-- Description: Turns a query into a formatted HTML table. Useful for emails.
-- Any ORDER BY clause needs to be passed in the separate ORDER BY parameter.
-- =============================================
CREATE PROC [dbo].[spQueryToHtmlTable]
(
@query nvarchar(MAX), --A query to turn into HTML format. It should not include an ORDER BY clause.
@orderBy nvarchar(MAX) = NULL, --An optional ORDER BY clause. It should contain the words 'ORDER BY'.
@html nvarchar(MAX) = NULL OUTPUT --The HTML output of the procedure.
)
AS
BEGIN
SET NOCOUNT ON;
IF @orderBy IS NULL BEGIN
SET @orderBy = ''
END
SET @orderBy = REPLACE(@orderBy, '''', '''''');
DECLARE @realQuery nvarchar(MAX) = '
DECLARE @headerRow nvarchar(MAX);
DECLARE @cols nvarchar(MAX);
SELECT * INTO #dynSql FROM (' + @query + ') sub;
SELECT @cols = COALESCE(@cols + '', '''''''', '', '''') + ''['' + name + ''] AS ''''td''''''
FROM tempdb.sys.columns
WHERE object_id = object_id(''tempdb..#dynSql'')
ORDER BY column_id;
SET @cols = ''SET @html = CAST(( SELECT '' + @cols + '' FROM #dynSql ' + @orderBy + ' FOR XML PATH(''''tr''''), ELEMENTS XSINIL) AS nvarchar(max))''
EXEC sys.sp_executesql @cols, N''@html nvarchar(MAX) OUTPUT'', @html=@html OUTPUT
SELECT @headerRow = COALESCE(@headerRow + '''', '''') + ''<th>'' + name + ''</th>''
FROM tempdb.sys.columns
WHERE object_id = object_id(''tempdb..#dynSql'')
ORDER BY column_id;
SET @headerRow = ''<tr>'' + @headerRow + ''</tr>'';
SET @html = ''<table border="1">'' + @headerRow + @html + ''</table>'';
';
EXEC sys.sp_executesql @realQuery, N'@html nvarchar(MAX) OUTPUT', @html=@html OUTPUT
END
GO
As database administrators, we have to support different SQL Server environments. Often it becomes a challenge and obvious to understand the current server health status. To attain this goal based on my requirements, I have created this small tool just for fun with my limited development application skill. It is completely Free, Agent less, No Installation/Configuration is required, Single executable and portable, easy to use and only needs a couple of clicks to be up and running.
Agreement:
This is a non-commercial, educational and learning purpose tool. It is not an alternative for any commercial grade application. This tool is efficient and sharp like a blade; however, I will not able to provide any warranty, guarantee or accuracy of this tool. Although it is a lightweight data collection and visualization tool, it should not cause any performance issues, however you should test it yourself before running it against any database server.
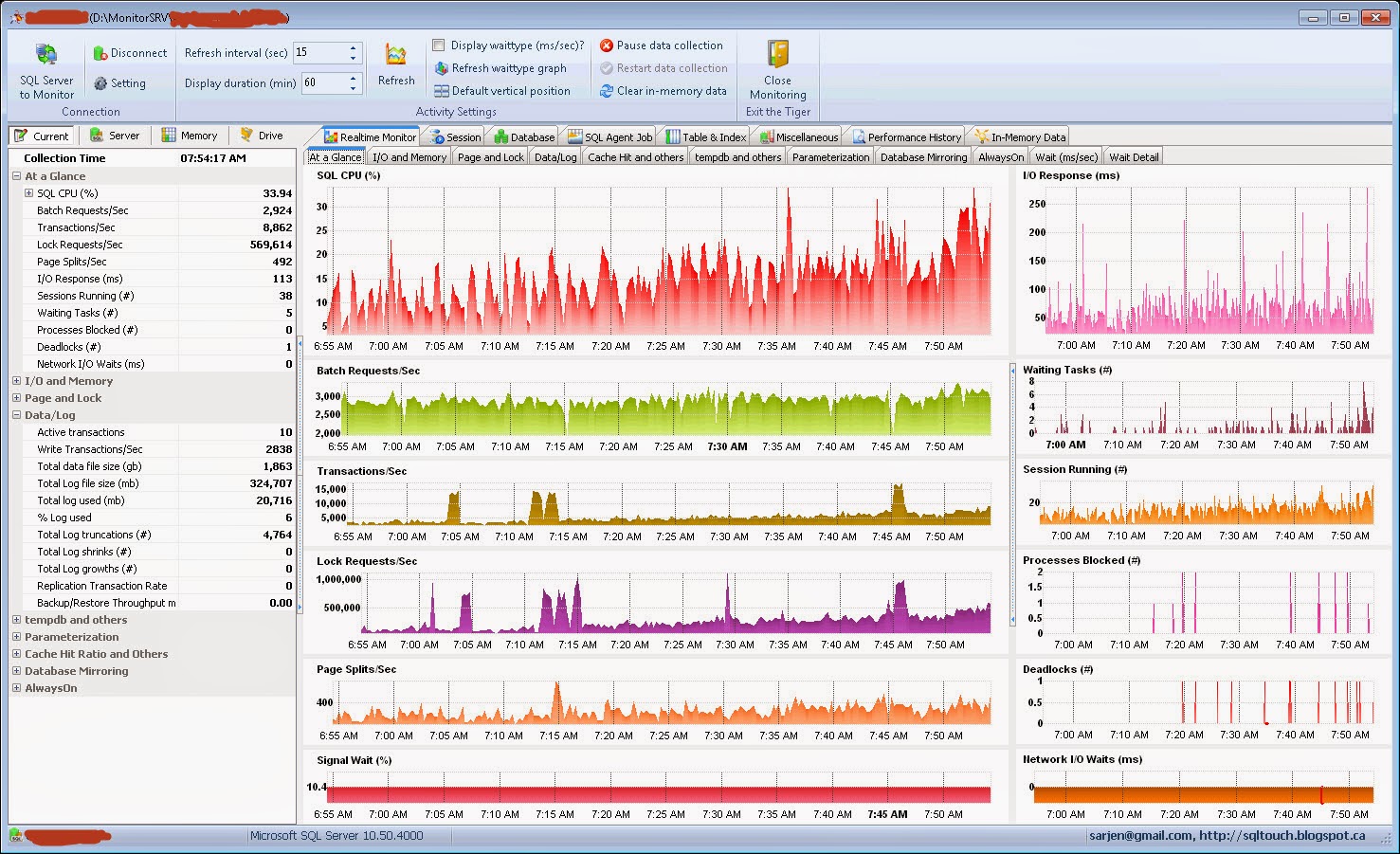
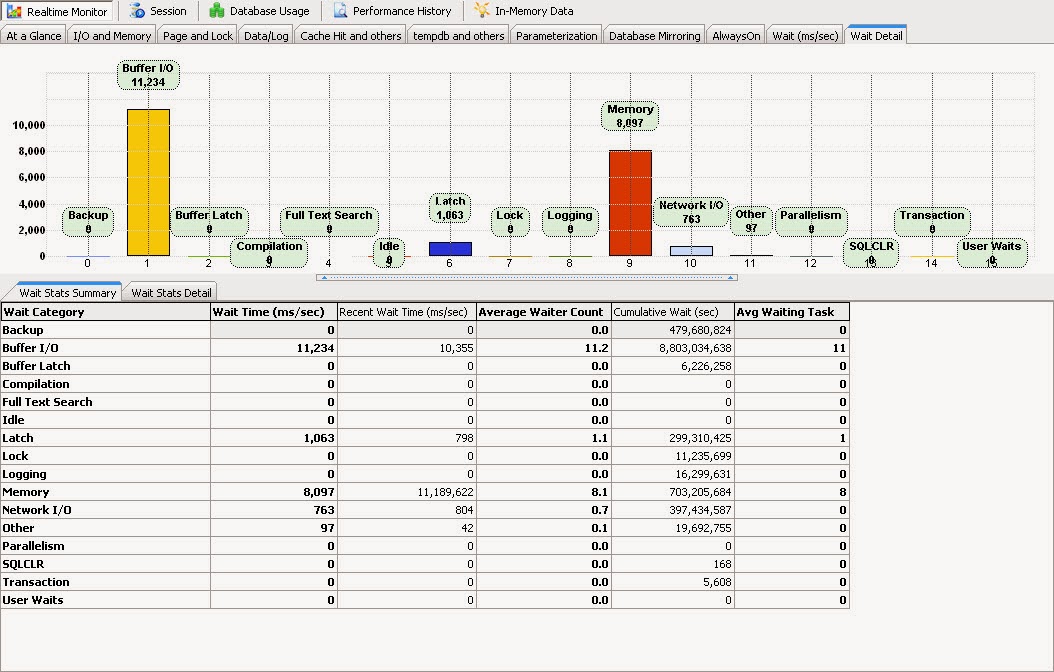
Figure: SQL Performance Monitor
A challenge: Retrieving and visualizing the SQL Server performance data is always a challenge and a tedious task for SQL Server database professionals. Utilizing the Windows PerfMon application is the easiest way to perform this task as well as querying “sys.dm_os_performance_counters” and some other DMVs brings a lot of useful information. Starting from SQL Server 2005, Microsoft has introduced DMV to query various internal metadata directly to explore various health status data. Although collecting and analyzing SQL Server performance data in a regular basis provides trending ability, monitoring real-time performance data is critical to understand an ongoing performance condition that is occurring.
We are all familiar with built-in “SQL Server Activity Monitor” and obviously it is a good starting point to troubleshoot some SQL Server issues. However, the capacity of this tool is limited as it does not provide other performance metrics which are important to understand the server health status. To extend this idea especially during a performance condition, I have attempted to develop a “SQL Performance Monitor” desktop app by including some other interesting metrics which I believe might be helpful to troubleshoot or understand a problem.
This tool collects more than 50+ performance data directly from SQL Server in real-time and shows data in the chart continuously. Also, it does not require any installation and configuration. Data collection: SQL Scripts used in my tool are excerpted from SSMS and some are collected from various forums which are freely available. My understanding is that all the scripts that I have used are reliable however if any are not working, please let me know and I will attempt to fix the issue. How does it work? 1.Has the ability to monitor only a single SQL instance at a time and can be used against all editions of SQL Server from 2005 to SQL 2014.
2.Charts and grids will be populated with collected performance data every 5 seconds by default (can be changed) for every 5 minutes (can be changed) moving forward.
3.Performance data will be saved automatically as they are collected in a SQLite database (sqlmonitor.db3). 4.All saved performance data can be queried, and then can be exported as a CSV format. As “sqlmonitor.db3” is not protected therefore it can be opened with any SQLite tool. Limitations: 1.It has no notification system, such as email, alert, popup. 2.It is a desktop 32-bit application, cannot run as a service. 3.Chart colors have no special meaning. Known Limitations: (a)SQL 2005 – in the “Server Info” tab the “Available Memory” will be zero. (b)CPU utilization has been calculated from “Resource Pool” and @@CPU_BUSY. Due to the internal limitation of SQL Server, and feature limitation of Standard and Express editions, CPU value may show zero on the chart. In Enterprise edition, CPU utilization will not be zero. How to run:
(a)Create a folder.
(b)Download the “SQLMonitor.exe” in that folder.
(c)Run the executable “SQLMonitor.exe”– that’s it.
(d)There is no extra configuration or components required to run this tool.
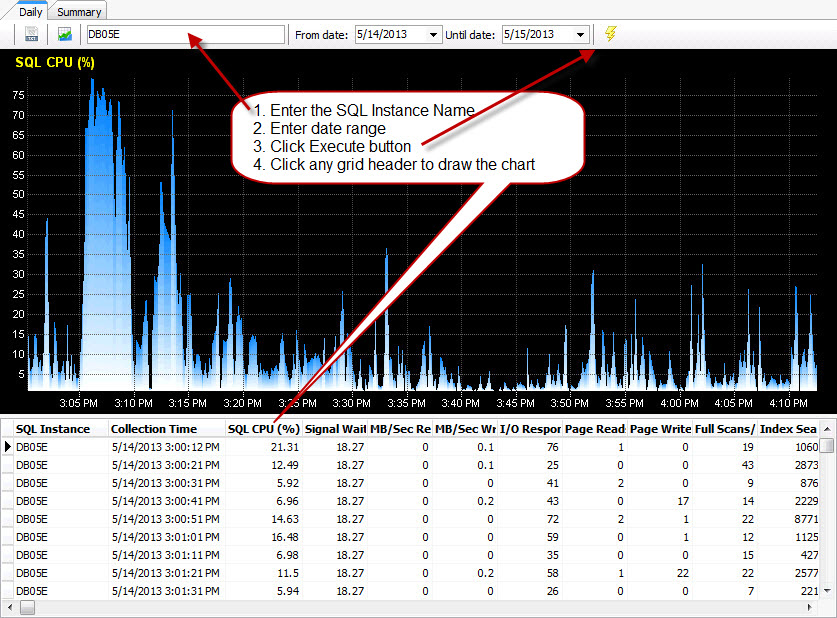
Connect to a database server: The tool bar of “SQL Performance Monitor”
Figure#1: Tool bar of SQL Activity Monitor
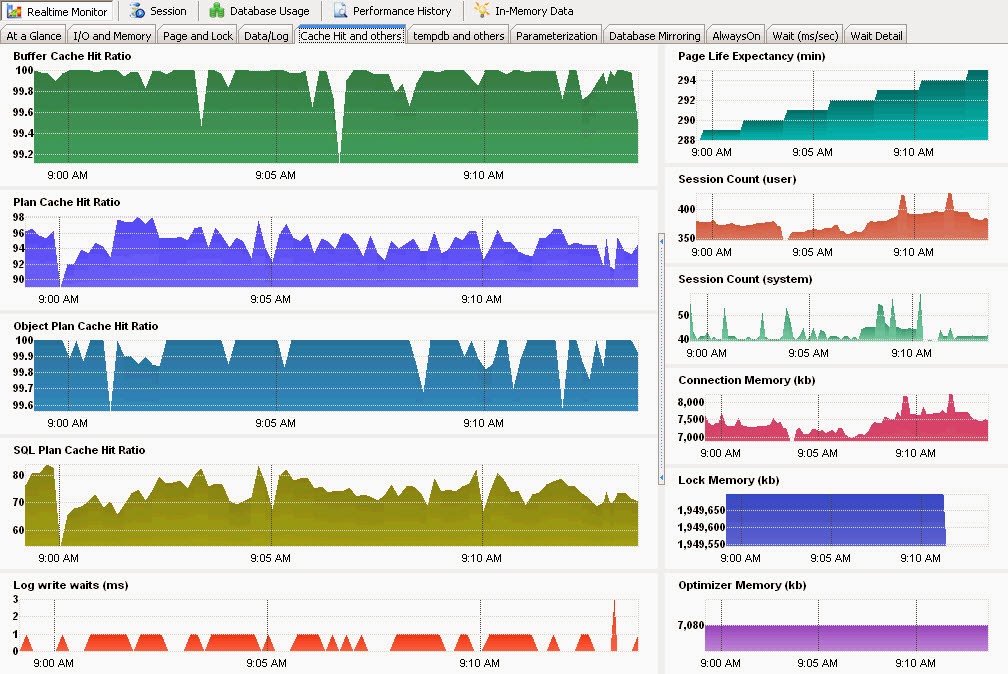
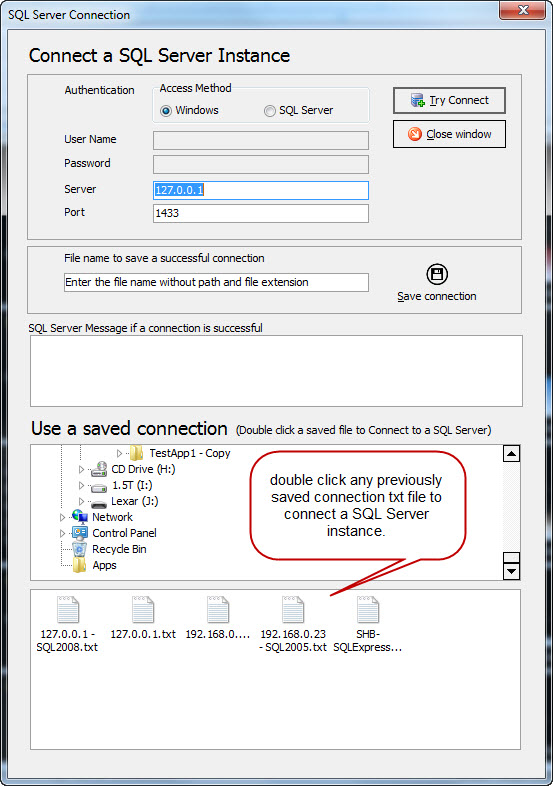
First time connection: To connect a SQL Server instance, click the “SQL Server to Monitor” button. Supply the required information and then click “Try Connect” in the connection dialog box. Once connected, close the connection dialog box or choose another server to connect to. All charts will be populated for an hour with blank data once a connection is made. It continues to collect and display data based on the duration configured on the tool bar. All collected data will be saved in a SQLite database (sqlmonitor.db) for later review and analysis. Using a saved connection: A successful connection can be saved for later use. Once the tool successfully connects to a database server, click the “save connection” button to save the connection string. An encoded text file will be created in the same folder with the “.txt” extension where the “SQLMonitor.exe” resides. From the bottom list box of the “SQL Server Connection” (figure#2) dialog box, double click a previously saved file to connect to a SQL Server instance. Couple of Screenshots from “SQL Performance Monitor”
Figure#2: SQL Server Connection dialog
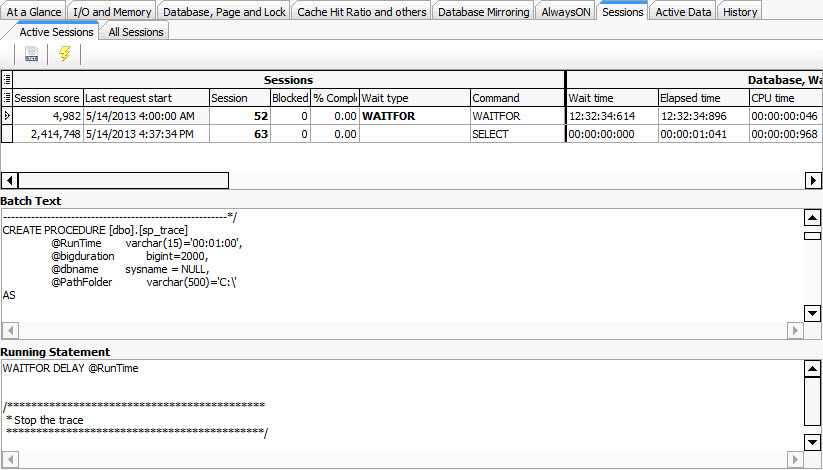
Figure#3A: Viewing all running sessions
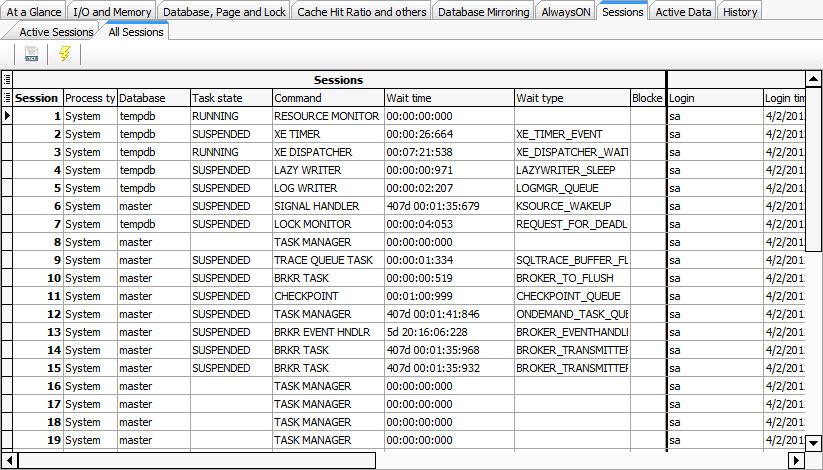
Figure#3B: Viewing all sessions
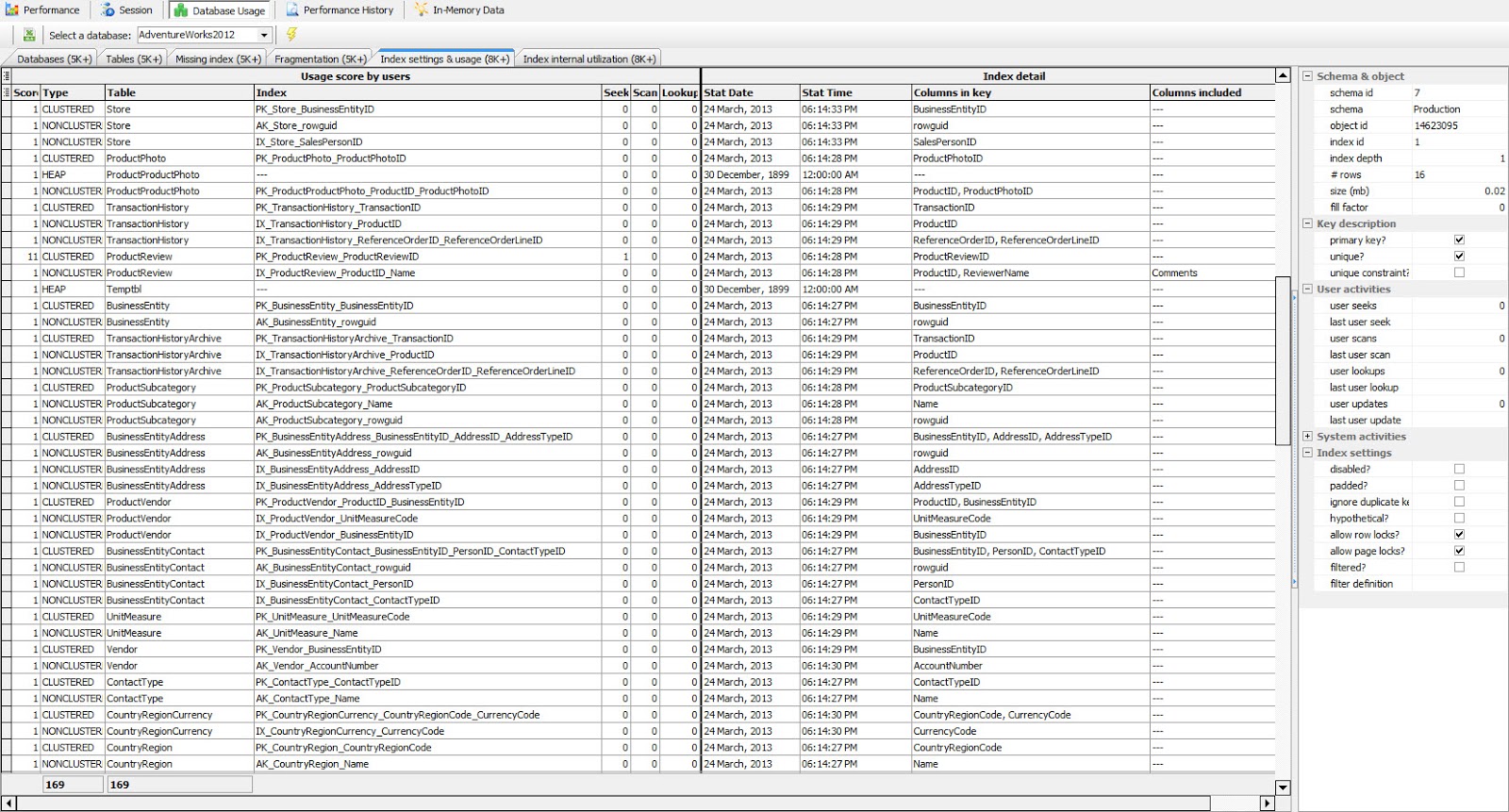
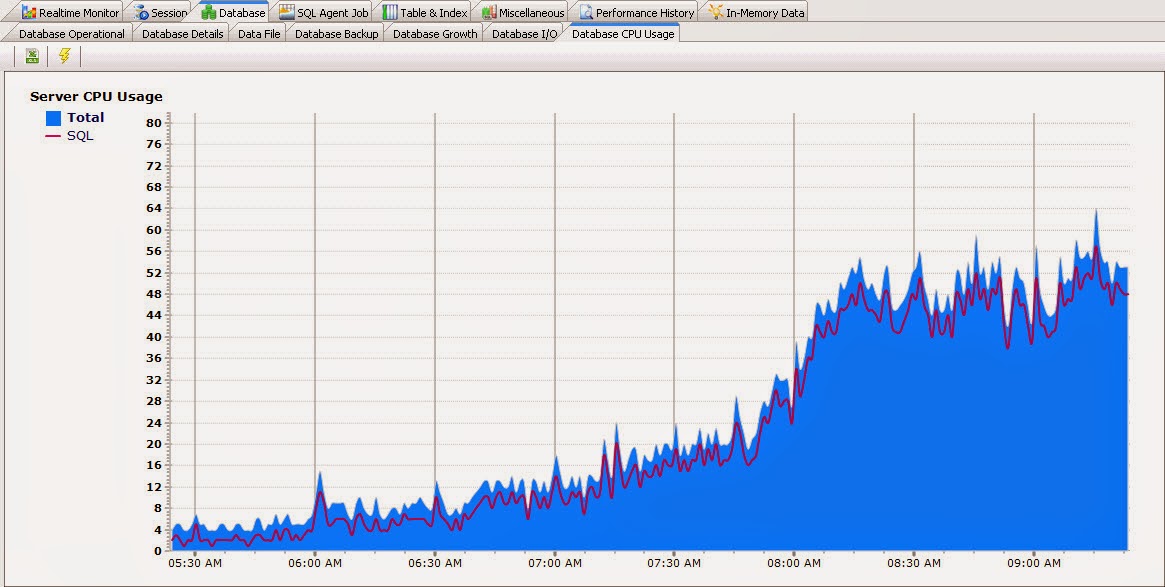
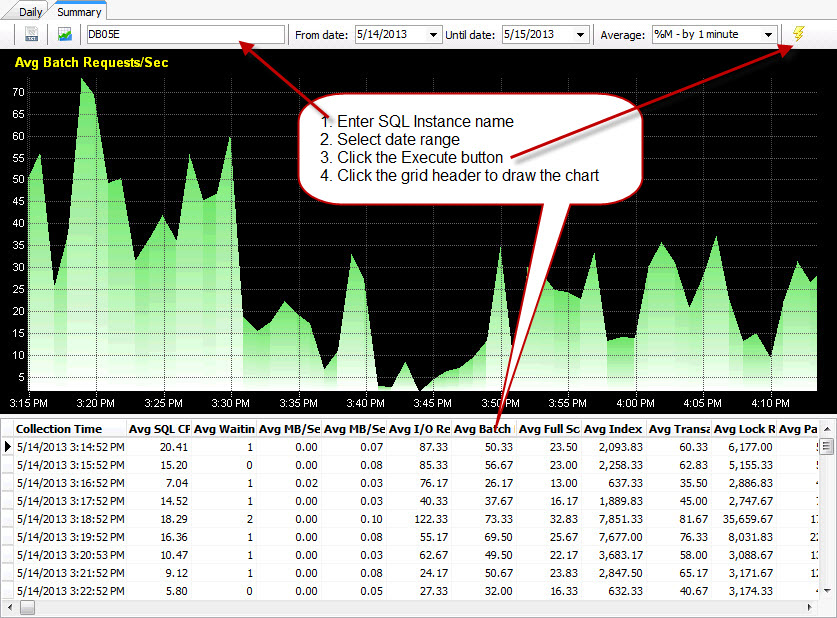
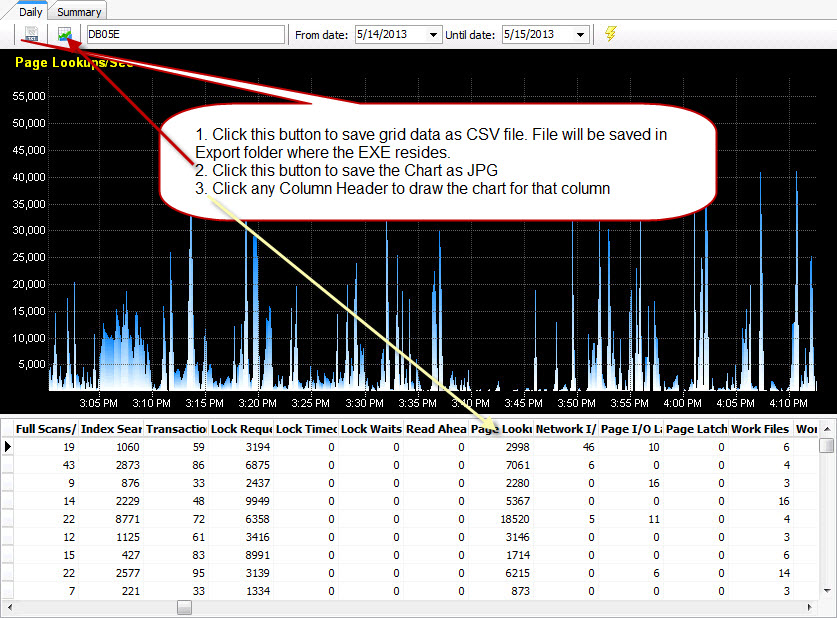
Historical data: In the history tab, put “SQL Instance Name” and “date” to query historical data. Click any column header to view data in the chart. All data and charts can be saved. Figure#4: Historical data browse
SELECT
database_name = DB_NAME(database_id)
, log_size_mb = CAST(SUM(CASE WHEN type_desc = 'LOG' THEN size END) * 8. / 1024 AS DECIMAL(8,2))
, row_size_mb = CAST(SUM(CASE WHEN type_desc = 'ROWS' THEN size END) * 8. / 1024 AS DECIMAL(8,2))
, total_size_mb = CAST(SUM(size) * 8. / 1024 AS DECIMAL(8,2))
FROM sys.master_files WITH(NOWAIT)
WHERE database_id = DB_ID() -- for current db
GROUP BY database_id
ALTER FUNCTION [dbo].[GetDBSize]
(
@db_name NVARCHAR(100)
)
RETURNS TABLE
AS
RETURN
SELECT
database_name = DB_NAME(database_id)
, log_size_mb = CAST(SUM(CASE WHEN type_desc = 'LOG' THEN size END) * 8. / 1024 AS DECIMAL(8,2))
, row_size_mb = CAST(SUM(CASE WHEN type_desc = 'ROWS' THEN size END) * 8. / 1024 AS DECIMAL(8,2))
, total_size_mb = CAST(SUM(size) * 8. / 1024 AS DECIMAL(8,2))
FROM sys.master_files WITH(NOWAIT)
WHERE database_id = DB_ID(@db_name)
OR @db_name IS NULL
GROUP BY database_id
IF OBJECT_ID('tempdb.dbo.#space') IS NOT NULL
DROP TABLE #space
CREATE TABLE #space (
database_id INT PRIMARY KEY
, data_used_size DECIMAL(18,2)
, log_used_size DECIMAL(18,2)
)
DECLARE @SQL NVARCHAR(MAX)
SELECT @SQL = STUFF((
SELECT '
USE [' + d.name + ']
INSERT INTO #space (database_id, data_used_size, log_used_size)
SELECT
DB_ID()
, SUM(CASE WHEN [type] = 0 THEN space_used END)
, SUM(CASE WHEN [type] = 1 THEN space_used END)
FROM (
SELECT s.[type], space_used = SUM(FILEPROPERTY(s.name, ''SpaceUsed'') * 8. / 1024)
FROM sys.database_files s
GROUP BY s.[type]
) t;'
FROM sys.databases d
WHERE d.[state] = 0
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
EXEC sys.sp_executesql @SQL
SELECT
d.database_id
, d.name
, d.state_desc
, d.recovery_model_desc
, t.total_size
, t.data_size
, s.data_used_size
, t.log_size
, s.log_used_size
, bu.full_last_date
, bu.full_size
, bu.log_last_date
, bu.log_size
FROM (
SELECT
database_id
, log_size = CAST(SUM(CASE WHEN [type] = 1 THEN size END) * 8. / 1024 AS DECIMAL(18,2))
, data_size = CAST(SUM(CASE WHEN [type] = 0 THEN size END) * 8. / 1024 AS DECIMAL(18,2))
, total_size = CAST(SUM(size) * 8. / 1024 AS DECIMAL(18,2))
FROM sys.master_files
GROUP BY database_id
) t
JOIN sys.databases d ON d.database_id = t.database_id
LEFT JOIN #space s ON d.database_id = s.database_id
LEFT JOIN (
SELECT
database_name
, full_last_date = MAX(CASE WHEN [type] = 'D' THEN backup_finish_date END)
, full_size = MAX(CASE WHEN [type] = 'D' THEN backup_size END)
, log_last_date = MAX(CASE WHEN [type] = 'L' THEN backup_finish_date END)
, log_size = MAX(CASE WHEN [type] = 'L' THEN backup_size END)
FROM (
SELECT
s.database_name
, s.[type]
, s.backup_finish_date
, backup_size =
CAST(CASE WHEN s.backup_size = s.compressed_backup_size
THEN s.backup_size
ELSE s.compressed_backup_size
END / 1048576.0 AS DECIMAL(18,2))
, RowNum = ROW_NUMBER() OVER (PARTITION BY s.database_name, s.[type] ORDER BY s.backup_finish_date DESC)
FROM msdb.dbo.backupset s
WHERE s.[type] IN ('D', 'L')
) f
WHERE f.RowNum = 1
GROUP BY f.database_name
) bu ON d.name = bu.database_name
ORDER BY t.total_size DESC
use master
DECLARE @xQry NVARCHAR(MAX)=''
SELECT @xQry+= ' UNION ALL SELECT '''+name+''' COLLATE Modern_Spanish_CI_AS AS [Database],
schema_name(tab.schema_id) + ''.'' + tab.name COLLATE Modern_Spanish_CI_AS AS [table],
cast(sum(spc.used_pages * 8)/1024.00 as numeric(36, 2)) as used_mb,
cast(sum(spc.total_pages * 8)/1024.00 as numeric(36, 2)) as allocated_mb
from '+name+'.sys.tables tab
join '+name+'.sys.indexes ind
on tab.object_id = ind.object_id
join '+name+'.sys.partitions part
on ind.object_id = part.object_id and ind.index_id = part.index_id
join '+name+'.sys.allocation_units spc
on part.partition_id = spc.container_id
group by schema_name(tab.schema_id) + ''.'' + tab.name COLLATE Modern_Spanish_CI_AS'
FROM sys.databases
SET @xQry= RIGHT(@xQry,LEN(@xQry)-11) + ' order by 3 desc'
EXEC (@xQry)
MERGE 문을 사용하면 변경할 테이블에 데이터가 존재하는지 체크하고, UPDATE, DELETE, INSERT를 한 번에 작업이 가능하다. MERGE 문을 사용하지 않을 경우 해당 조건으로 테이블을 SELECT 한 후 IF 조건을 사용하여 UPDATE나 INSERT로 분기하는 로직을 작성해야 하는 번거로움이 있다.
MERGE 문의 경우 단일(한개의) 테이블에 UPDATE 또는 INSERT를 하는 경우 많이 사용하지만, 두개의 테이블을 비교하거나 서브 쿼리의 결과에 따라서 UPDATE, INSERT 작업이 가능하다.
MSSQL MERGE 문
단일 테이블 사용법 (DUAL)
오라클에서는 DUAL이라는 dummy 테이블을 USING 절에 사용하면 단일 테이블 작업이 간단하지만, MSSQL에서는 DUAL 테이블이 없기 때문에dummy 서브 쿼리를 사용하면 된다.
MERGE INTO dept AS a
USING (SELECT 1 AS dual) AS b
ON (a.deptno = 50)
WHEN MATCHED THEN
UPDATE SET a.dname = 'IT', a.loc = 'SOUTHLAKE'
WHEN NOT MATCHED THEN
INSERT(deptno, dname, loc) VALUES(50, 'IT', 'SOUTHLAKE')
;
(SELECT 1 AS dual) AS b이부분은 dummy 서브 쿼리 이므로 그대로 복사해서 사용하면 된다.
dept 테이블에 deptno = '50'에 만족하는 값이 있으면 UPDATE, 없으면 INSERT 한다.
DECLARE @deptno INT = 50
DECLARE @dname NVARCHAR(14) = 'IT'
DECLARE @loc NVARCHAR(13) = 'SOUTHLAKE'
MERGE INTO dept AS a
USING (SELECT 1 AS dual) AS b
ON (a.deptno = @deptno)
WHEN MATCHED THEN
UPDATE SET a.dname = @dname, a.loc = @loc
WHEN NOT MATCHED THEN
INSERT(deptno, dname, loc) VALUES(@deptno, @dname, @loc)
;
동일한 쿼리문을 조금 더 이해하기 쉽도록 변수를 사용하여 작성하다.
서브 쿼리를 이용하는 방법
DECLARE @deptno INT = 50
MERGE INTO dept AS a
USING (SELECT DISTINCT
d.deptno AS deptno
, d.dname AS dname
, d.loc AS loc
FROM emp AS e
INNER JOIN dept_history AS d
ON e.deptno = d.deptno
WHERE e.deptno = @deptno) AS b
ON (a.deptno = b.deptno)
WHEN MATCHED THEN
UPDATE SET a.dname = b.dname
, a.loc = b.dname
WHEN NOT MATCHED THEN
INSERT(deptno, dname, loc)
VALUES(b.deptno, b.dname, b.loc)
;
USING 절에 서브 쿼리를 사용하는 방법을 설명한 쿼리이다.
emp 테이블에 deptno = '50'이 존재하고, 서브 쿼리 결과와 dept 테이블을 비교하여 존재 여부에 따라서 UPDATE, INSERT 한다.
두개의 테이블 조인하는 방법
MERGE INTO dept AS a
USING dept_history AS b
ON (a.deptno = b.deptno)
WHEN MATCHED THEN
UPDATE SET a.dname = b.dname
, a.loc = b.loc
WHEN NOT MATCHED THEN
INSERT(deptno, dname, loc)
VALUES(b.deptno, b.dname, b.loc)
;
dept_history 테이블의 값이 dept 테이블에 존재하는 경우, dept_history 테이블의 값으로 UPDATE, 없으면 INSERT 한다.
기타 사용법
ON절에 WHERE 절과 유사하게 AND, OR 를 사용하여 여러개의 조건을 부여할 수 있다.
WHEN절에도 MATCHED, NOT MATCHED 외에 추가로 조건을 부여할 수 있다.
MERGE INTO dept AS a
USING dept_history AS b
ON (a.deptno = b.deptno)
WHEN MATCHED THEN
UPDATE SET a.dname = b.dname, a.loc = b.loc
WHEN NOT MATCHED BY TARGET THEN
INSERT(deptno, dname, loc) VALUES(b.deptno, b.dname, b.loc)
WHEN NOT MATCHED BY SOURCE THEN
DELETE
;
NOT MATCHED 인 경우BY TARGET와BY SOURCE를 사용할 수 있다.
NOT MATCHED BY TARGET(= NOT MATCHED)
TARGET 테이블에 데이터가 없는 경우 TARGET 테이블에 INSERT
NOT MATCHED와 동일 하므로 BY TARGET는 생략해도 된다
NOT MATCHED BY SOURCE
SOURCE 테이블에는 없고 TARGET 테이블에만 존재하는 데이터를 TARGET 테이블에서 DELETE
NOT MATCHED BY SOURCE
DELETE 문에는 WHERE 조건문을 작성하지 않는다.
필요시 WHEN 절에 조건을 작성한다.
MERGE 문 사용 시 주의사항
USING 절에 별칭이 없을 경우
오류 메시지 :키워드 'ON' 근처의 구문이 잘못되었습니다.
쿼리문 끝에 세미콜론이 없을 경우
오류 메시지 :MERGE 문은 세미콜론(;)으로 종료해야 합니다.
USING 절의 데이터에 변경할 테이블과 비교할 테이블의 KEY 컬럼 값이 중복으로 존재 할 경우
오류 메시지 :MERGE 문이 동일한 행을 여러 번 UPDATE 또는 DELETE하려고 했습니다. 대상 행이 둘 이상의 원본 행과 일치하면 이런 경우가 발생합니다. MERGE 문은 대상 테이블의 동일한 행을 여러 번 UPDATE/DELETE할 수 없습니다. ON 절을 구체화하여 대상 행이 하나의 원본 행하고만 일치하도록 하거나 GROUP BY 절을 사용하여 원본 행을 그룹화하십시오.
SQL Server에서 매개 변수 스니핑이란 무엇입니까? 임시 또는 저장 프로 시저를 실행하는 모든 배치는 향후 사용을 위해 계획 캐시에 보관되는 쿼리 계획을 생성합니다. SQL Server는 데이터를 검색하기 위해 최상의 쿼리 계획을 만들려고 시도하지만 계획 캐시의 경우 항상 명확 해 보이는 것은 아닙니다.
SQL Server가 최상의 계획을 선택하는 방법은 비용 추정입니다. 예를 들어 어떤 것이 가장 좋은지 물어 보면 인덱스 검색 후 키 조회 또는 테이블 스캔이 첫 번째로 대답 할 수 있지만 조회 횟수에 따라 다릅니다. 즉, 검색되는 데이터의 양에 따라 다릅니다. 따라서 최상의 쿼리 계획은 입력 매개 변수와 통계를 기반으로 한 카디널리티 추정을 고려합니다.
옵티마이 저가 실행 계획을 생성 할 때 매개 변수 값을 스니핑합니다. 이것은 문제가 아닙니다. 사실 최상의 계획을 세우는 데 필요합니다. 쿼리가 다른 데이터 배포에 최적화 된 이전에 생성 된 계획을 사용할 때 문제가 발생합니다.
대부분의 경우 데이터베이스 워크로드는 동종이므로 매개 변수 스니핑은 문제가되지 않습니다. 그러나 소수의 경우에 이것은 문제가되고 그 결과는 극적 일 수 있습니다.
작동중인 SQL Server 매개 변수 스니핑 이제 예제를 통해 매개 변수 스니핑 문제를 설명하겠습니다.
1. CREATE DATABASE script.
USE [master]
GO
CREATE DATABASE [TestDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'TestDB', FILENAME = N'E:\MSSQL\TestDB.mdf' ,
SIZE = 5MB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = N'TestDB_log', FILENAME = N'E:\MSSQL\TestDB.ldf' ,
SIZE = 5MB , MAXSIZE = 2048GB , FILEGROWTH = 1024KB)
GO
ALTER DATABASE [TestDB] SET RECOVERY SIMPLE
2. Create two simple tables.
USE TestDB
GO
IF OBJECT_ID('dbo.Customers', 'U') IS NOT NULL
DROP TABLE dbo.Customers
GO
CREATE TABLE Customers
(
CustomerID INT NOT NULL IDENTITY(1,1) ,
CustomerName VARCHAR(50) NOT NULL ,
CustomerAddress VARCHAR(50) NOT NULL ,
[State] CHAR(2) NOT NULL ,
CustomerCategoryID CHAR(1) NOT NULL ,
LastBuyDate DATETIME ,
PRIMARY KEY CLUSTERED ( CustomerID )
)
IF OBJECT_ID('dbo.CustomerCategory', 'U') IS NOT NULL
DROP TABLE dbo.CustomerCategory
GO
CREATE TABLE CustomerCategory
(
CustomerCategoryID CHAR(1) NOT NULL ,
CategoryDescription VARCHAR(50) NOT NULL ,
PRIMARY KEY CLUSTERED ( CustomerCategoryID )
)
CREATE INDEX IX_Customers_CustomerCategoryID
ON Customers(CustomerCategoryID)
3. The idea with the sample data is to create an odd distribution.
USE TestDB
GO
INSERT INTO [dbo].[Customers] (
[CustomerName],
[CustomerAddress],
[State],
[CustomerCategoryID],
[LastBuyDate])
SELECT
'Desiree Lambert',
'271 Fabien Parkway',
'NY',
'B',
'2013-01-13 21:44:21'
INSERT INTO [dbo].[Customers] (
[CustomerName],
[CustomerAddress],
[State],
[CustomerCategoryID],
[LastBuyDate])
SELECT
'Pablo Terry',
'29 West Milton St.',
'DE',
'A',
GETDATE()
go 15000
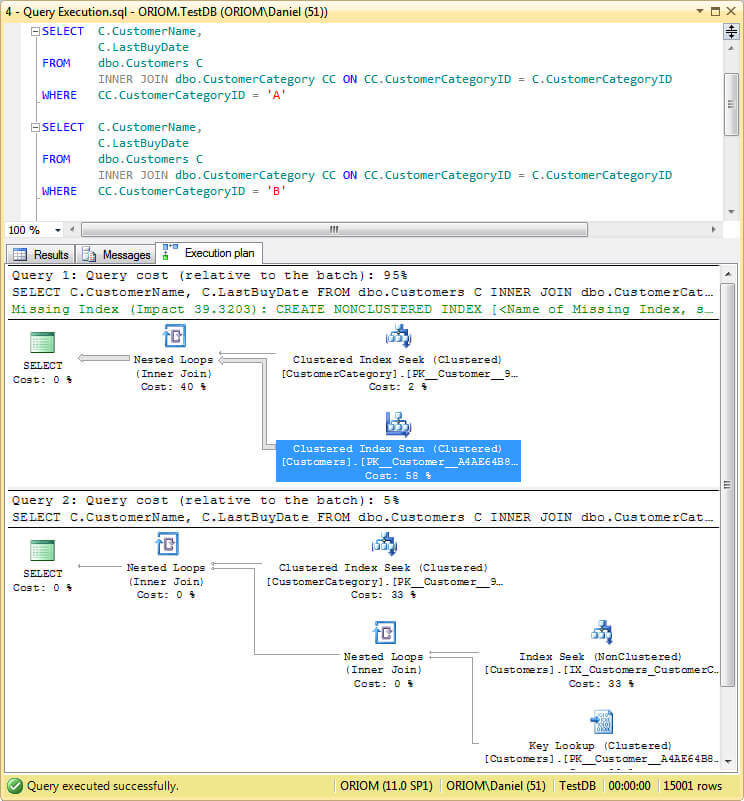
4. Execute the following query and take a look at the query plan.
USE TestDB
GO
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = 'A'
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = 'B'
보시다시피 첫 번째 쿼리는 CustomersCategory 테이블에서 클러스터형 인덱스 검색을 수행하고 tghe Customers 테이블에서 클러스터형 인덱스 스캔을 수행하는 반면 두 번째 쿼리는 비 클러스터형 인덱스 (IX_Customers_CustomerCategoryID)를 사용합니다.그 이유는 쿼리 최적화 프로그램이 주어진 매개 변수에서 쿼리 결과를 예상 할 수있을만큼 똑똑하고 인덱스 검색을 수행 한 후 비 클러스터형 인덱스에 대한 키 조회를 수행하는 대신 클러스터형 인덱스를 스캔하기 때문에 비용이 더 많이 듭니다. 첫 번째 쿼리는 거의 전체 테이블을 반환합니다.
5. Now we create a stored procedure to execute our query.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
GO
6. Execute the stored procedure.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
스크립트에서 먼저 DBCC FREEPROCCACHE를 실행하여 계획 캐시를 정리 한 다음 저장 프로 시저를 실행합니다.아래 이미지를 보면 저장된 프로 시저에 대한 두 번째 호출이 주어진 매개 변수를 고려하지 않고 동일한 계획을 사용하는 방법을 볼 수 있습니다.
그런 다음 동일한 단계를 수행하지만 매개 변수를 역순으로 사용하면 동일한 동작이 표시되지만 쿼리 계획은 다릅니다.
SQL Server 매개 변수 스니핑에 대한 해결 방법
이제 문제를 해결하는 몇 가지 방법이 있습니다.
WITH RECOMPILE 옵션을 사용하여 SQL Server 저장 프로 시저 만들기
SQL Server 힌트 옵션 사용 (권장)
SQL Server 힌트 옵션 (OPTIMIZE FOR) 사용
SQL Server 저장 프로 시저에서 더미 변수 사용
인스턴스 수준에서 SQL Server 매개 변수 스니핑 비활성화
특정 SQL Server 쿼리에 대한 매개 변수 검색 비활성화
WITH RECOMPILE 옵션을 사용하여 SQL Server 저장 프로 시저 만들기
문제가 옵티마이 저가 더 이상 적합하지 않은 매개 변수로 컴파일 된 계획을 사용하는 것이라면 재 컴파일은 새 매개 변수로 새 계획을 생성 할 것입니다. 맞습니까?이것은 가장 간단한 해결책이지만 최고는 아닙니다.문제가 저장 프로 시저 코드 내의 단일 쿼리 인 경우 전체 프로 시저를 다시 컴파일하는 것이 최선의 방법이 아닙니다.문제가있는 쿼리를 수정해야합니다.
또한 재 컴파일은 CPU 부하를 증가시킬 것이며 동시 시스템이 많은 경우 우리가 해결하려는 문제만큼 문제가 될 수 있습니다.
예를 들어, 다음은 재 컴파일 옵션을 사용하여 이전 저장 프로 시저를 만드는 샘플 코드입니다.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Recompile
@CustomerCategoryID CHAR(1)
WITH RECOMPILE
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
GO
SQL Server 힌트 옵션 사용 (권장)
이전 단락에서 말했듯이 전체 저장 프로 시저를 다시 컴파일하는 것은 최선의 선택이 아닙니다.힌트 RECOMPILE을 활용하여 어색한 쿼리 만 다시 컴파일 할 수 있습니다.아래 샘플 코드를보십시오.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Query_Hint_Option_Recompile
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
OPTION(RECOMPILE)
GO
이제 다음 코드를 실행하고 쿼리 계획을 살펴보십시오.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Query_Hint_Option_Recompile @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Query_Hint_Option_Recompile @CustomerCategoryID
GO
이전 이미지에서 볼 수 있듯이 두 쿼리의 매개 변수에 따라 올바른 계획이 있습니다.
SQL Server 힌트 옵션 (OPTIMIZE FOR) 사용
이 힌트를 통해 최적화를위한 참조로 사용할 매개 변수 값을 설정할 수 있습니다.SQL Server OPTIMIZE FOR Hint를 사용하여 매개 변수 기반 쿼리를 최적화하는 Greg Robidoux의 팁에서이 힌트를 읽을 수 있습니다.우리 시나리오에서는 프로 시저가 실행하는 데 사용할 매개 변수 값을 알지 못하기 때문에이 힌트를 사용할 수 없습니다.그러나 SQL Server 2008 이상을 사용하는 경우 OPTIMIZE FOR UNKNOWN은 약간의 빛을 가져옵니다.평신도 용어로 말하면 최상의 계획을 만들지 못할 것이라는 점을 경고해야합니다. 그 결과 계획은 중간에있을 것입니다.따라서이 힌트를 사용하려면 저장 프로 시저가 잘못된 계획으로 실행되는 빈도와 쿼리가 오래 실행되는 환경에 미치는 영향을 고려해야합니다.
이 힌트를 사용하는 샘플 코드는 다음과 같습니다.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Query_Hint_Optimize_Unknown
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
OPTION(OPTIMIZE FOR UNKNOWN )
GO
The next script is to execute our new Stored Procedure.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Query_Hint_Optimize_Unknown @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Query_Hint_Optimize_Unknown @CustomerCategoryID
GO
다음은 실행 계획의 화면 캡처입니다.
SQL Server 저장 프로 시저에서 더미 변수 사용
이것은 2005 년 이전의 SQL Server 버전에서 사용 된 오래된 방법입니다. 입력 매개 변수를 로컬 변수에 할당하고 매개 변수 대신이 변수를 사용합니다.
아래 샘플 코드를보십시오.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Dummy_Var
@CustomerCategoryID CHAR(1)
AS
DECLARE @Dummy CHAR(1)
SELECT @Dummy = @CustomerCategoryID
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @Dummy
GO
To execute this Stored Procedure you can use this code.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Dummy_Var @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Dummy_Var @CustomerCategoryID
GO
이것은 사용자에게 알려지지 않았을 수 있지만 쿼리는 추적 플래그를 힌트로 사용하여 쿼리 최적화 프로그램의 동작을 변경할 수 있습니다.이를 수행하는 방법은 OPTION 절에QUERYTRACEON힌트를추가하는것입니다.
다음은 샘플 저장 프로 시저와 그 실행입니다.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Query_Hint_QUERYTRACEON
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
OPTION(QUERYTRACEON 4136)
GO
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Query_Hint_QUERYTRACEON @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Query_Hint_QUERYTRACEON @CustomerCategoryID
GO
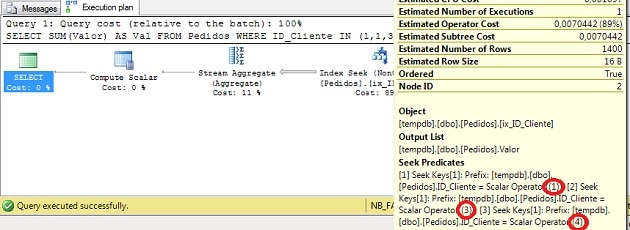
이제 데이터가 있으므로 merge interval을 확인하는 쿼리를 작성할 수 있습니다.다음 쿼리는 4 명의 고객에 대한 매출액을 선택합니다.
SELECTSUM(Valor)ASVal
FROMPedidos
WHEREID_ClienteIN(1,2,3,4)
GO
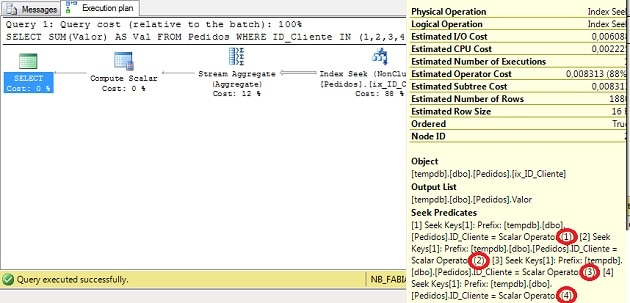
위 쿼리의 경우 다음과 같은 실행 계획이 있습니다.
그림 1 – 실행 계획 (전체 크기로 보려면 클릭)
위의 실행 계획에서 QO가 인덱스ix_ID_Cliente를 사용하여 IN 절에 지정된각ID_Cliente에대한 데이터를 검색한 다음Stream Aggregate를 사용하여 합계를 수행하는 것을 볼 수있습니다.
이것은 고전적인 Index Seek 작업으로, 각 값에 대해 SQL Server는 데이터를 읽고 균형 잡힌 인덱스 트리에서ID_Cliente를검색합니다.지금은 merge interval이 필요하지 않습니다.
이제 유사한 쿼리를 살펴 보겠습니다.
DECLARE@v1Int=1,
@v2Int=2,
@v3Int=3,
@v4Int=4
SELECTSUM(Valor)ASVal
FROMPedidos
WHEREID_ClienteIN(@v1,@v2,@v3,@v4)
GO
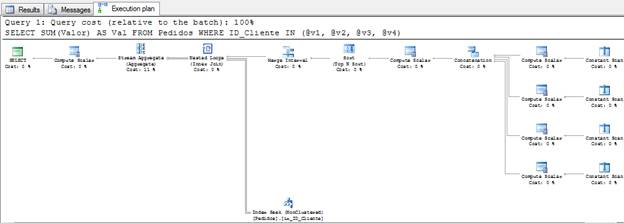
위 쿼리의 경우 다음과 같은 실행 계획이 있습니다.
그림 2 – 실행 계획 (전체 크기로 보려면 클릭)
보시다시피 쿼리 간의 유일한 차이점은 이제 상수 값 대신 변수를 사용하고 있지만 쿼리 최적화 프로그램은이 쿼리에 대해 매우 다른 실행 계획을 생성한다는 것입니다.그래서 질문 : 당신은 어떻게 생각하십니까?SQL이이 쿼리에 대해 동일한 실행 계획을 사용해야한다고 생각하십니까?
정답은 아니오입니다. 왜 안됩니까?컴파일 타임에 SQL Server는 상수 값을 모르고 값이 중복 된 것으로 판명되면 동일한 데이터를 두 번 읽습니다.@ v2의 값도 "1"이라고 가정하면 SQL이 ID 1을 두 번 읽습니다. 하나는 변수@ v1이고 다른 하나는 변수@ v2입니다. 성능을 기대하기 때문에 볼 수 없을 것입니다. 같은 데이터가 두 번이면 좋지 않습니다.따라서 Merge Interval을 사용하여 중복 발생을 제거해야합니다.
이 시점에서 몇 가지 질문이 떠오를 수 있습니다.첫째 : SQL Server가 IN 변수에 DISTINCT를 사용하여 조인을 제거하지 않는 이유는 무엇입니까?둘째 : 이것이“병합”이라고 불리는 이유는 여기에서 합병과 관련된 어떤 것도 보지 못했습니다.
대답은 쿼리 최적화 프로그램 (QO)이이 연산자를 사용하여 DISTINCT를 수행한다는 것입니다.이 코드를 사용하면 QO가 겹치는 간격도 인식하고 잠재적으로이를 겹치지 않는 간격에 병합하여 값을 찾는 데 사용할 수 있기 때문입니다.이를 더 잘 이해하기 위해 변수를 사용하지 않는 다음 쿼리가 있다고 가정 해 보겠습니다.
SELECTSUM(Valor)ASVal
FROMPedidos
WHEREID_ClienteBETWEEN10AND25
ORID_ClienteBETWEEN20AND30
GO
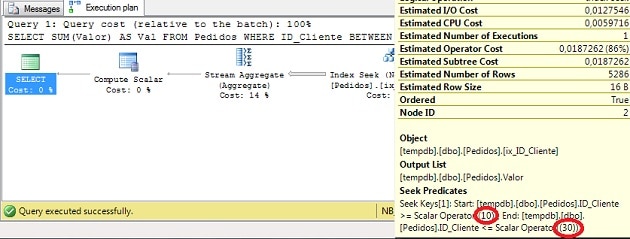
이제 실행 계획을 살펴 보겠습니다.
그림 4 – 실행 계획 (전체 크기로 보려면 클릭)
Query Optimizer가 얼마나 똑똑했는지 주목하십시오.(그래서 내가 그것을 좋아하는 이유입니다!) 술어 사이의 겹침을 인식하고 인덱스에서 두 번의 탐색을 수행하는 대신 (필터 사이에 하나씩) 하나의 탐색 만 수행하는 계획을 만듭니다.
이제 변수를 사용하도록 쿼리를 변경해 보겠습니다.
DECLARE@v_a1Int=10,
@v_b1Int=20,
@v_a2Int=25,
@v_b2Int=30
SELECTSUM(Valor)ASVal
FROMPedidos
WHEREID_ClienteBETWEEN@v_a1AND@v_a2
ORID_ClienteBETWEEN@v_b1AND@v_b2
GO
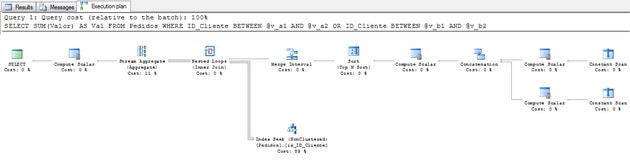
이 쿼리의 경우 다음 실행 계획이 있습니다.
그림 5 – 실행 계획 (전체 크기로 보려면 클릭)
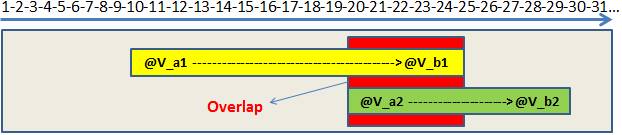
다른 관점을 사용하여 계획이 무엇을하고 있는지 확인합시다.먼저 겹치는 부분을 이해합시다.
그림 6 – 20에서 25 사이의 겹침
그림 6에서 SQL Server가 범위를 개별적으로 읽는 경우 20에서 25까지의 범위를 두 번 읽는 것을 볼 수 있습니다.테스트에 작은 범위를 사용했지만 프로덕션 데이터베이스에서 볼 수있는 매우 큰 스캔의 관점에서 생각합니다.이 단계를 피할 수 있다면 성능이 크게 향상 될 것입니다.
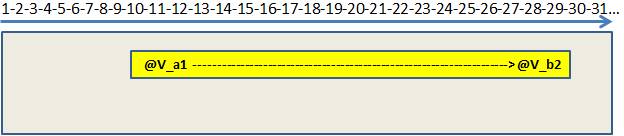
그림 7 – 병합 간격 후
병합 간격이 실행 된 후 SQL Server는 최종 범위 만 검색 할 수 있습니다.@ v_a1에서@ vb_2로직접이동할 수 있음을 알고있습니다.
이것은 무엇을 의미 하는가?이는 반복기가 단일 작업을 수행하는 객체임을 의미합니다.예를 들어 테이블의 데이터를 스캔하거나 테이블의 데이터를 업데이트 할 수 있지만 둘 다 수행 할 수는 없습니다. 그래서반복자 당 하나의 데이터베이스 작업, 그것이 우리가 기억해야 할 정의입니다. 단일 연산자가 그다지 유용하지 않다고 상상할 수 있습니다.일반적으로 아무도 단일 작업을 수행하지 않습니다. 이것이 반복자가 쿼리 계획이라고하는 트리에서 결합되는 이유입니다.쿼리 계획은 각각 자체 작업을 수행하는 여러 반복기 (또는 연산자)로 구성됩니다.
쿼리 계획은 트리 구조이므로 연산자는 자식 (0 개 이상)을 가질 수 있습니다. SQL Server는 각 쿼리를 최적화하려고합니다. 즉, 가장 저렴하거나 가장 빠르게 수행 할 수있는 특정 쿼리에 대해 최상의 반복기 조합을 찾으려고합니다.
반복자는 무엇을합니까?
각 연산자는 다음 세 가지를 수행합니다.
먼저 입력 행을 읽습니다.행은 데이터 소스 또는 연산자의 하위에서 올 수 있습니다.
그런 다음 행을 처리합니다.이것은 반복기의 유형에 따라 다른 것을 의미 할 수 있습니다.
마지막으로 출력을 부모에게 반환합니다.
처리 유형
반복자가 수행 할 수있는 두 가지 유형의 처리가 있습니다.
한 번에 한 행 (또는행 기반 처리). 즉, 해당 반복기에 해당하는 작업이 반복기에 들어가는 각 행에 적용됨을 의미합니다.
그리고배치 모드 처리.이는 연산자가 한 번에 한 행이 아닌 전체 행 일괄 처리를 처리하는 SQL Server 2012에 도입 된 접근 방식입니다.
행 기반 모델
반복기는 메서드와 속성의 공통 인터페이스를 공유하는 코드 개체입니다.가장 자주 사용되는 방법은 행을 처리하고, 속성 정보를 설정 및 검색하고, 최적화 프로그램이 사용할 비용 추정치를 생성하는 데 사용되는 방법입니다.
행 기반 모델에서 모든 반복기는 다음과 같은 동일한 핵심 메서드 집합을 구현합니다.
Open(출력 행 생성을 시작할 때임을 운영자에게 알리는 메서드)
GetRow(연산자에게 새 행을 생성하도록 요청)
그리고Close메서드는 반복기의 부모가 행 요청을 완료했음을 나타냅니다.
모든 반복기는 동일한 구조를 갖기 때문에 서로 독립적으로 작동 할 수 있음을 의미합니다.
이제 쿼리 계획을 살펴보고 하나 이상의 반복기와 이들이 결합되는 방식을 살펴 보겠습니다.
예를 들어 SELECT COUNT (*) FROM Products를 수행하면 내 계획이 이렇게 생겼습니다.
지금 당장 익숙하지 않더라도 걱정하지 마세요. 몇 개의 클립을 더 추가하면 모두 이해하기 시작합니다.
계획을 읽는 방법에는 두 가지가 있습니다.
다음제어 흐름왼쪽에서 오른쪽으로.즉, Open, GetRow 및 Close 메서드가 쿼리 트리의 루트 노드부터 호출되고 결과가 리프 반복기로 전파됩니다.
그리고오른쪽 하단에서 왼쪽 상단까지의데이터 흐름을따릅니다.이것은 데이터가 검색되는 방식입니다.
그래서 우리의 예로 돌아갑니다.내 Products 테이블의 모든 행을 계산하기 위해 두 개의 연산자가 사용됩니다.
테이블에서 모든 행을 가져 오는 하나.이것은 Products 테이블이스캔됨을 의미합니다.
그리고그들을세는하나.앞서 말했듯이 운영자 당 하나의 작업 만 수행 할 수 있습니다.
여기서 무슨 일이 일어나고 있습니까?
작업 순서가있는 그림을 살펴보면 각 단계에 대한 설명이 아래에 있습니다.
먼저 SQL Server는 계획의 루트 반복기에서Open을호출합니다.이 예에서는 COUNT (*) 반복기입니다.COUNT (*) 반복기는 Open 메서드에서 다음 작업을 수행합니다.스캔 반복기에서Open을호출하여 행을 생성 할 시간임을 스캔에 알립니다.비.검색 반복기에서GetRow를반복적으로호출하여 반환 된 행을 계산하고 GetRow가 모든 행을 반환했음을 나타내는 경우에만 중지합니다.C.스캔 반복기에서Close를호출하여 행 가져 오기를 완료했음을 나타냅니다.
COUNT (*) 반복자의 Open 메서드에서 반환 될 때 이미 Products 테이블의 행 수를 알고 있습니다.
그러면 COUNT (*)의GetRow메서드가 실행되어 결과를 반환합니다.
SQL Server는 COUNT (*)가 단일 행을 생성한다는 사실을 모르기 때문에 다른GetRow메서드 호출이 이어집니다.그만한 가치는 다른 모든 행과 마찬가지로 더 이상이 없을 때까지 모든 행을 처리하는 연산자입니다.
두 번째 GetRow 호출에 대한 응답으로 COUNT (*) 반복기는 결과 집합의 끝에 도달했음을 반환합니다.마지막으로 이것은Close메서드의 호출을 의미합니다.COUNT (*) 반복기는 스캔 반복기에서 행을 계산하고 있다는 사실을 신경 쓰거나 알 필요가 없습니다.하위 트리가 얼마나 단순하거나 복잡한 지에 관계없이 SQL Server가 하위 트리에 배치하는 모든 하위 트리의 행을 계산합니다.