다. 따라서 Merge Interval을 사용하여 중복 발생을 제거해야합니다.
첫 번째 쿼리의 경우 QO가 IN 절에서 중복 된 항목을 자동으로 제거한다는 말입니까?
예. 보고 싶습니까?
|
SELECT SUM(Valor) AS Val FROM Pedidos WHERE ID_Cliente IN (1,1,3,4) GO |
위 쿼리의 경우 다음과 같은 실행 계획이 있습니다.
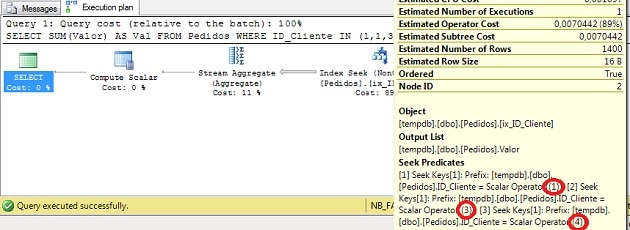
그림 3 – 실행 계획 (전체 크기로 보려면 클릭)
이제 세 개의 Seek 술어 만 있음을 알 수 있습니다. 완전한.
merge interval plan으로 돌아 갑시다.
Plan은 Compute Scalar , Concatenation , Sort 및 Merge Interval 연산자를 사용 하여 실행 계획 단계에서 중복 된 값을 제거합니다.
이 시점에서 몇 가지 질문이 떠오를 수 있습니다. 첫째 : SQL Server가 IN 변수에 DISTINCT를 사용하여 조인을 제거하지 않는 이유는 무엇입니까? 둘째 : 이것이“병합”이라고 불리는 이유는 여기에서 합병과 관련된 어떤 것도 보지 못했습니다.
대답은 쿼리 최적화 프로그램 (QO)이이 연산자를 사용하여 DISTINCT를 수행한다는 것입니다.이 코드를 사용하면 QO가 겹치는 간격도 인식하고 잠재적으로이를 겹치지 않는 간격에 병합하여 값을 찾는 데 사용할 수 있기 때문입니다. 이를 더 잘 이해하기 위해 변수를 사용하지 않는 다음 쿼리가 있다고 가정 해 보겠습니다.
|
SELECT SUM(Valor) AS Val FROM Pedidos WHERE ID_Cliente BETWEEN 10 AND 25 OR ID_Cliente BETWEEN 20 AND 30 GO |
이제 실행 계획을 살펴 보겠습니다.
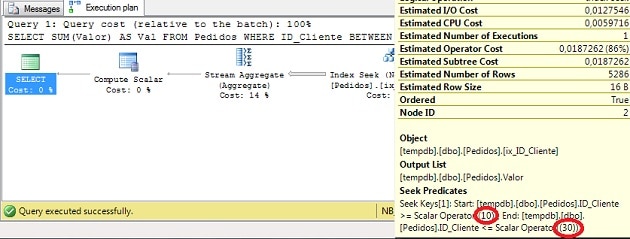
그림 4 – 실행 계획 (전체 크기로 보려면 클릭)
Query Optimizer가 얼마나 똑똑했는지 주목하십시오. (그래서 내가 그것을 좋아하는 이유입니다!) 술어 사이의 겹침을 인식하고 인덱스에서 두 번의 탐색을 수행하는 대신 (필터 사이에 하나씩) 하나의 탐색 만 수행하는 계획을 만듭니다.
이제 변수를 사용하도록 쿼리를 변경해 보겠습니다.
|
DECLARE @v_a1 Int = 10, @v_b1 Int = 20, @v_a2 Int = 25, @v_b2 Int = 30
SELECT SUM(Valor) AS Val FROM Pedidos WHERE ID_Cliente BETWEEN @v_a1 AND @v_a2 OR ID_Cliente BETWEEN @v_b1 AND @v_b2 GO |
이 쿼리의 경우 다음 실행 계획이 있습니다.
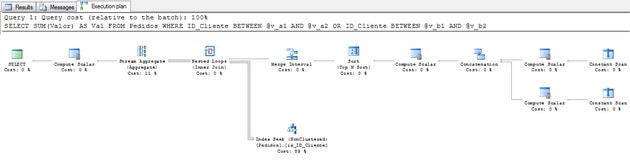
그림 5 – 실행 계획 (전체 크기로 보려면 클릭)
다른 관점을 사용하여 계획이 무엇을하고 있는지 확인합시다. 먼저 겹치는 부분을 이해합시다.
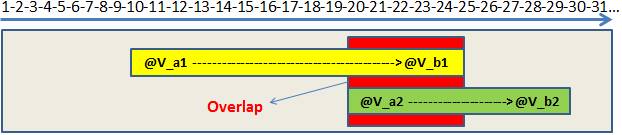
그림 6 – 20에서 25 사이의 겹침
그림 6에서 SQL Server가 범위를 개별적으로 읽는 경우 20에서 25까지의 범위를 두 번 읽는 것을 볼 수 있습니다. 테스트에 작은 범위를 사용했지만 프로덕션 데이터베이스에서 볼 수있는 매우 큰 스캔의 관점에서 생각합니다. 이 단계를 피할 수 있다면 성능이 크게 향상 될 것입니다.
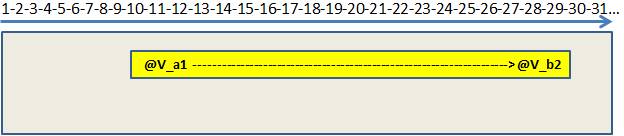
그림 7 – 병합 간격 후
병합 간격이 실행 된 후 SQL Server는 최종 범위 만 검색 할 수 있습니다. @ v_a1 에서 @ vb_2로 직접 이동할 수 있음을 알고 있습니다.
'Database > SQL Server' 카테고리의 다른 글
| SQL Server 매개 변수 스니핑을 수정하기위한 다양한 접근 방식 (0) | 2021.06.30 |
|---|---|
| Login을 각 Database의 User와 동기화 하기 (0) | 2021.02.09 |
| Iterators in the Query Execution Plan (0) | 2021.02.02 |
| SORT WARNING & HASH WARNING (0) | 2021.02.02 |
| SQL Server 버퍼 캐시에 대한 통찰력 (0) | 2021.01.27 |