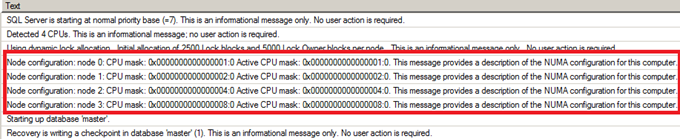
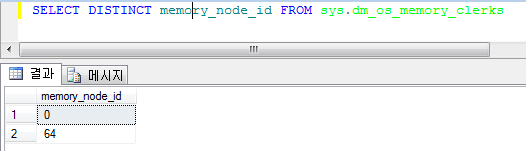
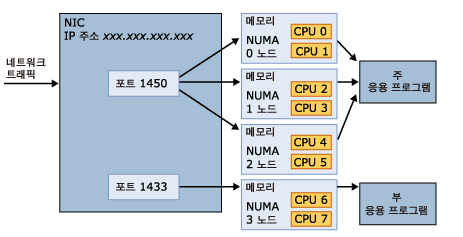
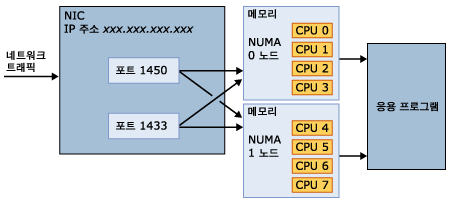
일반적으로 튜닝은 전체적으로 다음과 같은 단계들로 이루어진다.
- 무엇이 문제인지를 확인하고 현재 상태를 진단하여 튜닝의 기준선(Baseline)을 정의
- 병목이 발생하는 지점이 어디인지를 확인
- 확인된 병목을 해소할 방법을 모색
- 해소방법을 적용한 후 다시 성능을 측정하여 (1단계 기준선 대비) 실제로 성능이 향상되었는지를 확인
그래서 튜닝의 고수들은 가장 중요한 것이 "성능의 측정기준을 확인하는 것"이라고도 하지만, 나같은 하수에게는 아무래도 그것보다는 병목을 찾아내는 부분이 더 관심이 가게 마련이다. 6^^
보통 Profiler 를 사용하여 현재 DB에서 실행되는 SQL을 확인하고 악성 SQL을 확인하게 되는데... 이 작업을 하다 보면 다음과 같은 문제가 발생한다.
Type 1 : 분당 300건씩 실행되는 SQL
SELECT IP_ADDR FROM IP_TABLE WHERE SABUN = '29472' -- 실행시간 500ms
SELECT IP_ADDR FROM IP_TABLE WHERE SABUN = '38749' -- 실행시간 500ms
SELECT IP_ADDR FROM IP_TABLE WHERE SABUN = '32945' -- 실행시간 500ms
...
Type 2 : 분당 1건씩 실행되는 SQL
SELECT SERIAL, IP_ADDR, START_DATE, END_DATE FROM IP_TABLE WHERE EMPNO NOT IN (SELECT EMPNO FROM INSATABLE WHERE STATUS = 'R') -- 실행시간 1000ms
위와 같은 두가지 유형의 SQL 중 어느것이 더 악성일까? 당연히 실행 빈도가 훨씬 높은 Type 1이다. 하지만 문제는 이걸 엄청나게 많은 SQL들이 섞여 있는 Profiler에서 육안으로 판단해내기가 쉽지 않다는 것이다. 따라서 악성 SQL을 확인할 때는 다음과 같이 SQL을 일반화해서 비교해야 한다.
Type 1 :
SELECT IP_ADDR FROM IP_TABLE WHERE SABUN = '##' -- 평균 실행시간 500ms, 총 실행시간 150000 ms
Type 2 :
SELECT SERIAL, IP_ADDR, START_DATE, END_DATE FROM IP_TABLE WHERE EMPNO NOT IN (SELECT EMPNO FROM INSATABLE WHERE STATUS = '##') -- 평균 실행시간 1000ms 실행시간 1000 ms
SQL Server 2000 에서는 수집한 SQL을 일반화하기 위해 Read80Trace 프로그램을 사용했었는데... SQL Server 2005에서 수집한 WorkLoad를 분석시키니.. 에러가 나고 제대로 실행이 되지 않았다.
알고 보니 SQL Server 2005에서는 ReadTrace 라는 2005 버젼의 SQL 일반화 Tool 이 따로 제공되고 있었다.
(프로그램 이름에서 80이 떨어진 걸 보니 이 프로그램은 추후 업그레이드될 SQL Server 버젼에서도 일반적으로 사용가능한 모양이다.)
이 프로그램을 사용하는 단계는 전체적으로 다음과 같다.
- RML 패키지 설치
- 부하(Workload) 수집
- 수집한 Workload 를 분석
- 분석 결과 확인
※ RML Utility 도움말에서는 SQLDiag.exe로 시스템 정보를 수집하는 내용이 있지만, 이것은 튜닝대상 서버의 환경을 분석하여 베이스 정보를 수집하기 위한 과정이고, Report 생성에 필요한 과정은 아니라고 도움말에 나와있다. ^^;
좀 더 자세히 살펴보면 다음과 같다.
Step 1. RML 패키지 설치
Workload 분석 툴인 ReadTrace와 Workload Replay 툴인 O'Stress로 이루어진 RML Utility (Replay Markup Language Utility)를 다운받아 설치한다. 가급적이면 분석 대상인 DB서버에 바로 설치하는 것이 여러 모로 편하다. 다음의 URL에서 다운로드할 수 있다.
http://support.microsoft.com/kb/944837
설치 중에 RML Reporter 프로그램을 설치하겠냐고 묻는데 함께 설치한다.
Step 2. DB 에서 부하(Workload)를 수집
Profiler나 SQLDiag, SQL을 수집하는 스크립트(첨부) 등을 사용하여 현재 DB에서 수행되는 SQL (Workload)을 수집하고 trc 파일로 저장한다.
Profiler를 사용하는 방법은... 쉽기는 한데 Workload 수집시에 서버 부하가 높고 내부적으로 ReadTrace가 요구하는 모든 이벤트를 수집해야 하는데 이 조건을 만족시키는 템플릿을 구하기가 어렵고 (내가 만들긴 귀찮고^^)... 모 등등 해서 아래의 SQL문으로 수집하는 것이 낫다. (스크립트 출처 : RML Utility 도움말)
해당 DB서버에서 SQL Server Management Studio로 열고 trc 파일 저장위치('InsertFileNameHere') 부분을 'D:\Test'와 같이 수정하여 실행해준다. trc 확장자는 자동으로 append되므로 붙일 필요가 없으며, 만약의 경우를 대비하여 OS가 설치된 파티션이나 mdf/ldf 파일이 존재하는 파티션과 다른 파티션에 저장하는 것이 좋다.
실행하면 아래와 같은 결과가 SELECT되는데 이 때 내가 실행시킨 수집(Trace) 세션의 ID (아래 그림에서는 "2")를 기억해놓도록 한다.
"메시지" 탭을 선택하면 이 수집(Trace) 작업을 중지시킬 때 뭐라고 입력해야 하는지를 친절하게 알려주고 있다.
탐색기에서 아래와 같이 trc 파일에 Workload 결과가 쌓이는 것을 볼 수 있다. 처음에는 한동안 trc 파일 사이즈가 0KB로 남아있을 수 있는데, 새로고침을 누르면서 몇분간 기다리면 파일 사이즈가 늘어나는 것을 확인할 수 있다.
충분한 Workload가 수집되면 다음의 SQL을 실행하여 Trace를 중지시킨다.
exec sp_trace_setstatus 2, 0 -- stop trace job
exec sp_trace_setstatus 2, 2 -- delete and deallocate trace job
Step 3. 수집한 Workload 를 분석
이제 수집된 Workload를 분석하기 위해 ReadTrace 프로그램을 사용한다.
ReadTrace 프로그램을 DB서버 Local에 설치했다면 이 작업도 당연히 DB서버 로컬에서 수행해야 한다.
ReadTrace.exe 는 커맨드 창에서 실행시켜야 하는 프로그램인데, 설치된 경로를 PATH 환경변수에 지정하기 위해 RML Utility에서 지원하는 RML Command창을 사용한다.
커맨드 창을 연 후 수집한 Workload 파일(trc 파일)이 있는 곳으로 이동하여 ReadTrace.exe를 실행시킨다.
(만약 RML 커맨드창이 아니라면 ReadTrace.exe 파일의 Full Path를 타이핑해주어야 한다.)
실행시키는 명령어는 ReadTrace /? 를 쳐보면 Usage를 볼 수 있으나 기본적으로는 아래와 같은 한가지 파라메터만 주면 된다.
D:\Temp\ReadTrace -ITraceFileName.trc
위와 같이 주면 기본적으로 분석 결과가 PerfAnalysis 라는 DB에 저장된다. 이 경우 여러번 분석하게 되면 이전 결과를 덮어쓰게 되므로 다음과 같이 DB 이름도 지정해줄 수 있다. (당연한 얘기지만... DB가 없으면 생성된다.)
D:\Temp\ReadTrace -ITraceFileName.trc -dPerfDB_20081218_1
Step 4. 분석 결과 확인
ReadTrace를 설치할 때 자동으로 함께 설치되는 RML Reporter 프로그램을 사용하여 분석된 결과를 Visual한 Report로 확인하고 악성 SQL을 찾아낸다. 최초 1번은 자동으로 실행되며 이후 레포트를 다시 보려면 다음과 같이 수동으로 Reporter 프로그램을 실행시키면 된다.
레포트의 첫 페이지는 아래와 같다.
중앙의 큰 그래프는 Workload 수집 시간 중의 부하 변화를 그래프로 보여준다.
여기서 부하를 어떤 기준으로 Grouping할지를 선택할 수 있는데, "Application Name"을 클릭할 경우 아래와 같이 Grouping할 Application을 선택할 수 있다. (한번 클릭할 때마다 탭이 새로 열린다.)
여기서 원하는 Application을 선택하면 아래와 같이 해당 Application이 실행시킨 SQL을 분석하여 보여준다.
위의 그래프를 보면 CPU Usage, Duration, Logical Read, Logical Write 등 다양한 기준 별로 사용율 Top 10 SQL을 보여주고 있다. 그래프에서는 1, 2, 3.. 이렇게 SQL의 번호만 표시되고 있는데, 스크롤 바를 조금만 내려보면 각 번호에 해당하는 SQL을 아래와 같이 보여준다.
위의 SQL중 하나를 클릭하면 아래와 같이 각 SQL에 대한 상세 정보를 볼 수 있다.
솔직히 난... 그래피컬하고 화려한 ReadTrace의 레포트보다 일목요연하고 가지고다니기 편한 Read80Trace의 html 레포트가 더 좋아보인다. (뭐 ReadTrace의 레포트도 Excel 내보내기를 지원하긴 한다.)
이렇게 악성SQL을 찾아내면... 그 다음은 개선만 하면 된다.
뭐, CPU사용율과 Logical Reads가 높은 SQL이라면 인덱스 쪽을 고려해볼 것이고, CPU사용율에 비해 Duration이 높은 경우라면 Blocking을 의심해볼 수 있을 것이다.
'Database > SQL Server' 카테고리의 다른 글
| 쿼럼 리소스 이동 (0) | 2020.08.29 |
|---|---|
| SQL Server Logs 파일 수 변경 및 로그 순환(CYCLE) (0) | 2020.08.29 |
| Master Key (0) | 2020.08.29 |
| [DMV] 특정 프로시저의 실행계획이 바뀌었다? (0) | 2020.08.29 |
| SQL Server2012 Checkpoint 제어 (0) | 2020.08.29 |