특정 시점에 테이블의 데이터 값을 반환하는 테이블은 첫 번째 관계형 데이터베이스 이후로 우리와 함께 해왔지만 항상 특별한 쿼리와 제약 조건이 필요했고 제대로하기가 까다로울 수 있습니다.SQL Server 2016의 새로운 기능인 시스템 버전 임시 테이블은 이러한 테이블이 다른 테이블처럼 작동하도록합니다.테이블을 생성하거나 기존 테이블을 수정하는 방법은 무엇입니까?메모리 내 최적화 된 OLTP 테이블을 임시로 만들려면 어떻게해야합니까?Alex Grinberg가 방법을 보여줍니다.
임시 또는 시스템 버전 테이블은 SQL Server 2016의 데이터베이스 기능으로 도입되었습니다.이를 통해 현재 데이터가 아닌 지정된 시간에 저장된 데이터에 대한 정보를 제공 할 수있는 테이블 유형이 제공됩니다.ANSI SQL 2011은 먼저 임시 테이블을 데이터베이스 기능으로 지정했으며 이제 SQL Server에서 지원됩니다.
임시 테이블의 가장 일반적인 비즈니스 용도는 다음과 같습니다.
천천히 변화하는 치수.시간 테이블은 데이터웨어 하우징 데이터베이스에서 잘 알려진 문제인 시간 분할 데이터와 같이 지정된 기간 동안 최신 데이터를 쿼리하는 더 간단한 방법을 제공합니다.
데이터 감사.임시 테이블은 "상위"테이블에서 데이터가 수정 된시기를 결정하는 감사 추적을 제공합니다.이를 통해규정 준수요구 사항을 충족하고시간에 따른 데이터 변경 사항을 추적 및 감사하여 필요할 때 데이터 포렌식을 수행하는 데 도움이됩니다.
레코드 수준 손상 복구 또는 복구.레코드가 실수로 삭제되거나 업데이트 된 경우 다운 타임없이 테이블 행의 데이터 변경을 '실행 취소'하는 방법을 설정합니다.따라서 이전 버전의 데이터를 히스토리 테이블에서 검색하여 '상위'테이블에 다시 삽입 할 수 있습니다.– 이는 누군가 (또는 일부 애플리케이션 오류로 인해) 실수로 데이터를 삭제하고 사용자가 데이터를 되돌 리거나 복구하려고 할 때 도움이됩니다.
문서 발행일에 대한 정확한 데이터로재무 보고서, 송장 및 명세서를복제합니다.임시 테이블을 사용하면 특정 시점의 데이터를 쿼리하여 당시의 데이터 상태를 조사 할 수 있습니다.
진행중인 비즈니스 활동에서 데이터가 시간에 따라 어떻게 변하는 지 이해하여추세를분석하고시간에 따라 데이터가 변하는 방식의 추세를 계산합니다.
SQL Server 2016이 도입되기 전 어두운 날에는 데이터 로깅 메커니즘이 트리거에서 명시 적으로 설정되어야했습니다.간단한 예제를 제공하려면Department 테이블 자체부터 시작하여 다음 구조로Department테이블에 대한 기록 유지 관리를 자동화해야합니다.
SQL Server 2016의 임시 테이블 기능은 로깅 메커니즘을 크게 단순화 할 수 있습니다.이 문서에서는 시스템 버전 테이블을 작성하는 방법에 대한 단계별 지침을 제공합니다.
테이블을 임시 테이블로 마이그레이션하기 위해 기존 테이블에 임시 테이블 옵션을 설정할 수 있습니다.새 임시 테이블을 생성하려면 임시 테이블 옵션을 ON으로 설정하기 만하면됩니다 (예 : SYSTEM_VERSIONING = ON).임시 테이블 옵션이 활성화되면 SQL Server 2016은 "기록"테이블을 자동으로 생성하고 내부적으로 상위 및 기록 테이블을 모두 유지합니다. 하나는 실제 데이터를 저장하고 다른 하나는 기록 데이터를 저장합니다.시간 테이블의 SYSTEM_TIME 기간 열 (예 : SysStartTime 및 SysEndTime)을 사용하면 메커니즘이 다른 시간 조각에 대한 데이터를보다 효율적으로 쿼리 할 수 있습니다.업데이트되거나 삭제 된 데이터는 "기록"테이블로 이동하는 반면 "상위"테이블은 업데이트 된 레코드에 대한 최신 행 버전을 유지합니다.
캐치는 무엇입니까?
임시 테이블의 가장 중요한 고려 사항, 제한 사항 및 제한 사항은 다음과 같습니다.
임시 테이블과 히스토리 테이블 사이에 레코드를 연결하려면 임시 테이블에 기본 키가 있어야합니다.그러나 히스토리 테이블은 기본 키를 가질 수 없습니다.
DATETIME2의데이터 형식은 (예를 들어 SYSTEM_TIME 기간 열의 설정해야SysStartTime및SysEndTime).
히스토리 테이블을 생성 할 때 항상 히스토리 테이블에서 임시 테이블의 스키마와 테이블 이름을 모두 지정해야합니다.
PAGE 압축은 히스토리 테이블의 기본 설정입니다.
임시 테이블은 스토리지 비용에 영향을 미치고 성능 문제가있을 수있는 blob 데이터 유형 (nvarchar (max), varchar (max), varbinary (max), ntext, text 및 image)을 지원합니다.
시간 테이블과 히스토리 테이블은 모두 동일한 데이터베이스에 생성되어야합니다.링크 된 서버를 사용하여 임시 테이블을 제공 할 수 없습니다.
히스토리 테이블에는 제약 조건, 기본 키, 외래 키 또는 열 제약 조건을 사용할 수 없습니다.
FOR SYSTEM_TIME 절을 사용하는 쿼리가있는 인덱싱 된 뷰에서 임시 테이블을 참조 할 수 없습니다.
SYSTEM_TIME 기간 열은 INSERT 및 UPDATE 문에서 직접 참조 할 수 없습니다.
SYSTEM_VERSIONING이 ON 인 동안에는 TRUNCATE TABLE을 사용할 수 없습니다.
Listing 1의 하나의 DDL 스크립트에서 임시 및 히스토리 테이블을 생성하는 방법을 설명했습니다. 앞서 언급했듯이,두 열 모두에 대해 데이터 유형이 datetime2 인SysStartTime및SysEndTime열은 임시 테이블에 필요합니다.SysStartTime컬럼은GENERATED ALWAYS AS ROW START NOT NULL스펙이어야하며SysEndTime은GENERATED ALWAYS AS ROW END NOT NULL이어야합니다.해당 열에 대한 기본값을 제공 할 의무는 없지만 권장합니다.SysStartTime및SysEndTime열은모두PERIOD FOR SYSTEM_TIME 열에 지정되어야합니다 (MSDN이 PERIOD를 정의한대로 다른 발행물 PERIOD calls 절).
참고 : 시스템 버전 열의 이름을SysStartTime및SysEndTime으로지정할필요는없지만 시간 캡처 기능을 반영하도록 열 이름을 선택해야합니다.GENERATED ALWAYS AS ROW START / END 및 PERIOD FOR SYSTEM_TIME (nameFrom, nameTo) 옵션은 임시 테이블 기능을 활성화합니다.
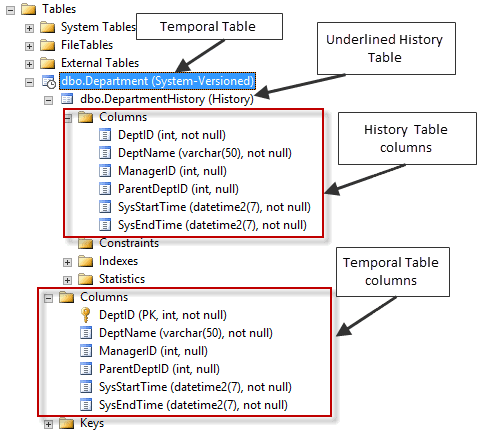
임시 테이블이 생성되면 밑줄이 그어진 히스토리 테이블이 자동으로 생성되고 (그림 1), 히스토리에 대해SysStartTime및SysEndTime(또는 시스템 버전 관리를 정의하기 위해 선택한 이름) 열이있는 CLUSTERED INDEX가 생성됩니다. 표, 목록 2.
CREATECLUSTEREDINDEXix_DepartmentHistory
ONdbo.DepartmentHistory
(SysStartTimeASC,
SysEndTimeASC
)ON[PRIMARY];
목록 2 : 클러스터형 인덱스 생성
임시 테이블에 새 열을 추가해야하는 경우 ALTER TABLE… ADD 열 DDL을 허용해야하며 새 열은 히스토리 테이블에서 자동으로 미러링됩니다.
그림 1 : 개체 탐색기에서 새로 생성 된 시간 및 기록 테이블 표시.
그러나 임시 테이블에는 DROP TABLE DDL을 사용할 수 없습니다.먼저 SYSTEM_VERSIONING을 꺼야합니다.
ALTERTABLEDepartmentSET(SYSTEM_VERSIONING=OFF);
목록 3 : 부서 테이블에서 SYSTEM_VERSIONING 비활성화.
SYSTEM_VERSIONING이 OFF로 설정되면 임시 테이블과 히스토리 테이블이 모두 일반 테이블이됩니다.그런 다음 DROP TABLE 명령을 해당 테이블에 사용할 수 있습니다.
기존 테이블을 시스템 버전 테이블로 설정
SQL Server를 사용하면 기존 테이블을 임시 테이블로 변환 할 수 있습니다.이 작업을 수행하려면 테이블에 기본 키가 있는지 확인하고 아직 존재하지 않는 경우 새로 만들어야합니다.그런 다음 테이블은 두 개의datetime2데이터 유형 열로변경되어야하며GENERATED ALWAYS AS ROW START / END 옵션도… PERIOD FOR SYSTEM_TIME (nameFrom, nameTo)과 함께 적용되어야합니다. 두 옵션 모두 ALTER 명령으로 완료해야합니다.두 번째 ALTER 명령은 SYSTEM_VERSIONING 속성을 활성화하고 선택적으로 (명시 적으로 제공하는 것이 좋습니다) HISTORY_TABLE 속성의 이름을 제공합니다 (Listing 4).
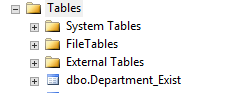
예를 들어 기존 테이블Department_Exist를 임시 테이블로설정해 보겠습니다.목록 4를 실행 한 다음 목록 5를 실행하십시오. 그림 2와 같이 테이블 아이콘을 새로 고쳐 결과를 확인하십시오.
인 메모리 최적화 테이블을 시스템 버전 테이블로 변환 할 때 몇 가지 특정 세부 정보를 알고 있어야합니다.
인 메모리 최적화 테이블은 내구성이 있어야합니다 (DURABILITY = SCHEMA_AND_DATA).
In-Memory 최적화 된 히스토리 테이블은 디스크 기반으로 생성됩니다.
부모 테이블에만 영향을 미치는 쿼리는 기본적으로 컴파일 된 T-SQL 모듈에서 사용할 수 있습니다.고유하게 컴파일 된 모듈에서 FOR SYSTEM TIME 절을 사용하여 임시 쿼리를 사용할 수 없지만 임시 쿼리 및 비원시 모듈에서 메모리 내 최적화 된 테이블과 함께 FOR SYSTEM TIME 절을 사용할 수 있습니다.
SYSTEM_VERSIONING = ON 일때 메모리 내 최적화 된 상위 테이블에 대한 변경 사항에 대한 가장 최근 변경 사항 (INSERT, DELETE)을 수락하기위해 내부 메모리 최적화준비 테이블이 자동으로 생성됩니다.
내부 메모리 내 최적화 된 준비 테이블의 데이터는 비동기 데이터 플러시 작업에 의해 정기적으로 디스크 기반 기록 테이블로 이동됩니다.이 데이터 플러시 메커니즘은 내부 메모리 버퍼를 상위 개체의 메모리 사용량의 10 % 미만으로 유지하는 것을 목표로합니다.DMVsys.dm_db_xtp_memory_consumers는 총 메모리 사용량을 추적하는 데 도움이됩니다.
데이터 플러시는 sys.sp_xtp_flush_temporal_history @schema_name, @object_name 저장 프로 시저를 호출하여 적용 할 수 있습니다.
SYSTEM_VERSIONING = OFF이거나 열을 추가, 삭제 또는 변경하여 시스템 버전 테이블의 스키마를 수정하면 내부 스테이징 버퍼의 전체 내용이 디스크 기반 기록 테이블로 이동됩니다.
기록 데이터 쿼리는 효과적으로 SNAPSHOT 격리 수준에서 수행되며 항상 중복없이 메모리 내 스테이징 버퍼와 디스크 기반 테이블 간의 결합을 반환합니다.
테이블 스키마를 내부적으로 변경하는 ALTER TABLE 작업은 데이터 플러시를 수행해야하므로 작업 속도가 느려질 수 있습니다.
시스템 버전 테이블 옵션이 활성화 된 상태에서 새 메모리 내 최적화 된 OLTP 생성
임시 테이블 옵션을 사용하여 새로운 인 메모리 최적화 테이블을 생성하기위한 DDL은 구문이 기존 디스크 기반 테이블과 매우 유사합니다.메모리 내 최적화 된 테이블 구문에는 처음에 MEMORY_OPTIMIZED 및 DURABILITY 속성을 설정하는 WITH 블록이 있습니다.따라서 SYSTEM_VERSIONING 속성은 목록 7과 같이 쉼표로 구분하여 추가해야합니다.
기존 데이터에 대한 데이터 일관성 검사를 시행하려면 DATA_CONSISTENCY_CHECK = ON으로 SYSTEM_VERSIONING을 설정해야합니다.그러나 DATA_CONSISTENCY_CHECK 속성은현재.임시 테이블에 대해 DATA_CONSISTENCY_CHECK를 활성화하기로 결정한 경우 인스턴스에 SQL Server 2016 용 누적 업데이트 1이 있는지 확인합니다.
다음은 기존 테이블에서 DATA_CONSISTENCY_CHECK 속성을 활성화하는 예입니다.
임시 테이블은 행 버전 프로세스를 자동화하는 데 매우 유용한 SQL Server 2016 기능입니다.데이터 보관 작업을 단순화하고 데이터웨어 하우스 데이터베이스에 대해 천천히 변화하는 차원을 활용하기위한 실질적인 해결책이 될 수도 있습니다.새 테이블과 기존 테이블을 설정하는 것이 매우 쉽기 때문에 임시 테이블 기능은 SQL Server 데이터베이스와 함께 구현하기에 좋은 선택입니다.
QL Server 2016에서 Temporal Table이라는 기능이 있어서, 소개하고자 합니다.
Temporal은 다음과 같은 뜻을 가집니다.
- 1. 현세적인, 속세의 2. 시간의; 시간의 제약을 받는 3. 관자놀이께의
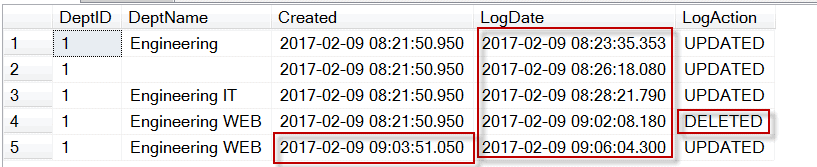
Temporal 테이블은 제가 볼때 엄청난 기능은 아니고, Table의 내용이 변경(UPDATE, DELETE)이 될 경우 그 내용을 기록하는 History (?)성 테이블이라고 생각하면 됩니다.
글로 표현하는 것보다 그림으로 보는 것이 더욱 이해가 될 것 입니다.
제가 생각 할때 이 그림이 가장 맞는거 같습니다. 크게 별다른 기능이 아니고, 단순히 유저가 DELETE , UPDATE 라는 조작을 가하면 테이블에 기록을 남기는 것 입니다.
음... 일종에 트리거 같은 기능을 종속하여, 추가한 것으로 보여집니다.
바로 이 기능을 테스트 해보겠습니다.
Step 1 - 테이블 생성 및 데이터 입력
우선 테이블을 생성하고, 데이터를 입력하는데 2개를 생성해 줍니다. 우리가 보기 위한 것은 기록을 검색하고, UPDATE , DELETE 시에 잘 남는지를 보는 것이므로,
생성과 동시에 데이터를 몇개 삽입 하도록 하겠습니다.
-- create history table CREATE TABLE dbo.PriceHistory (ID INT NOT NULL ,Product VARCHAR(50) NOT NULL ,Price NUMERIC(10,2) NOT NULL ,StartDate DATETIME2 NOT NULL ,EndDate DATETIME2 NOT NULL ) GO -- insert values for history INSERT INTO dbo.PriceHistory(ID,Product,Price,StartDate,EndDate) VALUES (1,'myProduct',1.15,'2015-07-01 00:00:00','2015-07-01 11:58:00') ,(1,'myProduct',1.16,'2015-07-01 11:58:00','2015-07-03 12:00:00') ,(1,'myProduct',1.18,'2015-07-03 12:00:00','2015-07-05 18:05:00') ,(1,'myProduct',1.21,'2015-07-05 18:05:00','2015-07-07 08:33:00') -- create current table to store prices CREATE TABLE dbo.Price (ID INT NOT NULL ,Product VARCHAR(50) NOT NULL ,Price NUMERIC(10,2) NOT NULL ,StartDate DATETIME2 NOT NULL ,EndDate DATETIME2 NOT NULL ,CONSTRAINT PK_Price PRIMARY KEY CLUSTERED (ID ASC) ) GO -- insert the current price (make sure start date is not in the future!) INSERT INTO dbo.Price(ID,Product,Price,StartDate,EndDate) VALUES (1,'myProduct',1.20,'2015-07-07 08:33:00','9999-12-31 23:59:59.9999999') GO
데이터가 잘 들어갔는지 확인해 보겠습니다.
첫번째가 Price 테이블 입니다. 그리고 아래가 PriceHistory 입니다.
Step 2 - Temporal Table 만들기
이제 PriceHistory를 Price에 종속 시켜야합니다. 저는 종속이라는 표현을 쓰지만, Temporal 테이블을 생성한다고 하는게 맞겠네요.
아래를 보시면 StartDate 그리고 EndDate를 이용하여, Temporal 테이블의 기준 시간으로 삼습니다.
-- enable system period columns ALTER TABLE dbo.Price ADD PERIOD FOR SYSTEM_TIME (StartDate,EndDate) GO -- turn on system versioning ALTER TABLE dbo.Price SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE=dbo.PriceHistory,DATA_CONSISTENCY_CHECK=ON) ) GO
만약 Temporal 테이블이 정상적으로 만들어졌다면, 아래와 같은 모습을 확인 할 수 있습니다. Price 테이블을 클릭하면, 아래에 PriceHistory 테이블이
나타나는 것을 확인 할 수 있습니다.
위의 2개의 테이블은 따로따로도 조회가 가능하며, Price 테이블의 과거 데이터를 조회 할 수도 있습니다.
SELECT * FROM dbo.Price FOR SYSTEM_TIME AS OF '2015-07-04' GO SELECT * FROM dbo.Price FOR SYSTEM_TIME AS OF '2015-07-03 12:00:00' GO SELECT * FROM dbo.Price FOR SYSTEM_TIME FROM '2015-07-06' TO '2015-07-06' GO
검색은 여러가지 가능하며, 부분적으로도 가능하며, BETWEEN 검색도 가능 합니다.
이렇게 검색을 할 경우 현재 Price 테이블의 데이터를 조회하는 것이 아닌 PriceHistory 테이블을 조회합니다.
위의 실행계획을 보면, PriceHistory를 조회하고 있는 것이 보이실 겁니다. 이전 같은 경우 Log 테이블을 따로 만들고, Join해서 조회할 것을 줄였다? 뭐 이렇게
생각하면 좋을 듯 합니다.
Step 3 - 데이터 조작
이제 데이터를 조작해 보겠습니다. 각각 데이터를 조작 할 경우 어떻게 남는지 확인해 보겠습니다.
CDC라고도하는 변경 데이터 캡처는 추가 프로그래밍 작업없이 SQL Server 데이터베이스 테이블에서 수행되는 변경 사항을 추적하고 캡처하는 데 유용한 기능으로 SQL Server 2008 버전에 처음 도입되었습니다.SQL Server 2016 이전에는 SQL ServerEnterprise버전에서만 SQL Server 데이터베이스에서 변경 데이터 캡처를 사용할 수 있었으며SQL Server 2016부터는 필요하지 않았습니다.
변경 데이터 캡처는 데이터베이스 테이블에 대한 INSERT, UPDATE 및 DELETE 작업을 추적하고 원본 테이블의 동일한 열 구조와 이러한 변경 사항에 대한 설명을 기록하는 추가 열을 사용하여 미러링 된 테이블에 이러한 변경 사항에 대한 자세한 정보를 기록합니다.SQL Server는 삽입 된 값을 보여주는 각 INSERT 문에 대해 하나의 레코드, 삭제 된 데이터를 표시하는 각 DELETE 문에 대한 레코드와 각 UPDATE 문에 대해 두 개의 레코드를 기록합니다. 첫 번째는 변경 전 데이터를 표시하고 두 번째는 수행 후 데이터를 표시합니다. 변화.
SQL Server 엔진에서 기록 된 변경 사항에 할당 한 커밋 로그 시퀀스 번호 (LSN)를 표시하는__ $ start_lsn및__ $ end_lsn
동일한 트랜잭션의 다른 변경과 관련된 변경 순서를 표시하는__ $ seqval, 변경 작업 유형을 표시하는__ $ operation (여기서 1 = 삭제, 2 = 삽입, 3 = 업데이트 (변경 전) 및 4) = 업데이트 (변경 후)
__ $ update_mask는 캡처 된 각 열에 대해 정의 된 비트 마스크이며 업데이트 열을 식별합니다.
이 세부 정보를 통해 보안 또는 감사 목적으로 데이터베이스 변경 사항을 모니터링하거나 T-SQL 또는 ETL 방법을 사용하여 이러한 변경 사항을 OLTP 소스에서 대상 OLAP 데이터웨어 하우스로 점진적으로로드 할 수 있습니다.
설치 및 아키텍처
변경 데이터 캡처를 사용하려면 SQL Server 에이전트가 SQL Server 인스턴스에서 실행되고 있어야합니다.SQL Server 데이터베이스 테이블에서 기능이 활성화되면 해당 데이터베이스에 대해 두 개의 SQL Server 에이전트 작업이 생성됩니다.첫 번째 작업은 데이터베이스 변경 테이블을 변경 정보로 채우고 두 번째 작업은 구성 가능한 보존 기간 인 3 일보다 오래된 레코드를 삭제하여 변경 테이블을 정리합니다.
변경 데이터 캡처는 데이터 변경의 소스 인 SQL Server 트랜잭션 로그에 의존합니다.변경이 수행되면이 변경 사항이 트랜잭션 로그 파일에 기록됩니다.
해당 테이블에서 CDC 기능이 활성화 된 경우 CDC 기능에 대한 캡처 프로세스 역할을하는 트랜잭션 로그 복제 로그 판독기 에이전트는 트랜잭션 로그 파일에서 변경 로그를 읽고 이러한 변경 사항에 대한 메타 데이터 정보를 추가하고 아래와 같이 관련 CDC 변경 테이블 :
감사 솔루션으로서의 변경 데이터 캡처
변경 데이터 캡처는 비동기 SQL Server 감사 솔루션으로 사용되어 SELECT 문을 추적하는 옵션없이 INSERT, UPDATE 또는 DELETE 작업과 같은 테이블의 DML 변경을 추적하고 감사 할 수 있습니다.
Change Data Capture를 좋은 SQL Server Audit 솔루션으로 만드는 이유는 몇 가지 T-SQL 명령을 사용하여 쉽게 구성 할 수 있고 수정 프로세스 이전의 값에 대한 기록 정보를 제공하며 데이터 수정 프로세스에 대한 자세한 정보를 제공한다는 것입니다.
변경 데이터 캡처를 사용하여 SQL Server DML 변경 사항을 감사하는 방법을 살펴 보겠습니다.
CDC 활성화
감사를 위해 특정 테이블에서 변경 데이터 캡처를 사용하려면 먼저 SYSADMIN 고정 서버 역할의 구성원이아래에 표시된대로sys.sp_cdc_enable_db시스템 저장 프로 시저를사용하여 데이터베이스 수준에서 CDC를 먼저 사용하도록 설정해야합니다. :
USE[CDCAudit]
GO
EXECsys.sp_cdc_enable_db
GO
해당 데이터베이스에서 CDC가 활성화되었는지 확인하기 위해 다음과 같이 CDC가 활성화 된 데이터베이스 목록에 대해 sys.databases DMV를 쿼리합니다.
데이터베이스 수준에서 CDC를 활성화 한 후에는sys.sp_cdc_enable_table시스템 저장 프로 시저를사용하여 db_owner 고정 데이터베이스 역할의 구성원이 데이터베이스 테이블의 DML 변경 사항을 추적하고 감사할 수 있습니다.아래에 표시된 것처럼@captured_column_list매개 변수로지정된열 목록의 변경 사항과@filegroup_name매개 변수로 지정된 별도의 파일 그룹에 변경 테이블을 만듭니다.
USE[CDCAudit]
GO
EXECsys.sp_cdc_enable_table
@source_schema=N'dbo',
@source_name=N'Employee_Main',
@role_name=NULL,
@filegroup_name=NULL,
@supports_net_changes=0
GO
해당 테이블에서 CDC가 활성화되었는지 확인하기 위해 아래와 같이 CDC가 활성화 된 현재 데이터베이스 아래의 모든 테이블에 대해 sys.tables DMV를 쿼리합니다.
테이블에서 CDC가 활성화되면 CDC 관련 정보를 저장하기 위해 데이터베이스의 CDC 스키마 아래에 여러 시스템 테이블이 생성됩니다.이 테이블에는 다음이 포함됩니다.
캡처된 열 목록이 포함 된CDC.captured_columns테이블
캡처에 사용할 수있는 테이블 목록이 포함 된CDC.change_tables테이블
캡처 데이터가 활성화 된 이후의 모든 DDL 변경 내역을 기록하는CDC.ddl_history테이블
변경 테이블과 연관된 모든 인덱스를 포함하는CDC.index_columns테이블
LSN 번호를 시간과 매핑하는 데 사용되는CDC.lsn_time_mapping테이블과 마지막으로 소스 테이블에서 DML 변경 사항을 캡처하는 데 사용되는 각 CDC 사용 테이블에 대한 하나의 변경 테이블이 아래와 같이 표시됩니다.
… 그리고 CDC 지원 테이블, 캡처 및 정리 작업과 관련된 SQL 에이전트 작업은 아래와 같이 생성됩니다.
… 또는아래와 같이sys.sp_cdc_disable_db시스템 저장 프로 시저를사용하여 CDC 활성화 테이블에서 하나씩 비활성화 할 필요없이 데이터베이스 수준에서 완전히 비활성화합니다.
DML 변경 감사
데이터베이스 테이블에서 CDC를 활성화 한 후 해당 테이블에서 아래의 세 가지 데이터베이스 DML 변경 (INSERT, UPDATE, DELETE)을 수행하고 다음과 같이 CDC 기능을 사용하여 이러한 변경 사항을 감사하는 방법을 확인합니다.
앞서 언급했듯이 데이터 수정 사항은 CDC 사용 테이블과 관련된 변경 테이블에 기록됩니다. 여기서는 [cdc]. [dbo_Employee_Main_CT]테이블입니다.소스 테이블에 최근 삽입 된 모든 레코드를보기 위해 유형 2의 모든 작업에 대한 변경 테이블을 쿼리 할 수 있으며 삽입 된 값을 포함하여 INSERT 작업에 대한 전체 정보가 아래와 같이 표시됩니다.
유형 1의 모든 작업에 대한 변경 테이블을 쿼리하면 원본 테이블에서 최근에 삭제 된 모든 레코드가 반환되고 삭제 된 레코드의 값이 아래와 같이 표시됩니다.
마지막으로 유형 3 및 4의 작업에 대한 변경 테이블을 쿼리하여 UPDATE 문을 추적 할 수 있습니다. 그러면 업데이트 이전의 값이 작업 유형 3에, 변경 후 값이 작업 유형 4에 표시됩니다. 아래 그림과 같이:
변경 테이블 쿼리는 Microsoft에서 권장하지 않습니다.대신아래와 같이 CDC 사용 테이블과 관련된CDC.fn_cdc_get_all_changes시스템 함수를쿼리 할 수있습니다.
CDC.fn_cdc_get_all_changes함수는아래와 같이 모든 DML 변경 정보를 검색하는@from_lsn,@to_lsn,@row_filter_option매개 변수를 제공하여 쿼리 할 수 있습니다.
한계
변경 데이터 캡처를 사용하면 데이터베이스 DML 변경 사항만감사 할 수 있지만SELECT 문을 모니터링하는 옵션은 없지만 구성 작업은 무시할 수 있습니다.반면 CDC를 SQL Server Audit 솔루션으로 고려하려면 상당한 유지 관리 및 관리 노력이 필요합니다.여기에는 추적 데이터가 구성 가능한 일 수 동안 변경 테이블에 보관되고 동일하거나 다른 데이터 파일에 저장되기 때문에 보관 메커니즘 자동화가 포함됩니다.
또한 변경 테이블은 각 데이터베이스 아래에 저장되며 추적 된 각 테이블에 대해 함수가 생성됩니다.이로 인해 번거롭고 동일한 데이터베이스의 모든 테이블, 동일한 인스턴스의 모든 데이터베이스 또는 여러 인스턴스의 DML 변경 정보를 읽는 통합 감사 보고서를 만드는 데 상당한 프로그래밍 노력이 필요합니다.
SQL Server Audit 솔루션으로서 CDC 기능에 대한 또 다른 제한은 CDC 사용 테이블에서 DDL 변경을 처리하는 데 필요한 어려운 프로세스입니다. 소스 테이블에서 변경 데이터 캡처를 사용하면 해당 테이블에서 DDL 변경을 수행하는 것을 방해하지 않기 때문입니다.
또한 SQL Server 에이전트 서비스가 실행되고 있지 않으면 CDC 캡처 작업이 작동하지 않으며 데이터베이스 복구 모델이 단순하더라도 CHECKPOINT가 실행 중이더라도 로그 잘림이 진행되지 않기 때문에 데이터베이스 로그 파일이 빠르게 증가합니다. 캡처를 기다리는 모든 변경 사항이 CDC 캡처 프로세스에 의해 수집 될 때까지 수행됩니다.
이 SQL Server 감사 시리즈는 SQL Server 변경 추적에 관한 내용이며 SQL 업데이트 및 삭제를 포함한 DML 변경 사항을 활성화, 비활성화, 감사하는 개요를 다룹니다.
이것이 SQL Server Audit 시리즈의 첫 번째 읽기 인 경우이 시리즈의 이전 기사 (하단의TOC참조)를 통해 SQL Server Audit의 개념에 대한 확실한 배경을 구축하는것이 좋습니다.SQL Server 인스턴스 및 데이터베이스를 감사하는 이유와 SQL Server 데이터베이스를 감사하는 데 사용할 수있는 다양한 방법.이 기사에서는 SQL Server 변경 추적을 사용하여 SQL Server 감사를 수행하는 방법에 대해 설명합니다.
개요
CT라고도하는 SQL Server 변경 추적은 SQL Server 2008에 처음 도입 된 경량 추적 메커니즘으로, SQL Server 데이터베이스 테이블에서 수행 된 DML 변경을 추적하는 데 사용할 수 있습니다.SQL 변경 내용 추적은 무료 Express 버전을 포함한 모든 SQL Server 버전에서 구성 할 수 있습니다.
SQL Server 변경 추적은 동기 추적 메커니즘으로, 변경 데이터 캡처 비동기 메커니즘과 같은 트랜잭션 로그 파일에서 변경 내용을 읽는 동안 지연없이 DML 변경이 커밋되면 변경 정보를 직접 사용할 수 있습니다. .즉, SQL 변경 내용 추적은 DML 변경 내용을 캡처하거나 쓸 때 SQL 에이전트 작업에 대한 종속성이 없기 때문에 SQL Server 에이전트 서비스를 가동하고 실행할 필요가 없습니다.
SQL Server 변경 내용 추적이 데이터베이스 테이블에서 활성화되면 SQL Server 엔진은Change_Tracking_ <Object_ID>라는 이름으로 내부 테이블을 만들어추적 된 사용자 테이블의 INSERT, UPDATE 및 DELETE 문을 추적합니다.SQL 변경 추적을변경 데이터 캡처기능보다 가볍게 만드는이유는 추적 된 테이블 내의이 행에 대해 수행 된 DML 변경이기본 키를제공함을 언급하여 데이터베이스 테이블 변경을 추적한다는 것입니다.수정 된 행의 열 값, 변경된 열 및 수정 유형, 최소 저장 요구 사항 및 오버 헤드로 삽입 또는 삭제 된 값 또는 업데이트 프로세스 전후의 값을 쓰는 등 변경된 데이터에 대한 자세한 정보를 쓰지 않습니다.이 키 값은 추적 된 테이블에서 수정 된 행을 식별하는 데 사용되므로 해당 테이블에서 SQL 변경 내용 추적을 활성화하기 위해 데이터베이스 테이블에 기본 키가 있어야하는 이유입니다.
감사 솔루션으로서의 SQL Server 변경 추적
SQL Server 변경 추적은 레거시 SQL Server 감사 솔루션으로 간주되며, 변경된 행, 해당 행의 기본 키 및 무엇과 같은 간단한 감사 질문에 대답하여 데이터베이스 테이블 DML 변경을 추적하고 감사하는 데 사용할 수 있습니다. 해당 행에서 수행 된 변경 유형.
SQL 변경 추적이 SQL Server 데이터베이스 감사 솔루션으로서 덜 바람직하게 만드는 이유는 업데이트 프로세스 전후에 삽입 된 데이터, 삭제 된 데이터 또는 데이터에 대한 정보를 기록하지 않는다는 것입니다.또한 기본 키 제약 조건이 정의되지 않은 테이블은 기본 키 제약 조건이있는 데이터베이스 테이블에 대해서만 제한되므로 SQL 변경 추적을 사용하여 감사 할 수 없습니다.
반면에 SQL Server 변경 내용 추적은 데이터베이스 테이블에서 수행 된 변경 사항에 대한 기록을 기록하지 않으며 버전 기록을 유지하지 않고 해당 행에서 수행 된 마지막 변경 사항을 기록합니다.예를 들어 행이 삽입 된 다음 여러 번 업데이트되고 마지막으로 삭제되면 SQL Server Audit 솔루션 인 SQL 변경 추적은 해당 행에서 수행 된 이전 작업을 고려하지 않고 마지막 삭제 문만 기록합니다.
SQL Server Chang Tracking을 사용하여 유용한 SQL Server Audit 솔루션을 구축하려면 다음에 저장된 변경된 행의 기본 키 값을 기반으로 SQL 변경 내용 추적의 내부 테이블을 추적 된 원본 테이블과 조인하는 데 추가적인 코딩 작업이 필요합니다. 변경된 데이터에 대한 완전한 정보를 얻기위한 내부 테이블.내부 테이블이 표시되지 않고 직접 쿼리 할 수 없기 때문에 나중에 설명 할 이러한 내부 테이블을 기반으로 구축 된 온 디스크 테이블을 사용하는 SQL 변경 추적 기능의 이점을 얻을 수 있습니다. 이 기사.
여기서 고려해야 할 또 다른 사항은 SQL 변경 내용 추적 내부 테이블이 시간이 지남에 따라 점진적으로 증가한다는 것입니다.제거 프로세스는 자동 정리 스레드에 의해 제어되지만 사전 정의 된 보존 기간 (기본값 2 일)을 기반으로 내부 디스크 테이블에서 오래된 데이터를 제거하는 역할을하지만 적절한 보존 기간을 다음으로 설정해야합니다. SQL Server Audit 솔루션에 사용할 수있는 변경 데이터를 유지합니다.또한SQL Server 2016에 추가 된새로운 저장 프로 시저를 활용하여 내부 SQL Server 변경 추적 테이블에 대한 수동 정리를 수행 할 수 있습니다.
SQL 변경 추적을 사용하여 SQL Server DML 변경 사항을 감사하는 방법을 살펴 보겠습니다.
SQL 변경 추적 활성화
감사 목적으로 데이터베이스 테이블에서 SQL Server 변경 추적을 사용하려면 내부 디스크 테이블에 대한 보존 기간을 제공하여 ALTER DATABASE T-SQL 문을 사용하여 데이터베이스 수준에서 사용하도록 설정해야합니다. 자동 정리 프로세스를 활성화하면 아래와 같이 보존 기간보다 오래된 내부 디스크 테이블의 데이터가 자동으로 삭제됩니다.
USEmaster
GO
ALTERDATABASE[CTAudit]
SETCHANGE_TRACKING=ON
(CHANGE_RETENTION=2DAYS,AUTO_CLEANUP=ON)
또한아래와 같이 내부 디스크 테이블의 보존 기간을 지정하고 자동 정리 프로세스를 활성화 할 수있는 데이터베이스 속성 창의변경 내용 추적탭에서 SQL Server Management Studio 도구를 사용하여 활성화 할 수도있습니다.
데이터베이스 수준에서 SQL Server 변경 추적을 활성화 한 후에는 DML 변경 사항을 추적하고 감사 할 각 테이블에서이를 활성화해야합니다.이는 아래의 ALTER TABLE T-SQL 문을 사용하여 수행 할 수 있습니다.
USECTAudit
GO
ALTERTABLEEmployee_Main
ENABLECHANGE_TRACKING
WITH(TRACK_COLUMNS_UPDATED=ON)
기본 키가 정의되지 않은 데이터베이스 테이블에서 SQL 변경 내용 추적을 활성화하려고하면 ALTER TABLE 문이 실패하여 아래 오류 메시지와 같이 SQL 변경 내용 추적을 활성화하기 전에 테이블에 기본 키를 만들어야 함을 보여줍니다. :
테이블에 Primary Key 제약 조건을 추가하면 ALTER TABLE 문이 성공적으로 실행됩니다.또한 아래와 같이 테이블 속성 창의 SQL 변경 내용 추적 탭에서 SQL Server Management Studio를 사용하여 SQL 변경 내용 추적을 활성화 할 수도 있습니다.
SQL 변경 내용 추적 비활성화
데이터베이스 테이블에서 SQL Server 변경 추적을 활성화해도 해당 테이블에서 CT가 비활성화되지 않는 한 실패 할 기본 키의 변경을 제외하고는 해당 테이블에서 DDL 변경을 수행 할 수 없습니다.
아래의 ALTER TABLE T-SQL 문을 사용하여 테이블 수준에서 변경 내용 추적을 비활성화 할 수 있습니다.
테이블 수준에서 비활성화 한 후에는 아래의 ALTER DATABASE T-SQL 문을 사용하여 데이터베이스 수준에서 변경 추적을 쉽게 비활성화 할 수 있습니다.
DML 변경 감사
INSERT 감사
SQL Server 데이터베이스 감사 목적으로 데이터베이스 테이블에서 SQL Server 변경 내용 추적을 사용하면 테이블 행에서 수행되는 모든 DML 변경 내용이 CT 내부 테이블에 기록됩니다.Employe_Main 테스트 테이블에 아래 INSERT 문을 수행한다고 가정합니다.
INSERT 문 이후 내부 테이블에 기록 된 변경 내용 추적 데이터를 가져 오려면CHANGETABLE시스템 함수와 같은변경 내용 추적 기능을사용할 수 있습니다.CHANGETABLE 함수는 지정된 버전 번호 이후에 추적 된 테이블에서 수행 된 모든 변경 사항을 반환합니다.버전 번호 카운터는 변경된 각 행과 연결되며 추적 된 테이블에 변경 사항이있을 때마다 증가합니다.아래 T-SQL 스크립트를 사용하여 변경 정보를 검색 할 수 있습니다.
INSERT 문을 수행 한 후 CT 내부 테이블에서 반환 된 데이터에는 수행 된 DML 변경의 버전, DML 작업 유형 (이 경우 INSERT의 경우 I)이 표시됩니다. INSERT의 경우와 마지막으로 SQL Server 감사 테이블에 삽입 된 행의 기본 키 값은 아래와 같습니다.
삽입 된 전체 레코드를 얻으려면 아래 T-SQL 스크립트 에서처럼 기본 키 값을 기반으로 추적 된 소스 테이블과 CHANGETABLE 함수를 쉽게 조인 할 수 있습니다.
SELECTCT.SYS_CHANGE_VERSION,
CT.SYS_CHANGE_OPERATION,EM.*
FROMCHANGETABLE
(CHANGES[Employee_Main],0)asCT
JOIN[dbo].[Employee_Main]EM
ONCT.Emp_ID=EM.Emp_ID
ORDERBYSYS_CHANGE_VERSION
CT 함수와 추적 된 소스 테이블을 결합하여 반환 된 결과는 삽입 된 데이터에 대한 완전한 정보를 표시하며, 이는 아래와 같이 데이터베이스 테이블을 감사하는 데 유용 할 수 있습니다.
업데이트 감사
동일한 추적 테이블에서 아래 UPDATE 문이 수행되는 경우 :
그런 다음 추적 된 소스 테이블과 CHANGETABLE 함수를 결합하는 이전 쿼리를 실행하면 Emp_ID 값이 2 인 행의 변경 버전 번호가 증가하는 것을 볼 수 있습니다.또한 해당 행에서 수행 된 변경의 마지막 버전 만 기록되고 이전 INSERT 문이 누락되고 마지막 업데이트 문이 유지됩니다.이 문은 내부적으로 이전 레코드를 삭제 한 다음 새 값으로 레코드를 삽입합니다. 아래 그림과 같이:
감사 삭제
아래 DELETE 문을 실행하여 추적 된 테이블에서 세 번째 행을 삭제한다고 가정합니다.
그런 다음 CHANGETABLE 함수를 추적 된 소스 테이블과 결합하는 동일한 쿼리를 실행하여 삭제 된 레코드 정보를 확인합니다.아래에 표시된 것처럼 삭제 된 레코드 데이터가 추적 된 소스 테이블에 없기 때문에 표시되지 않습니다.
이전 쿼리에서 JOIN 유형을 LEFT OUTER JOIN으로 변경하면 CHANGETABLE 함수에서 삭제 된 레코드 정보가 검색되는 것을 볼 수 있습니다.이 정보에는 변경 버전 번호와 변경 유형 (DELETE의 경우 D) 만 포함되며 아래에 표시된 것처럼 삭제 된 레코드에 대한 정보는 없습니다.
이전 결과에서 SQL Server 변경 추적을 제한된 SQL Server 데이터베이스 감사 솔루션으로 사용하여 CT 지원 테이블에서 DML 변경을 추적 할 수 있다는 것이 분명합니다.이는 업데이트 또는 삭제 작업 이전의 값에 대한 기록 정보없이 수정 된 레코드에 대해 수행 된 마지막 변경 만 반환하기 때문입니다.
SQL Server에서 요청된 쿼리는 컴파일 과정을 거쳐 실행 계획을 생성한다.이때 요청된 쿼리에 따라 수 많은 계획이 생성될 수도 있고 기존의 계획이 재사용 될 수도 있다.이번 포스트에서는 저장된 캐시 계획에 대한 활용방안을 살펴 보자.
비슷한 방식으로 실행 계획을 저장하는SQL Server의 내부 메모리 영역(플랜캐시 또는 프로시저 캐시라고도 한다)이 있다. SQL Server는 기존 계획이 내부에 존재하는지 먼저 확인한다.그리고 기존의 계획을 발견하게 되면 요청된 쿼리에 대해 새로운 계획에 대한 컴파일 시간을 할애 하지 않아도 된다.이렇게 기존의 계획을 재사용하면 일반적인 성능을 높일 수 있다.
SQL Server에 저장되어 있는 플랜캐시를 확인하여 자주 사용하는 플랜 및 사용하지 않는 플랜을 분석 할 수가 있다.플랜캐시는 시간이 지남에 따라 실행되는 모든 쿼리에 대한 자세한 내용을 저장한다.우리는 주기적으로 캐시의 내용을 검사 할 수 있다.또한 성능 문제를 조사하기 위해 플랜캐시를 확인 할 수 있다.
[캐시 내부의 단일 실행 계획을 찾는 방법]
한 번만 실행되는 쿼리문에 대해 저장된 쿼리 계획을 갖는 것은 큰 문제가 되지 않는다.하지만 많은 단일 실행 계획이 있을 때 문제가 발생 한다.이는 플랜캐시의 사용량 증가와 함께CPU리소스 사용의증가로 전체적인 성능저하가 발생한다.
다음 스크립트는 플랜캐시에서 한번 사용된 계획을 나타낸다.
SELECT
text,cp.objtype,cp.size_in_bytes
FROMsys.dm_exec_cached_plansAScp
CROSSAPPLYsys.dm_exec_sql_text(cp.plan_handle)st
WHEREcp.cacheobjtype=N'Compiled Plan'
ANDcp.objtypeIN(N'Adhoc',N'Prepared')
ANDcp.usecounts=1
ORDERBYcp.size_in_bytesDESC
OPTION(RECOMPILE);
SQL Server2008은 플랜 캐시 사이즈의 증가를 최소화 하기 위해 임시워크로드(ad-hoc workload)에 대한 구성 옵션 최적화를 도입했다.이 옵션은 첫 번째 실행에 대해서는 전체 계획을 저장하지 않는다.단지 계획 스텁은 플랜캐시 내부의 적은 공간을 차지하도록 생성된다.계획이 두 번 사용하면 다음에는 완전히 컴파일된 계획을 저장한다.임시워크로드 최적화는 기본적으로 활성화 되어 있지 않다.
위의 스크립트는 한 번만 사용되는 명령문을 결정하는데 매우 큰 도움이 된다.그러나 이러한 단일 사용계획이 정말 문제가 있는 경우는 어떻게 알 수 있을까?다음 스크립트를 사용하여 단일 사용 계획에 사용되는 메모리 양을 측정하고 전체 플랜캐시의 크기를 비교할 수 있다.
위 결과를 바탕으로 유사한 쿼리 해시 값을 많이 가진 경우 대신에 사용되는 하나의 매개 변수가 있는 문을 작성하는 것이 좋다.이것은 많은 계획을 하나의 계획으로 저장할 수 있다.
하나의 매개 변수가 있는 쿼리를 작성하는 코드를 변경할 수 없는 경우에는 실행계획 재사용의 극대화를 위해 플랜 가이드를 사용하는 것이 좋다.
SQL Server캐싱된 계획은SQL Server에서 실행되는 쿼리에 대한 전반적인 정보를 가지고 있다.시스템의 속도가 저하될 경우 캐시된 데이터를 확인 할 수 있다. DBA는 자신이 운용하는 서버의 캐시를 주기적으로 확인하여 변경된 사항은 없는지 정상적으로 플랜을 사용하고 있는지 등을 파악하여 시스템 최적화를 이끌어 낼 수 있을 듯 하다.
[참고자료]
lSQL Server Plan Cache: The Junk Drawer for Your Queries
TempDB 데이터베이스는 SQL Server의 시스템 데이터베이스 중 하나이지만 다른 시스템 데이터베이스와 구별되는 다양한 고유 기능을 가지고 있습니다.이 SQL Server TempDB 데이터베이스에 전역 및 로컬 임시 테이블이 만들어지고 이러한 테이블의 데이터는이 데이터베이스에 저장됩니다.동시에이 데이터베이스 리소스에서 테이블 변수, 임시 저장 프로 시저 및 커서가 사용됩니다.또한 TempdDB 리소스는 다음 기능에서도 사용됩니다.
스냅 샷 격리 및 읽기 커밋 된 스냅 샷 격리
온라인 인덱스 작업
MARS – (다중 활성 결과 집합)
SQL 엔진을 다시 시작하면 TempdDB 데이터베이스가 삭제되고 다시 생성됩니다.우리는이 데이터베이스를 백업 할 수 없으며 복구 모델을 단순에서 다른 것으로 변경할 수 없습니다.이 모든 것을 고려할 때 TempDB 데이터베이스 설정이 쿼리 성능에 직접적인 영향을 미친다고 말할 수 있습니다.
SQL Server의 래치는 무엇입니까?
SQL 버퍼 풀은 SQL Server 용으로 운영 체제에서 예약 한 메모리 공간이며 SQL 버퍼 캐시라고도합니다.SQL Server는 데이터 페이지를 읽거나 조작하기 위해 디스크에서 메모리로 데이터 페이지를 전송하고특수 논리에 따라 디스크로 다시 보냅니다.이 메커니즘의 주요 목적은 메모리가 항상 스토리지 시스템보다 빠르기 때문에 클라이언트에 더 빠른 성능을 제공하려는 것입니다.이러한 맥락에서 우리는 버퍼 풀에서 데이터 페이지 일관성을 보장하는 메커니즘이 필요합니다.래치는 SQL Server가 메모리에서 데이터 페이지의 일관성을 보장 할 수 있도록 메모리에 저장된 데이터 구조를 불일치 및 손상으로부터 보호하는 데 사용되는 동기화 개체입니다.이 동기화 작업은 SQL Server에서 내부적으로 관리합니다.
TempDB 데이터베이스 메타 데이터 경합
TempDB 메타 데이터 경합은 임시 테이블을 생성하는 동안 많은 세션이 SQL Server TempDB의 시스템 테이블에 동시에 액세스하려고 할 때 발생합니다.이러한 과중한 워크로드는 이러한 이유로 인해 이러한 시스템 테이블에서 대기 시간을 유발하고 쿼리 성능이 저하됩니다.
이제이 문제를 시뮬레이션하기 위해 TempDB에 가짜 워크로드를 생성합니다.SQLQueryStress라는 구식이지만 좋은 도구를 사용하여 TempDB 데이터베이스에 가짜 워크로드를 생성합니다.
먼저 다음 절차를 생성합니다.이 저장 프로시 저는 임시 테이블을 만들고 sys.all_columns 테이블에서 임의의 20 개 행을 삽입합니다.
CREATEPROCProcTest
AS
BEGIN
CREATETABLE#t1
(
c1INT,
c2INT);
INSERTINTO#t1
SELECTTOP20column_id,
system_type_id
FROMsys.all_columnsWITH(NOLOCK);
END
SQLQueryStress를 시작하고 다음 쿼리를 쿼리 패널에 붙여 넣습니다.이 쿼리는 WHILE 루프에서 ProcTest 저장 프로 시저를 100 번 실행합니다.
DECLARE@iINT;
SET@i=1;
WHILE@i<=100
BEGIN
EXECProcTest;
SET@i=@i+1;
END
우리는 설정합니다반복의 수100을 설정할 것스레드 수저장 프로 시저가 2500 번 실행되도록 25을.
보시다시피PAGELATCH_EX대기 유형은 TempDB 데이터베이스의 wait_info 열에서 볼 수 있습니다.TempDB 데이터베이스의 경우 SQL Server 2019의 새로운 기능을 사용하여이 대기 시간을 극복 할 수 있습니다. 다음 섹션에서는이 기능에 대해 알아 봅니다.
메모리 최적화 TempDB 메타 데이터
메모리 최적화 TempDB 메타 데이터 기능을 활성화하면 일부 SQL Server TempDB 시스템 테이블을 비 지속적 메모리 최적화 테이블로 변환하여 TempDB의 시스템 테이블에 대한 대기 시간을 최소화합니다.메모리 최적화 테이블은 짧은 지연 시간, 높은 처리량 및 가속화 된 응답 시간을 제공하므로이 기능은 이러한 성능 향상을 활용합니다.
저장 프로 시저 인sp_estimate_data_compression_savings는 작업을 압축하기 전에 테이블에 대해 예상되는 압축 이득을 계산합니다.그러나 메모리 최적화 TempDB 메타 데이터 옵션을 활성화 한 경우이 절차는 columnstore 인덱스를 포함하므로 t1 테이블에 대해 작동하지 않습니다.
TempDB 데이터베이스 할당 페이지 경합
데이터 페이지는데이터를 저장하는 SQL Server의 기본 단위이며 데이터 페이지의 크기는 8KB입니다.물리적으로 연속 된 8 개의 데이터 페이지는익스텐트라고합니다.할당 된 익스텐트에 대한 정보는GAM (Global Allocation Map)에의해 기록됩니다.혼합으로 사용되는 익스텐트에 대한 정보는SGAM (Shared Global Allocation Map)에의해 기록됩니다.페이지 여유 공간 (PFS)은 익스텐트의 어느 페이지에서 사용 가능한 여유 공간을 기록합니다.
세션은 임시 테이블을 만들고 삭제할 때 SQL Server TempDB 할당 페이지를 업데이트해야합니다.이 동시 연결 수가 증가하기 시작하면 한 번에 하나의 스레드 만 이러한 페이지를 변경할 수 있으므로 다른 스레드가이 페이지가 할당 된 리소스를 해제 할 때까지 기다려야하기 때문에 이러한 페이지 할당에 액세스하는 것이 더 어려워집니다.이제이 시나리오를 시뮬레이션합니다.
SQLQueryStress를 시작하고 다음 쿼리를 쿼리 패널에 붙여 넣습니다.
SELECTTOP2500*
INTO#t1
FROMsys.all_objectsWITH(NOLOCK);
우리는 설정합니다반복의 수를100 세트로스레드 수200 :
데이터베이스버튼을 클릭하고데이터베이스 자격 증명 및 기타 설정을 지정합니다.
GO버튼을클릭하여 쿼리 실행을 시작합니다.
SQLQueryStress가 쿼리를 수행하는 동안 sp_WhoisActive를 실행하고 wait_info 열의 결과를 분석합니다.
EXECsp_WhoIsActive
보시다시피PAGELATCH_UP대기 유형은 wait_info 열에서 볼 수 있습니다.TempDb 데이터베이스에 더 많은 데이터 파일을 추가하면이 문제가 최소화되며 Microsoft는 필요한 파일 수에 대한 공식을 권장합니다.
“논리 프로세서 수가 8 개 이하이면 논리 프로세서와 동일한 수의 데이터 파일을 사용하십시오.논리 프로세서 수가 8 개보다 크면 8 개의 데이터 파일을 사용합니다.경합이 계속되면 경합이 허용 가능한 수준으로 줄어들 때까지 논리 프로세서 수까지 4의 배수로 데이터 파일 수를 늘립니다.”
이 공식에 따르면 TempDB 데이터베이스의 파일 번호를 늘려이 문제를 최소화 할 수 있습니다.