B 노드에서 SMK를 읽기 위해서는 DAPI를 사용하는데, 이는 SQL Server의 자격 증명으로부터 파생된 키를 이용하게 됩니다.
즉 이로 인해 동일 서비스 계정이 아닐 경우에는 SMK의 복원 자체가 불가능합니다.
만약 강제로 복원을 시도하는 경우에는 SMK가 재 생성되는 것과 마찮가지로써, 크리덴셜을 이용하는 링크드 서버 및 기타 인증서를 이용한 암호화 구성에 문제가 발생할 수 있습니다.
[현상]
Veritas/Legato 클러스터에 Fail over 직후에 Linked Server 등이 연결이 안된다.
메세지 15466, 수준 16, 상태 2
[원인]
SMK 정보 변경
연결된 서버 암호, 인증서 또는 데이터베이스 마스터 키를 처음으로 암호화할 필요가 있을 때 자동으로 생성됨
SMK는 로컬 시스템 키 또는 Windows 데이터 보호 API(DAPI)를 사용하여 암호화된다. 이 API는 SQL Server 서비스 계정의 Windows 자격 증명으로부터 파생된 키를 사용한다.
서비스 마스터 키의 암호는 해당 키가 만들어진 서비스 계정이나 해당 서비스 계정의 Windows 자격 증명에 대한 액세스 권한이 있는 보안 주체에 의해서만 해독될 수 있다. 따라서 SQL Server 서비스를 실행 중인 Windows 계정을 변경하면 서비스 마스터 키의 암호 해독도 새 계정으로 활성화해야 한다.
[해결 방안]
1. 서비스를 Fail back 한다.
2. SMK를 백업 한다.
3. 두 노드 모두 SQL 서버의 시작 계정을 도메인 계정으로 변경 한다. (해당 작업은 동일 머신 상에서 진행 되어야 합니다.)
4. 연결 오류 발견 시 기존에 백업했던 SMK를 복원 한다.
[기타]
- 백업 및 복원
BACKUP SERVICE MASTER KEY TO FILE = 'c:\service_master_key' ENCRYPTION BY PASSWORD = 'password'
RESTORE SERVICE MASTER KEY FROM FILE = 'c:\service_master_key' DECRYPTION BY PASSWORD = 'password' -- [FORCE]
- 재생성
ALTER SERVICE MASTER KEY REGENERATE
- 계정 변경
ALTER SERVICE MASTER KEY WITH OLD_ACCOUNT = 'old_service_account', OLD_PASSWORD = 'old_service_account_password'
DBA가 관리하고 있는 DBMS에 특정 저장프로시저가 재컴파일 되면서 뜻하지 않게 원하지 않는 플랜 즉, 잘못된 플랜이 만들어 지면서 서버의 리소스를 소비하는 현상을 경험한 적이 있는 DBA 분들이 있을꺼에요. (없다고요?? 그럼 경험해 보셔야 해요. ^^;;;)
아무튼 우리 회사에서도 특정 저장프로시저가 재컴파일 되면서 INDEX SEEK를 해야 함에도 INDEX SCAN으로 플랜이 만들어지고 이로 인해서 서버의 리소스가 사용률이 약간 상승하는 일이 비일비재 해요. 이를 해결하기 위하여 여러가지 방법이 있겠지만, 전 왠지 이런 방법은 없을까? 라는 생각을 해봤어요.
특정 프로시저 즉, 관심대상이 되는 프로시저의 플랜을 저장해 두었다가 현재 캐쉬되어 실행되고 있는 플랜의 물리적 연산자와 저장해둔 플랜의 물리적 연산자가 틀려지게 되면 알 수 있는 방법이 없을까?
그래서 만들고 있지요.
- 특정 프로시저들의 플랜을 저장한다. (물론 테이블을 만들어서)
- 현재 캐쉬되고 실행되는 플랜의 물리적 연산자와 저장된 플랜의 물리적 연산자와 비교 한다.
- 동일하면 일치라는 메시지를 출력한다.
- 동일하지 않다면 현재 캐쉬되어 실행되고 있는 플랜의 물리적 연산자 중 SCAN 이라는 물리적 연산자가 있으면 몇 개가 있고 그 물리적 연산자로 출력되는 예상 행수가 몇 개인지 출력한다.
[위 스크린샷이 저장해 놓은 플랜과 현재 캐쉬되어 실행되고 있는 플랜과 동일할 경우 출력되는 메시지 입니다.]
[위 스크린샷이 저장해 놓은 플랜과 현재 캐쉬되어 실행되고 있는 플랜이 동일 하지 않다면 SCAN 정보를 출력하는 메시지 입니다.]
두번째 스크린샷의 연산자 해석 방법은 해당 플랜의 SCAN의 포함되어 있는 물리적 연산자는 Clustered Index Scan 과 Table Scan 이 있으며, Clustered Index Scan 은 해당 플랜에서 총 3번이 있으며 그 3번의 평균 예상행수는 26만건 이며, Table Scan은 해당 플랜에 총 1번 있으며 그 1번의 예상행수는 45건 이라는 의미입니다. 해당 로직을 사용해 보고 공유할 만한 스크립트가 만들어 지면 올리겠습니다. 근데 멋있지 않나요?? 저만 멋있는건가요 ㅜ.ㅜ;;
특정 프로시저가 재 컴파일이 되면서 실행계획에 문제가 발생하면 CPU 사용률이 급격히 올라가기에 이 현상을 모니터링 하기 위해서 만들었고, 스크립트는 아래와 같습니다.
시작은 이랬습니다. DMV로 실행계획을 볼수 있고, 해당 실행계획은 XML로 되어 있으니 해당 XML에 있는 물리적 연산자를 몽땅 추출하여 내가 원하지 않는 연산자가 있는지 없는지를 알면 되지 않을까?
SELECT
-- d.plan_handle ,
OBJECT_NAME(b.objectid,b.dbid)[SP명],
c.query_planAS[프로시저 전체 실행계획]
-- d.usecounts AS [실행계획이 만들어 진 이후로 사용된 횟수] ,
-- b.text AS [프로시저 내용] ,
--'EXEC ' + DB_NAME( b. dbid ) + '.DBO.sp_recompile ' + OBJECT_NAME ( b. objectid, b.dbid ) AS [ReCompile] ,
보시는봐와 같이 해당 프로시져 플랜의 연산자는 총 83개 중에 간간히 Clustered Index Scan 연산자를 이용하여 40만건이 넘는 행수를 읽고 있는게 보입니다. 그럼 Clustered Index Scan 이던 Table Scan 이던 해당 플랜 안에 Scan이 몇 개나 있고 그 예상행수는 얼마나 되는지를 판단하기 위하여 아래와 같은 최종 형태의 스크립트를 실행하시면 ...
해당 프로시저에 Clustered Index Scan 이 4건이 있으며 그 4건에 대한 평균 예상행수는 20만건이 있다고 출력을 해주고 있습니다. 그럼 이제 정상적인 플랜을 미리 저장해 두고 해당 스크립트로 현재 돌아가고 있는 플랜의 연산자를 추출하여 비교하면 어떤 연산자가 새로 생겼는지 기존에는 어떻게 돌고 있다가 재 컴파일 되면서 지금은 이렇게 돌고 있구나 라고 판단하실 수 있을 겁니다.
SQL Server 데이터베이스 엔진은 자동으로 현재의 데이터베이스버퍼캐시에 있는 데이터를 디스크로 기록하는 CHECKPOINT 명령을 실행한다.
SQL Server 엔진은 성능상의 이유로 변경 내용이 있을 때마다메모리(버퍼캐시)에서 데이터베이스 페이지를 수정하며 이러한페이지를 디스크에 기록하지는 않는다. 대신 데이터베이스 엔진은 각 데이터베이스에서 정기적으로 CHECKPOINT를 실행 한다. CHECKPOINT는 현재 메모리내의 수정된 페이지(더티페이지)와 메모리의 트랜잭션 로그정보를 디스크에 쓰고 트랜잭션 로그에 대한 정보도 기록한다.
이 기능은 SQL Server의 예기치 않은 장애나 시스템 충돌로인하여 데이터베이스를 복구하는데 데이터의 안정성 및 시간을 절약할 수 있는 방법이 된다.
[SQLServer:Buffer Manager] – [Page life expectancy]에 위치하며 페이지가 버퍼풀에 머무르는 시간을 나타낸다. 페이지가 버퍼풀에 오래 머무를수록 디스크를 액세스하는 빈도가 낮아지며 메모리에서 데이터를 읽기 때문에 성능상 이점이 있다. Page life expectancy 계속해서 낮게 나온다면 메모리를 추가할 것을 고려해야 한다. MS백서에서는 임계값을 300(5분)으로 안내하고 있지만 이는 2006년에 권장한 값으로 각자의 시스템에 따라 유동적인 임계값을 설정할 필요가 있다. 중요한것은 임계값이 아니라 유동적인 변화를 파악하는데 있다.
SQLServer:Memory Manager
[SQLServer:Memory Manager]에 위치하며 이 카테고리의 값은 SQL Server 프로세스 내에서 메모리가 어떻게 사용되는지를 나타낸다. 카운터에 표시되는 값 자체를 다른것과 비교 할 수는 없지만 어떠한 변화를 가지는지 동향을 살펴보고 어느 부분에서 압력을 받고 있는지 파악하여야 한다.
Memory Grants Pending
[SQLServer:Memory Manager] – [Memory Grants Pending]에 위치하며 작업 영역 메모리 부여를 대기 중은 현재 프로세스 수를 나타낸다. 메모리 부여 대기는 블록킹을 이해하기 위해 특히 중요한 부분으로 주의해서 보아야 한다. 특정 고부하 쿼리 및 연산이 큰 쿼리는 많은 메모리를 요구한다. 이때 Memory Grants Pending 이 발생하고 대기가 발생한다.
Memory grant queue waits
[SQLServer:Wait Statistics]에 위치하며 메모리 부여를 기다리는 프로세스에 대한 통계이다.
Private Bytes
[Process] – [Private Bytes]에 위치하며 프로세스가 할당하여 다른 프로세스와는 공유할 수 없는 메모리의 현재 크기(byte)를 나타낸다. 이 카운터의 값을 확인하여 SQL Server 외부 메모리 부족으로 인한 성능 저하의 원인인 다른 프로세스를 추적 할 수 있다.
[CPU]
Processor Object
[Processor]에 위치하며 객체들은 OS의 CPU 사용량을 나타낸다.
Page lookups/sec
[SQLServer:Buffer Manager] – [Page lookups/sec]에 위치하며 CPU 사용량을 분석할 때 중요한 카운터 이다. 이 카운터는 버퍼 풀에서 페이지를 찾기 위한 요청 수를 나타낸다. 이 카운터의 값이 증가할 때는 CPU의 사용량이 증가한다. 더 많은 페이지를 스캔하고 더 많은 데이터를 사용하기 때문에 더 많은 CPU를 사용한다. 일반적으로 Page lookup/sec이 큰 경우에는 테이블 스캔(인덱스 누락, 잘못된 설계)이 발생한 경우이다.
Processor Time
[Process] – [% Processor Time]에 위치하며 모든 프로세스 스레드가 프로세서를 사용하여 컴퓨터 명령을 실행하는데 경과된 시간의 백분율을 나타낸다. 일부 하드웨어 인터럽트 또는 트랩 상태를 처리하기 위해 실행되는 코드도 이 계산에 포함된다. 프로세서 시간이 크다면 SQL Server 성능 저하 원인을 CPU를 소비하는 다른 프로세스를 추적해 보아야 한다.
동기 커밋 모드에서 기본 복제본은 모든 동기 보조 복제본이 로그에서 커밋 강화를 완료했다는 확인을받을 때까지 트랜잭션을 커밋하지 않습니다. HADR_SYNC_COMMIT 대기 유형 은 1 차 복제본이 2 차 복제본으로 로그 레코드를 전송하고 2 차 복제본이이 레코드를 수신하여 강화한 후 1 차 복제본으로 승인을 다시 보내는 데 걸린 시간을 반영 합니다.
이 대기 에는 보조 복제본에서 로그 레코드를 다시 실행하는 데 걸리는 시간이 포함 되지 않습니다 .
보조 복제본이 승인을 기본으로 다시 전송 하고 기본 복제본의 로그 전송 큐가 비어 있으면 보조 복제본의 상태가 동기화에서 동기화 됨으로 전환됩니다. HADR_SYNCHRONIZING_THROTTLE의 대기 유형은 측정 이 전환에 걸리는 시간을.
조사
환경에 일반적인 문제가 있는지 확인하려면 분석 페이지에서 다음 메트릭을 확인하십시오. 지침 값과 가능한 솔루션은 각 메트릭의 설명 탭을 참조하십시오.
흐름 제어 시간
흐름 제어는 기본에서 보조로 로그 레코드가 전송되는 속도를 제한 할 수 있습니다. 흐름 제어 시간에 대한 높은 값과 결과적으로 전송되는 로그 바이트 비율이 낮 으면 HADR_SYNC_COMMIT 대기에 기여합니다.
로그 바이트 플러시 / 초 ( 가용성 그룹 개요에서 로그 증가 ), 로그 전송 큐 및 로그 바이트 수신 / 초 ( 가용성 그룹 개요에서 수신 된 비율 )
기본 복제본에서 플러시 된 로그 바이트 비율이 비율보다 높은 경우 로그 레코드가 전송되면 HADR_SYNC_COMMIT 대기에 추가하여 로그 전송 큐가 커집니다.
수신 된 로그 바이트 비율이 높지만 2 차 복제본에서 플러시 된 로그 바이트 비율이 낮은 경우 이는 2 차 데이터베이스 로그로 플러시 될 수있는 것보다 데이터가 빨리 도착하여 병목 현상을 일으키고 HADR_SYNC_COMMIT에 추가됨을 나타냅니다. 기다림.
가용성 그룹 개요 의 로그 증가 메트릭 은 보조 복제본의 데이터베이스와 함께 표시되는 경우에도 기본 복제본 에서만 플러시 된 로그 바이트 비율을 나타냅니다 .
보조 복제본 의 데이터베이스에 대해 플러시 된 로그 바이트 비율을 보려면 분석 그래프로 이동하여 플러시 된 Log Log bytes / sec 메트릭 을 선택한 다음 데이터베이스를 선택하십시오.
주식 중개인은 한 번 숫자에 의해 잘못 인도 되었기 때문에 잘못된 결정을 내렸다고 말했습니다. 실제로 호기심 많은 단어 선택; 마치 그가 스프레드 시트에서 악의적 인 숫자로 속인 무고한 방관자 인 것처럼 말입니다. 모든 종류의 분석에서, 숫자로 표현 된 데이터의 정확한 해석에 대한 책임은 분석가에게 있습니다.
이는 경제 분석, 의료 연구 데이터 또는 금융 시장 연구에서와 마찬가지로 SQL Server 성능 분석에서도 중요합니다. 이 글에서는 CPU 대기 통계를 올바르게 해석하여 실제로 문제를 나타내는 지 확인하고 그렇다면 어떤 조치를 취할 수 있는지 확인합니다.
SQL Server 대기 통계 모니터링 에 대한 이전 기사에서는 sys.dm_os_wait_stats 의 출력을 보았습니다 . 우리는 signal_wait_time_ms 가 대기 한 리소스가 사용 가능 해지면 스레드를 기다려야하는 밀리 초 수를 나타냅니다. 스레드를 기다리는 데 상당한 시간이 소요되는 경우 시스템 CPU 코어가 수요를 따라 가지 않고 성능 병목 상태라고 쉽게 상상할 수 있습니다. 반드시 그런 것은 아닙니다.
일부 저자들은 총 신호 대기 시간이 신호 대기에서 차지하는 총 대기 시간의 비율보다 덜 중요하다고 올바르게 제안했습니다. 이것은 그림의 절반에 불과합니다. 모든 대기에서 신호 대기 시간을 집계하면 성능 병목 현상을 나타내지 않는 높은 비율이 표시됩니다.
다음 쿼리는 CPU 관련 대기에 대해 블로그에서 가져 왔습니다.
SELECT CAST ( 100.0 * SUM ( signal_wait_time_ms ) / SUM ( wait_time_ms )
AS 숫자 ( 20 , 2 )) AS signal_cpu_waits
FROM sys . dm_os_wait_stats
이 쿼리를 실행하면 다음과 같은 결과가 표시 될 수 있습니다.
전체 신호 대기 백분율
출처에 따르면, 이것은 약간 높은 비율을 나타냅니다. 개별 신호 대기를 보면 어떻게되는지 봅시다.
처음 세 행에는 신호 대기 시간이 포함되어있을뿐만 아니라 총 대기 시간과 정확히 같은 신호 대기 시간이 포함됩니다. 이것은 내가 "아무것도하지 않는다"라고 부르는 대기에 일반적인 행동입니다. 수행 할 작업이없는 대기에 대한 대기 시간이 종종 많기 때문에 위 쿼리에서 계산 된 비율에 대한 기여도는 불균형 적으로 큽니다. 실제로 누군가 CPU에 문제가 있다고 생각할 수 있습니다. 더 나쁜 것은 실제 CPU 문제가이 부풀려진 비율에 덜 큰 영향을 미쳐 눈에 띄지 않게 될 수 있습니다.
목록의 네 번째 대기 유형은 SOS_SCHEDULER_YIELD입니다.이 점을 곧 고려하겠습니다.
세 가지 SQL Server 대기 유형
신호 대기 시간과 전체 대기 시간 간의 전체 비율은 수행 할 작업이 모두 필터링 된 경우에만 유용합니다. 이를 수행하기위한 예제 쿼리는 이전 설치에서 제공되었으며 여기에서 다운로드 할 수 있습니다 .
SOS_SCHEDULER_YIELD
스레드 실행에 대한 사용자 모드 스케줄링 (UMS)에 대한 세부 사항을 논의 할 시간이나 공간이 현재 없습니다. 매혹적인 주제이기 때문에 너무 나쁩니다. UMS는 실행을 다른 스레드로 전환하는시기와 방법에 따라 응용 프로그램이 운영 체제보다 잘 알고 있다는 개념을 기반으로하므로 운영 체제에 필요한 비싼 커널 컨텍스트 스위치를 줄일 수 있습니다. UMS는 대기 스레드의 우선 순위를 조작하여 운영 체제가 항상 SQL Server가 원하는 스레드에 시간 조각을 제공하도록함으로써이를 수행했습니다. UMS는 SQL Server 7에 도입되었으며 몇 년 동안 SQL Server가이 프로그램을 사용하는 유일한 프로그램이었습니다. 그러나 Microsoft의 Windows 직원은이 아이디어가 좋은 아이디어라고 생각했습니다.
여기서 가장 중요한 사실은 SQL Server의 스레드 스케줄러가 항상 양자라고하는 4 밀리 초의 균일 한 타임 슬라이스를 처리한다는 것입니다. 따라서 가장 짧은 작업을 제외한 모든 스레드는 CPU를 포기하고 시스템이 사용 중이 아닌 경우 거의 즉시 CPU를 다시 확보합니다. 따라서 스레드 수율 및 다른 태스크가 스레드에 할당되는 것은 흔한 일이며 많은 수의 SOS_SCHEDULER_YIELD는 아무 것도 알려주지 않습니다.
장기 실행 쿼리는 종종 4 밀리 초 스레드 실행 한계에 도달하므로 높은 SOS_SCHEDULER_YIELD 대기 횟수 준수에 크게 기여합니다. 모든 것이 적절하게 최적화되는 한 오래 실행되는 쿼리를 갖는 데 아무런 문제가 없습니다. 일부 작업은 다른 작업보다 시간이 더 필요합니다.
위의 쿼리 결과에서 신호 대기 대 총 대기 비율은 매우 높지만 평균 대기 시간, 즉 총 대기 수를 대기 수로 나눈 값은 매우 낮습니다. CPU 가용성은 여기서 문제가 아니므로 비율에만 의존하는 또 다른 잠재적 위험을 보여줍니다.
SOS_SCHEDULER_YIELD 대기는 개별 도구의 단일 측정을 기반으로 많은 성능 조건을 진단 할 수없는 방법을 잘 보여줍니다. Windows 성능 모니터가 지속적으로 높은 CPU 활동 (80-90 %)을 보이고 있다고 상상해보십시오. 문제? 말할 수 없습니다. 해야 할 일이 많을 수 있으며 CPU는 이러한 작업을 질서 있고 효율적으로 수행하는 데 허비하고 있습니다. 그러나 많은 스레드가 준비되었지만 적시에 CPU 슬라이스를 얻지 못하는 상황에서 동일한 CPU 백분율이 표시 될 수 있습니다. 이와 같은 상황에서는 성능 모니터 (또는 원하는 경우 sys.dm_os_performance_counters)의 CPU 사용량이 높고 기본 단서가 될 sys.dm_os_wait_stats의 신호 대기 시간이 많을 수 있습니다.
스레드 풀
건강한 시스템에서는 THREADPOOL 대기를 거의 볼 수 없습니다. 스레드 풀에 실행 가능한 태스크에 할당 할 스레드가없는 경우 THREADPOOL 대기가 발생합니다. 구성된 최대 작업자 스레드 수가 워크로드에 작은 도구 인 경우 발생할 수 있습니다. 그러나 구성 값을 조정하기 전에 이것이 일반적인 조건인지 또는 예외적으로 매우 높은 사용량의 기간 동안 만 발생했는지 검사해야합니다. 스레드 유지 관리 비용이 발생하며 거의 발생하지 않는 조건부로 스레드 최대 값을 조정해서는 안됩니다.
CXPACKET
CXPACKET은 SQL Server가 병렬 실행 계획으로 쿼리에 대해 여러 스레드를 동기화하려고 할 때 발생할 수 있습니다. CXPACKET 대기에 대한 응답은 쿼리 자체에 따라 다릅니다. 쿼리가 추가 인덱스의 이점을 얻을 수 있습니까? 쿼리에 부적절한 데이터 형식과 같은 문제를 일으킬 수있는 결함이 있습니까? 쿼리가 정상으로 보이고 인덱스가 적합 해 보인다면 최대 병렬 처리 수준을 조정하여 CXPACKET 대기 시간을 줄일 수 있습니다.
결론
CPU 사용량과 관련된 대기 통계는 단일 문제의 직접적인 지표를 거의 제공하지 않습니다. 기껏해야 CPU 대기 통계는 문제 가능성에주의를 기울일 수 있지만, 관련된 쿼리 및 서버 작업량에 대한 추가 조사만으로 문제가 실제로 존재하는지 여부와 해당되는 경우 수행 할 조치를 결정할 수 있습니다.
Microsoft SQL Server는 NUMA(Non-Uniform Memory Access)를 인식하며 특수한 구성 없이 NUMA 하드웨어에서 원활하게 작동한다. 클럭 속도와 프로세서 수가 증가할수록 이러한 추가 처리 능력을 사용하는 데 필요한 메모리 대기 시간을 줄이기가 더 어려워 진다. 이러한 문제를 피하기 위해 하드웨어 공급업체에서는 대용량의 L3 캐시를 제공하지만 이는 제한적인 해결책일 뿐이다. NUMA 아키텍처는 이 문제에 대한 포괄적인 해결책을 제공 한다. SQL Server는 응용 프로그램을 변경할 필요 없이 NUMA 기반 컴퓨터를 활용하도록 디자인 되었다. 이제 그 구성을 자세히 알아보고 현재 운영중인 서버에서 비효율적인 구성이 있으면 고쳐보길 바란다. 먼저 당부하고 싶은 것은 서버의 설정을 바꾸는 것은 대단히 위험한 행위이다. 구성 변경 시 충분한 검토와 테스트를 수행 한 후 적용하길 바란다.
NUMA(Non-Uniform Memory Access)
SQL Server는 응용 프로그램을 변경할 필요 없이 NUMA 기반 컴퓨터를 활용하도록 디자인 되었다.
작은 프로세서 집합에 사용되는 시스템 버스를 여러 개 구성하는 것이 일반적인 하드웨어 추세이다. CPU 개수가 증가하고 메모리 용량이 증가하는 추세에 대용량 서비스를 할 때 기존의 UMA 방식으로 메모리를 공유하여 사용하게 되면 메모리 대기 시간이 길어 진다. 이를 해결하기 위해 공유 메모리를 전용 메모리로 할당 함으로써 효율성을 높인다.
NUMA 와SQL Server버전
소프트 NUMA 구성시 SQL Server 2000 SP4 이상 지원되며 SQL Server 2005 이상 사용 할 것을 권장 한다.
NUMA 아키텍처
다른 NUMA 노드와 연결된 메모리보다 로컬 메모리를 액세스 하는 것이 훨씬 빠르다. NUMA 하드웨어에서는 일부 메모리 영역이 실제로 나머지 영역과 다른 버스에 있다. NUMA는 로컬 메모리와 외부 메모리를 사용하므로 다른 영역에 비해 일부 메모리 영역에 액세스 하는 시간이 오래 걸린다.
각 프로세서 그룹에는 자체 메모리가 있으며 자체 I/O 채널이 있는 경우도 있다. 그러나 각 CPU는 일관된 방법으로 다른 그룹과 연결된 메모리에 액세스 한다. 각 그룹을 NUMA노드라 한다.
로컬 메모리 : 현재 스레드를 실행 중인 CPU와 같은 노드에 있는 메모리.
외부 메모리 : 현재 실행중인 노드에 속하지 않는 메모리 (원격 메모리 라고도 함)
NUMA 비율 : 로컬 메모리 액세스 비용에 대한 외부 메모리 액세스 비용의 비율. (비율이 1이면 SMP(대칭 다중 처리). 비율이 높을수록 외부 메모리에 액세스 하는 비용이 증가.)
.
NUMA 와 SMP 차이점
NUMA는 특정 메모리 버스의 CPU 개수를 제한하고 고속 연결로 여러 개의 노드를 연결하여 SMP의 병목 현상을 해결 한다.
NUMA 아키텍처는 SMP(Symmetric Multiprocessor) 아키텍처의 확장성 제한을 극복하기 위해 고안 되었다. SMP를 사용하면 모든 메모리 액세스가 같은 공유 메모리 버스에 게시 된다, CPU 수가 비교적 적을 때는 문제가 없지만 수 많은 CPU가 공유 메모리 버스 액세스를 위해 경쟁 할 때는 이 기능이 제대로 작동 하지 않는다.
NUMA 구성에 영향을 주는 설정
하드웨어 NUMA는 컴퓨터 제조업체에서 제공.
소프트 NUMA(SQL Server 메모리)는 레지스트리를 사용.
CPU 선호도는 affinity mask 옵션 사용.
NUMA 선호도에 대한 포트구성은 TCP/IP 포트 매핑 사용.
하드웨어 NUMA
SQL Server에서 사용 가능한 NUMA 개수 확인 DMV
하드웨어 NUMA가 적용된 컴퓨터 에서는 여러 개의 시스템 버스가 있다. 각 프로세서 그룹에는 자체 메모리가 있으며 자체 I/O 채널이 있는 경우도 있지만 CPU는 일관된 방법으로 다른 그룹과 연결된 메모리에 액세스 한다. NUMA 노드 내의 CPU 수는 하드웨어 공급업체에 따라 다르다. 하드웨어 NUMA가 있는 경우 NUMA 대신 인터리브 메모리를 사용하도록 구성 할 수 있다. 그러면 Windows와 SQL Server에서는 NUMA로 인식 되지 않는다.
SELECT DISTINCT memory_node_id FROM sys.dm_os_memory_clerks
결과 값이 하나의 메모리 노드(노드 0)만 반환되면 하드웨어 NUMA가 없거나 해당 하드웨어가 인터리브로 구성되어 있다는 뜻 이다.
하드웨어 NUMA 구성 무시
SQL Server는 하드웨어 NUMA에 대해 4개 이하의CPU가 있고 CPU가 하나뿐인 노드가 하나 이상 있는 경우 NUMA 구성을 무시 한다.
소프트 NUMA
SQL Server에서는 CPU를 NUMA라는 노드로 그룹화 할 수 있다. 많은 CPU가 있고 하드웨어 NUMA가 없는 컴퓨터에서 I/O 및 지연기록 병목을 해결 할 수 있다. 4개의 물리적 NUMA 노드를 구성하면 I/O스레드와 지연 기록기 스레드가 각각 4개가 되므로 성능이 향상 된다. 하드웨어 NUMA와 결합하여 NUMA 그룹을 세분화 할 수 있다. SQL Server 스케줄러와 SQL Server 네트워크 인터페이스(SNI)만 소프트 NUMA를 인식 한다.
NODE_ID 64는 관리자 전용 DAC 이다.
소프트 NUMA 구성 무시
EX) 예를 들어 하드웨어에 8개의 CPU(0..7)가 있고 하드웨어 NUMA 노드가 두 개(0-3 및 4-7)이면 CPU(0,1)과 CPU(2,3)을 결합하여 소프트 NUMA를 만들 수 있다. CPU(1, 5)를 사용하여 소프트 NUMA를 만들 수는 없지만 CPU 선호도를 사용하여 SQL Server 인스턴스의 선호도를 여러 NUMA 노드의 CPU로 설정할 수 있다. SQL Server에 CPU 0-3이 사용되는 경우 I/O 스레드와 지연 기록기 스레드가 각각 하나씩 있다. SQL Server에 CPU 1, 2, 5, 6이 사용되는 경우 두 개의 NUMA 노드에 액세스하게 되며 I/O 스레드와 지연 기록기 스레드가 각각 두 개씩 있다.
여러 하드웨어 NUMA 노드의 CPU를 포함하는 소프트 NUMA를 만들 수 없다. 하지만 CPU 선호도(TCP 매핑)를 사용하여 여러 하드웨어 NUMA 노드에 액세스가 가능하다.
하드웨어 NUMA 와 소프트 NUMA의 메모리 공유 차이점
예를 들면 SMP 컴퓨터에 8개의 CPU가 있으며 각각 두 개의 CPU를 가진 소프트 NUMA 노드를 4개 만들면 메모리 노드 하나에서 4개의 NUMA를 모두 처리 한다.
하드웨어 NUMA는 CPU와 메모리가 하나의 세트로 할당되어 동작 하지만 소프트 NUMA의 경우에는 CPU 할당은 가능 하지만 메모리는 공유하여 사용한다.
NUMA 시나리오
NUMA 선도호에 대한 포트 없음.
하드웨어 NUMA 및 SQL Server의 단일 인스턴스가 있는 컴퓨터에서의 기본 상태. 모든 트랙픽은 단일 포트를 통해 들어오며 사용 가능한 모든 NUMA 노드에 라운드 로빈 방식으로 배포 된다. NUMA는 액세스 효율을 높이며 I/O 및 지연 기록기 스레드를 증가 시킨다. 설정된 연결은 해당 노드에 적용 되므로 NUMA 노드에서 자동으로 균형이 조정된다.
우선 순위 응용 프로그램의 성능 향상을 위해 여러 개의 노드에 단일 포트 연결.
포트 하나의 선호도를 주 우선 순위 응용 프로그램에 사용할 여러 개의 하드웨어 NUMA 노드로 설정한다. 두 번째 포트의 선호도를 두 번째 부 응용 프로그램에 사용할 다른 하드웨어 NUMA 노드로 설정 한다. 두 응용 프로그램의 메모리 및 CPU 리소스는 불균형하게 고정되어 부 응용프로그램보다 3배 많은 로컬 메모리 및 CPU 리소스를 주 응용 프로그램에 제공한다. 이 기능은 우선 적용되는 연결에 추가 리소스를 할당하여 일종의 우선 순위 스레드 실행을 제공 할 수 있다.
여러 개의 노드에 여러 개의 포트 연결.
둘 이상의 포트를 동일한 NUMA 노드로 매핑 할 수 있다. 이렇게 하면 각 포트에서 서로 다른 권한을 구성 할 수 있다. 예를 들어 해당 TCP의 끝점에서 사용 권한을 제어하여 포트를 통해 제공되는 액세스를 제한 할 수 있다. 하지만 두 포트는 똑같이 NUMA를 완벽하게 활용 할 수 있다.
SQL Server의 NUMA 설정
각 NUMNA 노드(하드웨어 NUMA 또는 소프트 NUMA)에는 네트워크 I/O 처리에 사용되는 I/O 완료 포트가 연결되어 있어 여러 포트에 네트워크 I/O 처리를 분산하는 데 도움이 된다.
SQL Server는 Windows에 표시되는 하드웨어 NUMA 경계를 기반으로 CPU 그룹화에 매핑할 스케줄러를 그룹화 한다. 특정 하드웨어 NUMA 노드에서 실행되는 스레드가 메모리를 할당하는 경우 SQL Server의 메모리 관리자는 참조 효율을 위해 해당 NUMA 노드와 연결된 메모리에서 메모리 할당을 시도 한다. 마찬가지로 버퍼 풀 페이지도 하드웨어 NUMA 노드에 분산 된다. 스레드가 로컬에 할당된 버퍼 페이지의 메모리에 액세스하는 것이 외부 메모리를 액세스 하는 것보다 효율 적이다.
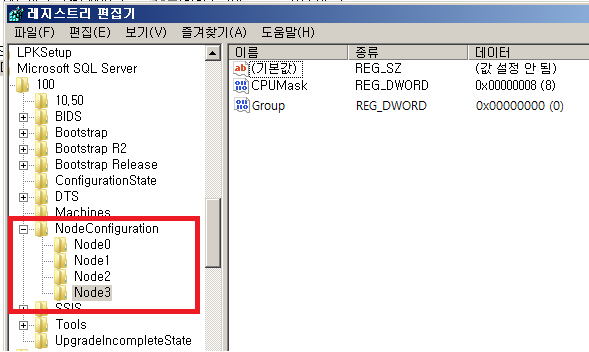
소프트 NUMA 레지스트리 설정
(SQL Server 2008 R2 화면 이다. SQL 2008의 경우에는 GROUP 값을 삭제 한다.)
데이터베이스가 시작 될 때 데이터베이스 엔진에서 오류 로그에 노드 정보를 기록한다. 사용할 노드의 번호를 확인하려면 오류 DMV 뷰의 노드 정보를 확인한다..
NUMA(Non-Uniform Memory Access) 노드 선호도에 대한 TCP/IP 포트는 SQL Server 구성 관리자에서 서버 설정으로 구성된다. 한 개 또는 여러 개의 노드에 TCP/IP 주소와 포트를 설정하려면 포트 번호 뒤에서 괄호 안에 노드 확인 비트맵(선호도 마스크)을 추가한다. 십진수나 16진수 형식으로 노드를 지정할 수 있다.
sp_readerrorlog
select * from sys.dm_os_schedulers
어플리케이션 사용
SQL Server NUMA 구성이 완료 되었으면 매핑된 포트로 접속하여 사용 한다.
0 노드 구성 사용.
0노드, 2노드 구성 사용.
활용
하나의 SQL Server에서 다수의 인스턴스 또는 쿼리가 수행되는 경우에 원활한 서비스를 위하여 물리적인 리소스(CPU) 분산이 필요 할 때 사용 할 수 있다.
배채(Batch)작업 활용
CPU 부하는 작지만 자주 요청되는 쿼리(OLTP)와 자주 요청되지는 않지만 CPU 부하가 큰 쿼리(집계쿼리)가 있을 때 각각의 쿼리 타입마다 CPU 리소스를 할당하여 다른 타입의 쿼리가 같은 CPU 사용을 방지하여 성능을 보장한다.
게임 서비스에서 활용
이때 인기가 높은 게임 하나로 인하여 다른 게임서비스에 영향을 받을 때 각 인스턴스에 NUMA 노드를 할당 함으로써 나머지 다른 서비스의 영향을 최소화 할 수 있다.
게임 퍼블리셔를 예로 들어 보자. 하이엔드급의 SQL Server 한 대에 여러 개의 인스턴스를 설치하여 게임 서비스를 한다고 가정 하자. 모든 자원을 동일하게 사용하는가? 인기가 높은 게임은 많은 자원을 사용 할 것이고 상대적으로 인기가 낮은 게임은 자원의 사용량이 작을 것이다.