MERGE 문을 사용하면 변경할 테이블에 데이터가 존재하는지 체크하고, UPDATE, DELETE, INSERT를 한 번에 작업이 가능하다. MERGE 문을 사용하지 않을 경우 해당 조건으로 테이블을 SELECT 한 후 IF 조건을 사용하여 UPDATE나 INSERT로 분기하는 로직을 작성해야 하는 번거로움이 있다.
MERGE 문의 경우 단일(한개의) 테이블에 UPDATE 또는 INSERT를 하는 경우 많이 사용하지만, 두개의 테이블을 비교하거나 서브 쿼리의 결과에 따라서 UPDATE, INSERT 작업이 가능하다.
MSSQL MERGE 문
단일 테이블 사용법 (DUAL)
오라클에서는 DUAL이라는 dummy 테이블을 USING 절에 사용하면 단일 테이블 작업이 간단하지만, MSSQL에서는 DUAL 테이블이 없기 때문에dummy 서브 쿼리를 사용하면 된다.
MERGE INTO dept AS a
USING (SELECT 1 AS dual) AS b
ON (a.deptno = 50)
WHEN MATCHED THEN
UPDATE SET a.dname = 'IT', a.loc = 'SOUTHLAKE'
WHEN NOT MATCHED THEN
INSERT(deptno, dname, loc) VALUES(50, 'IT', 'SOUTHLAKE')
;
(SELECT 1 AS dual) AS b이부분은 dummy 서브 쿼리 이므로 그대로 복사해서 사용하면 된다.
dept 테이블에 deptno = '50'에 만족하는 값이 있으면 UPDATE, 없으면 INSERT 한다.
DECLARE @deptno INT = 50
DECLARE @dname NVARCHAR(14) = 'IT'
DECLARE @loc NVARCHAR(13) = 'SOUTHLAKE'
MERGE INTO dept AS a
USING (SELECT 1 AS dual) AS b
ON (a.deptno = @deptno)
WHEN MATCHED THEN
UPDATE SET a.dname = @dname, a.loc = @loc
WHEN NOT MATCHED THEN
INSERT(deptno, dname, loc) VALUES(@deptno, @dname, @loc)
;
동일한 쿼리문을 조금 더 이해하기 쉽도록 변수를 사용하여 작성하다.
서브 쿼리를 이용하는 방법
DECLARE @deptno INT = 50
MERGE INTO dept AS a
USING (SELECT DISTINCT
d.deptno AS deptno
, d.dname AS dname
, d.loc AS loc
FROM emp AS e
INNER JOIN dept_history AS d
ON e.deptno = d.deptno
WHERE e.deptno = @deptno) AS b
ON (a.deptno = b.deptno)
WHEN MATCHED THEN
UPDATE SET a.dname = b.dname
, a.loc = b.dname
WHEN NOT MATCHED THEN
INSERT(deptno, dname, loc)
VALUES(b.deptno, b.dname, b.loc)
;
USING 절에 서브 쿼리를 사용하는 방법을 설명한 쿼리이다.
emp 테이블에 deptno = '50'이 존재하고, 서브 쿼리 결과와 dept 테이블을 비교하여 존재 여부에 따라서 UPDATE, INSERT 한다.
두개의 테이블 조인하는 방법
MERGE INTO dept AS a
USING dept_history AS b
ON (a.deptno = b.deptno)
WHEN MATCHED THEN
UPDATE SET a.dname = b.dname
, a.loc = b.loc
WHEN NOT MATCHED THEN
INSERT(deptno, dname, loc)
VALUES(b.deptno, b.dname, b.loc)
;
dept_history 테이블의 값이 dept 테이블에 존재하는 경우, dept_history 테이블의 값으로 UPDATE, 없으면 INSERT 한다.
기타 사용법
ON절에 WHERE 절과 유사하게 AND, OR 를 사용하여 여러개의 조건을 부여할 수 있다.
WHEN절에도 MATCHED, NOT MATCHED 외에 추가로 조건을 부여할 수 있다.
MERGE INTO dept AS a
USING dept_history AS b
ON (a.deptno = b.deptno)
WHEN MATCHED THEN
UPDATE SET a.dname = b.dname, a.loc = b.loc
WHEN NOT MATCHED BY TARGET THEN
INSERT(deptno, dname, loc) VALUES(b.deptno, b.dname, b.loc)
WHEN NOT MATCHED BY SOURCE THEN
DELETE
;
NOT MATCHED 인 경우BY TARGET와BY SOURCE를 사용할 수 있다.
NOT MATCHED BY TARGET(= NOT MATCHED)
TARGET 테이블에 데이터가 없는 경우 TARGET 테이블에 INSERT
NOT MATCHED와 동일 하므로 BY TARGET는 생략해도 된다
NOT MATCHED BY SOURCE
SOURCE 테이블에는 없고 TARGET 테이블에만 존재하는 데이터를 TARGET 테이블에서 DELETE
NOT MATCHED BY SOURCE
DELETE 문에는 WHERE 조건문을 작성하지 않는다.
필요시 WHEN 절에 조건을 작성한다.
MERGE 문 사용 시 주의사항
USING 절에 별칭이 없을 경우
오류 메시지 :키워드 'ON' 근처의 구문이 잘못되었습니다.
쿼리문 끝에 세미콜론이 없을 경우
오류 메시지 :MERGE 문은 세미콜론(;)으로 종료해야 합니다.
USING 절의 데이터에 변경할 테이블과 비교할 테이블의 KEY 컬럼 값이 중복으로 존재 할 경우
오류 메시지 :MERGE 문이 동일한 행을 여러 번 UPDATE 또는 DELETE하려고 했습니다. 대상 행이 둘 이상의 원본 행과 일치하면 이런 경우가 발생합니다. MERGE 문은 대상 테이블의 동일한 행을 여러 번 UPDATE/DELETE할 수 없습니다. ON 절을 구체화하여 대상 행이 하나의 원본 행하고만 일치하도록 하거나 GROUP BY 절을 사용하여 원본 행을 그룹화하십시오.
SQL Server에서 매개 변수 스니핑이란 무엇입니까? 임시 또는 저장 프로 시저를 실행하는 모든 배치는 향후 사용을 위해 계획 캐시에 보관되는 쿼리 계획을 생성합니다. SQL Server는 데이터를 검색하기 위해 최상의 쿼리 계획을 만들려고 시도하지만 계획 캐시의 경우 항상 명확 해 보이는 것은 아닙니다.
SQL Server가 최상의 계획을 선택하는 방법은 비용 추정입니다. 예를 들어 어떤 것이 가장 좋은지 물어 보면 인덱스 검색 후 키 조회 또는 테이블 스캔이 첫 번째로 대답 할 수 있지만 조회 횟수에 따라 다릅니다. 즉, 검색되는 데이터의 양에 따라 다릅니다. 따라서 최상의 쿼리 계획은 입력 매개 변수와 통계를 기반으로 한 카디널리티 추정을 고려합니다.
옵티마이 저가 실행 계획을 생성 할 때 매개 변수 값을 스니핑합니다. 이것은 문제가 아닙니다. 사실 최상의 계획을 세우는 데 필요합니다. 쿼리가 다른 데이터 배포에 최적화 된 이전에 생성 된 계획을 사용할 때 문제가 발생합니다.
대부분의 경우 데이터베이스 워크로드는 동종이므로 매개 변수 스니핑은 문제가되지 않습니다. 그러나 소수의 경우에 이것은 문제가되고 그 결과는 극적 일 수 있습니다.
작동중인 SQL Server 매개 변수 스니핑 이제 예제를 통해 매개 변수 스니핑 문제를 설명하겠습니다.
1. CREATE DATABASE script.
USE [master]
GO
CREATE DATABASE [TestDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'TestDB', FILENAME = N'E:\MSSQL\TestDB.mdf' ,
SIZE = 5MB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = N'TestDB_log', FILENAME = N'E:\MSSQL\TestDB.ldf' ,
SIZE = 5MB , MAXSIZE = 2048GB , FILEGROWTH = 1024KB)
GO
ALTER DATABASE [TestDB] SET RECOVERY SIMPLE
2. Create two simple tables.
USE TestDB
GO
IF OBJECT_ID('dbo.Customers', 'U') IS NOT NULL
DROP TABLE dbo.Customers
GO
CREATE TABLE Customers
(
CustomerID INT NOT NULL IDENTITY(1,1) ,
CustomerName VARCHAR(50) NOT NULL ,
CustomerAddress VARCHAR(50) NOT NULL ,
[State] CHAR(2) NOT NULL ,
CustomerCategoryID CHAR(1) NOT NULL ,
LastBuyDate DATETIME ,
PRIMARY KEY CLUSTERED ( CustomerID )
)
IF OBJECT_ID('dbo.CustomerCategory', 'U') IS NOT NULL
DROP TABLE dbo.CustomerCategory
GO
CREATE TABLE CustomerCategory
(
CustomerCategoryID CHAR(1) NOT NULL ,
CategoryDescription VARCHAR(50) NOT NULL ,
PRIMARY KEY CLUSTERED ( CustomerCategoryID )
)
CREATE INDEX IX_Customers_CustomerCategoryID
ON Customers(CustomerCategoryID)
3. The idea with the sample data is to create an odd distribution.
USE TestDB
GO
INSERT INTO [dbo].[Customers] (
[CustomerName],
[CustomerAddress],
[State],
[CustomerCategoryID],
[LastBuyDate])
SELECT
'Desiree Lambert',
'271 Fabien Parkway',
'NY',
'B',
'2013-01-13 21:44:21'
INSERT INTO [dbo].[Customers] (
[CustomerName],
[CustomerAddress],
[State],
[CustomerCategoryID],
[LastBuyDate])
SELECT
'Pablo Terry',
'29 West Milton St.',
'DE',
'A',
GETDATE()
go 15000
4. Execute the following query and take a look at the query plan.
USE TestDB
GO
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = 'A'
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = 'B'
보시다시피 첫 번째 쿼리는 CustomersCategory 테이블에서 클러스터형 인덱스 검색을 수행하고 tghe Customers 테이블에서 클러스터형 인덱스 스캔을 수행하는 반면 두 번째 쿼리는 비 클러스터형 인덱스 (IX_Customers_CustomerCategoryID)를 사용합니다.그 이유는 쿼리 최적화 프로그램이 주어진 매개 변수에서 쿼리 결과를 예상 할 수있을만큼 똑똑하고 인덱스 검색을 수행 한 후 비 클러스터형 인덱스에 대한 키 조회를 수행하는 대신 클러스터형 인덱스를 스캔하기 때문에 비용이 더 많이 듭니다. 첫 번째 쿼리는 거의 전체 테이블을 반환합니다.
5. Now we create a stored procedure to execute our query.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
GO
6. Execute the stored procedure.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
스크립트에서 먼저 DBCC FREEPROCCACHE를 실행하여 계획 캐시를 정리 한 다음 저장 프로 시저를 실행합니다.아래 이미지를 보면 저장된 프로 시저에 대한 두 번째 호출이 주어진 매개 변수를 고려하지 않고 동일한 계획을 사용하는 방법을 볼 수 있습니다.
그런 다음 동일한 단계를 수행하지만 매개 변수를 역순으로 사용하면 동일한 동작이 표시되지만 쿼리 계획은 다릅니다.
SQL Server 매개 변수 스니핑에 대한 해결 방법
이제 문제를 해결하는 몇 가지 방법이 있습니다.
WITH RECOMPILE 옵션을 사용하여 SQL Server 저장 프로 시저 만들기
SQL Server 힌트 옵션 사용 (권장)
SQL Server 힌트 옵션 (OPTIMIZE FOR) 사용
SQL Server 저장 프로 시저에서 더미 변수 사용
인스턴스 수준에서 SQL Server 매개 변수 스니핑 비활성화
특정 SQL Server 쿼리에 대한 매개 변수 검색 비활성화
WITH RECOMPILE 옵션을 사용하여 SQL Server 저장 프로 시저 만들기
문제가 옵티마이 저가 더 이상 적합하지 않은 매개 변수로 컴파일 된 계획을 사용하는 것이라면 재 컴파일은 새 매개 변수로 새 계획을 생성 할 것입니다. 맞습니까?이것은 가장 간단한 해결책이지만 최고는 아닙니다.문제가 저장 프로 시저 코드 내의 단일 쿼리 인 경우 전체 프로 시저를 다시 컴파일하는 것이 최선의 방법이 아닙니다.문제가있는 쿼리를 수정해야합니다.
또한 재 컴파일은 CPU 부하를 증가시킬 것이며 동시 시스템이 많은 경우 우리가 해결하려는 문제만큼 문제가 될 수 있습니다.
예를 들어, 다음은 재 컴파일 옵션을 사용하여 이전 저장 프로 시저를 만드는 샘플 코드입니다.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Recompile
@CustomerCategoryID CHAR(1)
WITH RECOMPILE
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
GO
SQL Server 힌트 옵션 사용 (권장)
이전 단락에서 말했듯이 전체 저장 프로 시저를 다시 컴파일하는 것은 최선의 선택이 아닙니다.힌트 RECOMPILE을 활용하여 어색한 쿼리 만 다시 컴파일 할 수 있습니다.아래 샘플 코드를보십시오.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Query_Hint_Option_Recompile
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
OPTION(RECOMPILE)
GO
이제 다음 코드를 실행하고 쿼리 계획을 살펴보십시오.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Query_Hint_Option_Recompile @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Query_Hint_Option_Recompile @CustomerCategoryID
GO
이전 이미지에서 볼 수 있듯이 두 쿼리의 매개 변수에 따라 올바른 계획이 있습니다.
SQL Server 힌트 옵션 (OPTIMIZE FOR) 사용
이 힌트를 통해 최적화를위한 참조로 사용할 매개 변수 값을 설정할 수 있습니다.SQL Server OPTIMIZE FOR Hint를 사용하여 매개 변수 기반 쿼리를 최적화하는 Greg Robidoux의 팁에서이 힌트를 읽을 수 있습니다.우리 시나리오에서는 프로 시저가 실행하는 데 사용할 매개 변수 값을 알지 못하기 때문에이 힌트를 사용할 수 없습니다.그러나 SQL Server 2008 이상을 사용하는 경우 OPTIMIZE FOR UNKNOWN은 약간의 빛을 가져옵니다.평신도 용어로 말하면 최상의 계획을 만들지 못할 것이라는 점을 경고해야합니다. 그 결과 계획은 중간에있을 것입니다.따라서이 힌트를 사용하려면 저장 프로 시저가 잘못된 계획으로 실행되는 빈도와 쿼리가 오래 실행되는 환경에 미치는 영향을 고려해야합니다.
이 힌트를 사용하는 샘플 코드는 다음과 같습니다.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Query_Hint_Optimize_Unknown
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
OPTION(OPTIMIZE FOR UNKNOWN )
GO
The next script is to execute our new Stored Procedure.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Query_Hint_Optimize_Unknown @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Query_Hint_Optimize_Unknown @CustomerCategoryID
GO
다음은 실행 계획의 화면 캡처입니다.
SQL Server 저장 프로 시저에서 더미 변수 사용
이것은 2005 년 이전의 SQL Server 버전에서 사용 된 오래된 방법입니다. 입력 매개 변수를 로컬 변수에 할당하고 매개 변수 대신이 변수를 사용합니다.
아래 샘플 코드를보십시오.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Dummy_Var
@CustomerCategoryID CHAR(1)
AS
DECLARE @Dummy CHAR(1)
SELECT @Dummy = @CustomerCategoryID
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @Dummy
GO
To execute this Stored Procedure you can use this code.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Dummy_Var @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Dummy_Var @CustomerCategoryID
GO
이것은 사용자에게 알려지지 않았을 수 있지만 쿼리는 추적 플래그를 힌트로 사용하여 쿼리 최적화 프로그램의 동작을 변경할 수 있습니다.이를 수행하는 방법은 OPTION 절에QUERYTRACEON힌트를추가하는것입니다.
다음은 샘플 저장 프로 시저와 그 실행입니다.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Query_Hint_QUERYTRACEON
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
OPTION(QUERYTRACEON 4136)
GO
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Query_Hint_QUERYTRACEON @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Query_Hint_QUERYTRACEON @CustomerCategoryID
GO
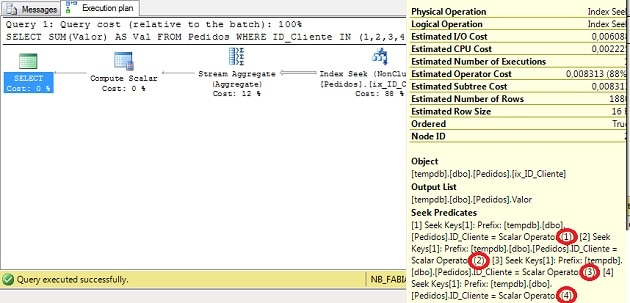
이제 데이터가 있으므로 merge interval을 확인하는 쿼리를 작성할 수 있습니다.다음 쿼리는 4 명의 고객에 대한 매출액을 선택합니다.
SELECTSUM(Valor)ASVal
FROMPedidos
WHEREID_ClienteIN(1,2,3,4)
GO
위 쿼리의 경우 다음과 같은 실행 계획이 있습니다.
그림 1 – 실행 계획 (전체 크기로 보려면 클릭)
위의 실행 계획에서 QO가 인덱스ix_ID_Cliente를 사용하여 IN 절에 지정된각ID_Cliente에대한 데이터를 검색한 다음Stream Aggregate를 사용하여 합계를 수행하는 것을 볼 수있습니다.
이것은 고전적인 Index Seek 작업으로, 각 값에 대해 SQL Server는 데이터를 읽고 균형 잡힌 인덱스 트리에서ID_Cliente를검색합니다.지금은 merge interval이 필요하지 않습니다.
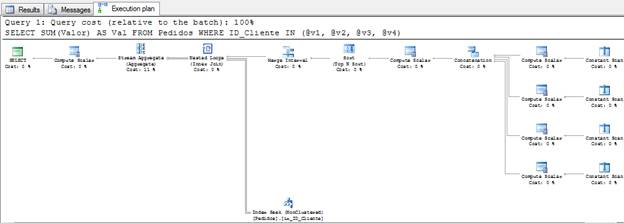
이제 유사한 쿼리를 살펴 보겠습니다.
DECLARE@v1Int=1,
@v2Int=2,
@v3Int=3,
@v4Int=4
SELECTSUM(Valor)ASVal
FROMPedidos
WHEREID_ClienteIN(@v1,@v2,@v3,@v4)
GO
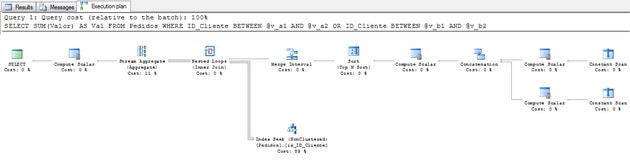
위 쿼리의 경우 다음과 같은 실행 계획이 있습니다.
그림 2 – 실행 계획 (전체 크기로 보려면 클릭)
보시다시피 쿼리 간의 유일한 차이점은 이제 상수 값 대신 변수를 사용하고 있지만 쿼리 최적화 프로그램은이 쿼리에 대해 매우 다른 실행 계획을 생성한다는 것입니다.그래서 질문 : 당신은 어떻게 생각하십니까?SQL이이 쿼리에 대해 동일한 실행 계획을 사용해야한다고 생각하십니까?
정답은 아니오입니다. 왜 안됩니까?컴파일 타임에 SQL Server는 상수 값을 모르고 값이 중복 된 것으로 판명되면 동일한 데이터를 두 번 읽습니다.@ v2의 값도 "1"이라고 가정하면 SQL이 ID 1을 두 번 읽습니다. 하나는 변수@ v1이고 다른 하나는 변수@ v2입니다. 성능을 기대하기 때문에 볼 수 없을 것입니다. 같은 데이터가 두 번이면 좋지 않습니다.따라서 Merge Interval을 사용하여 중복 발생을 제거해야합니다.
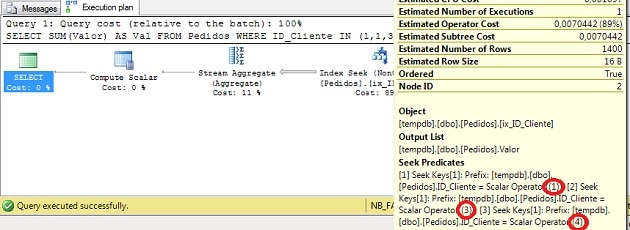
이 시점에서 몇 가지 질문이 떠오를 수 있습니다.첫째 : SQL Server가 IN 변수에 DISTINCT를 사용하여 조인을 제거하지 않는 이유는 무엇입니까?둘째 : 이것이“병합”이라고 불리는 이유는 여기에서 합병과 관련된 어떤 것도 보지 못했습니다.
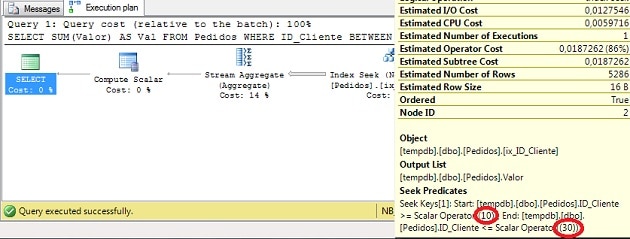
대답은 쿼리 최적화 프로그램 (QO)이이 연산자를 사용하여 DISTINCT를 수행한다는 것입니다.이 코드를 사용하면 QO가 겹치는 간격도 인식하고 잠재적으로이를 겹치지 않는 간격에 병합하여 값을 찾는 데 사용할 수 있기 때문입니다.이를 더 잘 이해하기 위해 변수를 사용하지 않는 다음 쿼리가 있다고 가정 해 보겠습니다.
SELECTSUM(Valor)ASVal
FROMPedidos
WHEREID_ClienteBETWEEN10AND25
ORID_ClienteBETWEEN20AND30
GO
이제 실행 계획을 살펴 보겠습니다.
그림 4 – 실행 계획 (전체 크기로 보려면 클릭)
Query Optimizer가 얼마나 똑똑했는지 주목하십시오.(그래서 내가 그것을 좋아하는 이유입니다!) 술어 사이의 겹침을 인식하고 인덱스에서 두 번의 탐색을 수행하는 대신 (필터 사이에 하나씩) 하나의 탐색 만 수행하는 계획을 만듭니다.
이제 변수를 사용하도록 쿼리를 변경해 보겠습니다.
DECLARE@v_a1Int=10,
@v_b1Int=20,
@v_a2Int=25,
@v_b2Int=30
SELECTSUM(Valor)ASVal
FROMPedidos
WHEREID_ClienteBETWEEN@v_a1AND@v_a2
ORID_ClienteBETWEEN@v_b1AND@v_b2
GO
이 쿼리의 경우 다음 실행 계획이 있습니다.
그림 5 – 실행 계획 (전체 크기로 보려면 클릭)
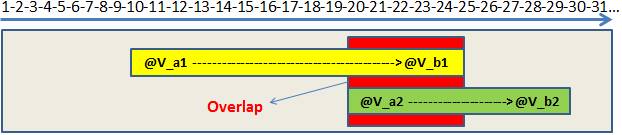
다른 관점을 사용하여 계획이 무엇을하고 있는지 확인합시다.먼저 겹치는 부분을 이해합시다.
그림 6 – 20에서 25 사이의 겹침
그림 6에서 SQL Server가 범위를 개별적으로 읽는 경우 20에서 25까지의 범위를 두 번 읽는 것을 볼 수 있습니다.테스트에 작은 범위를 사용했지만 프로덕션 데이터베이스에서 볼 수있는 매우 큰 스캔의 관점에서 생각합니다.이 단계를 피할 수 있다면 성능이 크게 향상 될 것입니다.
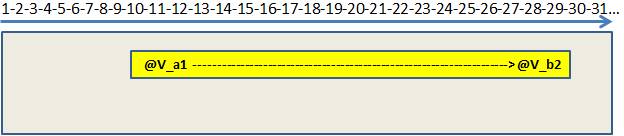
그림 7 – 병합 간격 후
병합 간격이 실행 된 후 SQL Server는 최종 범위 만 검색 할 수 있습니다.@ v_a1에서@ vb_2로직접이동할 수 있음을 알고있습니다.
이것은 무엇을 의미 하는가?이는 반복기가 단일 작업을 수행하는 객체임을 의미합니다.예를 들어 테이블의 데이터를 스캔하거나 테이블의 데이터를 업데이트 할 수 있지만 둘 다 수행 할 수는 없습니다. 그래서반복자 당 하나의 데이터베이스 작업, 그것이 우리가 기억해야 할 정의입니다. 단일 연산자가 그다지 유용하지 않다고 상상할 수 있습니다.일반적으로 아무도 단일 작업을 수행하지 않습니다. 이것이 반복자가 쿼리 계획이라고하는 트리에서 결합되는 이유입니다.쿼리 계획은 각각 자체 작업을 수행하는 여러 반복기 (또는 연산자)로 구성됩니다.
쿼리 계획은 트리 구조이므로 연산자는 자식 (0 개 이상)을 가질 수 있습니다. SQL Server는 각 쿼리를 최적화하려고합니다. 즉, 가장 저렴하거나 가장 빠르게 수행 할 수있는 특정 쿼리에 대해 최상의 반복기 조합을 찾으려고합니다.
반복자는 무엇을합니까?
각 연산자는 다음 세 가지를 수행합니다.
먼저 입력 행을 읽습니다.행은 데이터 소스 또는 연산자의 하위에서 올 수 있습니다.
그런 다음 행을 처리합니다.이것은 반복기의 유형에 따라 다른 것을 의미 할 수 있습니다.
마지막으로 출력을 부모에게 반환합니다.
처리 유형
반복자가 수행 할 수있는 두 가지 유형의 처리가 있습니다.
한 번에 한 행 (또는행 기반 처리). 즉, 해당 반복기에 해당하는 작업이 반복기에 들어가는 각 행에 적용됨을 의미합니다.
그리고배치 모드 처리.이는 연산자가 한 번에 한 행이 아닌 전체 행 일괄 처리를 처리하는 SQL Server 2012에 도입 된 접근 방식입니다.
행 기반 모델
반복기는 메서드와 속성의 공통 인터페이스를 공유하는 코드 개체입니다.가장 자주 사용되는 방법은 행을 처리하고, 속성 정보를 설정 및 검색하고, 최적화 프로그램이 사용할 비용 추정치를 생성하는 데 사용되는 방법입니다.
행 기반 모델에서 모든 반복기는 다음과 같은 동일한 핵심 메서드 집합을 구현합니다.
Open(출력 행 생성을 시작할 때임을 운영자에게 알리는 메서드)
GetRow(연산자에게 새 행을 생성하도록 요청)
그리고Close메서드는 반복기의 부모가 행 요청을 완료했음을 나타냅니다.
모든 반복기는 동일한 구조를 갖기 때문에 서로 독립적으로 작동 할 수 있음을 의미합니다.
이제 쿼리 계획을 살펴보고 하나 이상의 반복기와 이들이 결합되는 방식을 살펴 보겠습니다.
예를 들어 SELECT COUNT (*) FROM Products를 수행하면 내 계획이 이렇게 생겼습니다.
지금 당장 익숙하지 않더라도 걱정하지 마세요. 몇 개의 클립을 더 추가하면 모두 이해하기 시작합니다.
계획을 읽는 방법에는 두 가지가 있습니다.
다음제어 흐름왼쪽에서 오른쪽으로.즉, Open, GetRow 및 Close 메서드가 쿼리 트리의 루트 노드부터 호출되고 결과가 리프 반복기로 전파됩니다.
그리고오른쪽 하단에서 왼쪽 상단까지의데이터 흐름을따릅니다.이것은 데이터가 검색되는 방식입니다.
그래서 우리의 예로 돌아갑니다.내 Products 테이블의 모든 행을 계산하기 위해 두 개의 연산자가 사용됩니다.
테이블에서 모든 행을 가져 오는 하나.이것은 Products 테이블이스캔됨을 의미합니다.
그리고그들을세는하나.앞서 말했듯이 운영자 당 하나의 작업 만 수행 할 수 있습니다.
여기서 무슨 일이 일어나고 있습니까?
작업 순서가있는 그림을 살펴보면 각 단계에 대한 설명이 아래에 있습니다.
먼저 SQL Server는 계획의 루트 반복기에서Open을호출합니다.이 예에서는 COUNT (*) 반복기입니다.COUNT (*) 반복기는 Open 메서드에서 다음 작업을 수행합니다.스캔 반복기에서Open을호출하여 행을 생성 할 시간임을 스캔에 알립니다.비.검색 반복기에서GetRow를반복적으로호출하여 반환 된 행을 계산하고 GetRow가 모든 행을 반환했음을 나타내는 경우에만 중지합니다.C.스캔 반복기에서Close를호출하여 행 가져 오기를 완료했음을 나타냅니다.
COUNT (*) 반복자의 Open 메서드에서 반환 될 때 이미 Products 테이블의 행 수를 알고 있습니다.
그러면 COUNT (*)의GetRow메서드가 실행되어 결과를 반환합니다.
SQL Server는 COUNT (*)가 단일 행을 생성한다는 사실을 모르기 때문에 다른GetRow메서드 호출이 이어집니다.그만한 가치는 다른 모든 행과 마찬가지로 더 이상이 없을 때까지 모든 행을 처리하는 연산자입니다.
두 번째 GetRow 호출에 대한 응답으로 COUNT (*) 반복기는 결과 집합의 끝에 도달했음을 반환합니다.마지막으로 이것은Close메서드의 호출을 의미합니다.COUNT (*) 반복기는 스캔 반복기에서 행을 계산하고 있다는 사실을 신경 쓰거나 알 필요가 없습니다.하위 트리가 얼마나 단순하거나 복잡한 지에 관계없이 SQL Server가 하위 트리에 배치하는 모든 하위 트리의 행을 계산합니다.
SQL Server의 메모리 사용량에 대해 이야기 할 때 종종 버퍼 캐시를 언급합니다.이것은 SQL Server 아키텍처의 중요한 부분이며 자주 액세스하는 데이터를 매우 빠르게 쿼리하는 기능을 담당합니다.버퍼 캐시가 작동하는 방식을 알면 SQL Server에서 메모리를 올바르게 할당하고 데이터베이스가 데이터에 액세스하는 방식을 정확하게 측정하며 과도한 데이터를 캐시하는 코드의 비 효율성이 없는지 확인할 수 있습니다.
버퍼 캐시에는 무엇이 있습니까?
하드 디스크는 느립니다.메모리가 빠릅니다.이것은 컴퓨터로 작업하는 모든 사람에게 자연의 사실입니다.고성능 메모리와 비교할 때 SSD조차도 느립니다.소프트웨어가이 문제를 처리하는 방법은 느린 저장소의 데이터를 빠른 메모리에 쓰는 것입니다.일단로드되면 즐겨 찾는 앱이 매우 빠르게 작동 할 수 있으며 새 데이터가 필요할 때만 디스크로 돌아 가면됩니다.컴퓨팅에서의 이러한 사실은 SQL Server 아키텍처의 중요한 부분이기도합니다.
SQL Server 데이터베이스에서 데이터를 쓰거나 읽을 때마다 버퍼 관리자가 메모리로 복사합니다.버퍼 캐시 (버퍼 풀이라고도 함)는 가능한 한 많은 데이터 페이지를 보유하기 위해 할당 된 메모리를 사용합니다.버퍼 캐시가 가득 차면 최신 데이터를위한 공간을 만들기 위해 오래되고 덜 사용되는 데이터가 제거됩니다.
데이터는 버퍼 캐시 내의 8k 페이지에 저장되며 "깨끗한"또는 "더티"페이지라고 할 수 있습니다.더티 페이지는 디스크에 마지막으로 기록 된 이후 변경된 페이지이며 해당 인덱스 또는 테이블 데이터에 대한 쓰기 작업의 결과입니다.클린 페이지는 변경되지 않은 페이지이며 그 안의 데이터는 여전히 디스크에있는 것과 일치합니다.검사 점은 충돌 또는 기타 불행한 서버 상황이 발생할 경우 알려진 양호한 복원 지점을 만들기 위해 더티 페이지를 디스크에 기록하는 SQL Server에 의해 백그라운드에서 자동으로 실행됩니다.
sys.dm_os_sys_infoDMV를 확인하여 SQL Server의 현재 메모리 사용 상태에 대한 개요를 볼 수 있습니다.
SELECT
physical_memory_kb,
virtual_memory_kb,
committed_kb,
committed_target_kb
FROM sys.dm_os_sys_info;
이 쿼리의 결과는 내 서버의 메모리 사용량에 대해 알려줍니다.
열의 의미는 다음과 같습니다. physical_memory_kb: 서버에 설치된 총 실제 메모리입니다. virtual_memory_kb: SQL Server에서 사용할 수있는 총 가상 메모리 양입니다.이상적으로는 가상 메모리 (디스크 또는 메모리가 아닌 곳에서 페이지 파일 사용)가 메모리보다 훨씬 느리기 때문에 이것을 자주 사용하고 싶지 않습니다. Committed_kb: 데이터베이스 페이지에서 사용하기 위해 버퍼 캐시에서 현재 할당 한 메모리 양입니다. Committed_target_kb: 이것은 버퍼 캐시가 "사용하고자하는"메모리 양입니다.현재 사용중인 양 (committed_kb로 표시됨)이이 양보다 크면 버퍼 관리자가 메모리에서 이전 페이지를 제거하기 시작합니다.현재 사용중인 양이 적 으면 버퍼 관리자가 데이터에 더 많은 메모리를 할당합니다.
메모리 사용은 SQL Server 성능에 매우 중요합니다. 일반적인 쿼리를 처리하는 데 사용할 수있는 메모리가 충분하지 않으면 디스크에서 데이터를 읽는 데 훨씬 더 많은 리소스를 소비하게되며 데이터를 버리고 나중에 다시 읽습니다.
버퍼 캐시 메트릭을 어떻게 사용할 수 있습니까?
동적 관리 뷰sys.dm_os_buffer_descriptors를사용하여 버퍼 캐시에 대한 정보에 액세스 할 수 있습니다.이 뷰는 SQL Server에서 메모리에 저장된 데이터에 대해 알고 싶었지만 물어보기를 두려워했던 모든 것을 제공합니다.이보기 내에서 버퍼 설명 자당 단일 행을 찾을 수 있으며, 이는 메모리의 각 페이지에 대한 정보를 고유하게 식별하고 제공합니다.큰 데이터베이스가있는 서버에서는이 뷰를 쿼리하는 데 약간의 시간이 걸릴 수 있습니다.
쉽게 얻을 수있는 유용한 메트릭은 서버의 데이터베이스 별 버퍼 캐시 사용량 측정입니다.
SELECT
databases.name ASdatabase_name,
COUNT(*)*8/1024ASmb_used
FROM sys.dm_os_buffer_descriptors
INNER JOIN sys.databases
ON databases.database_id=dm_os_buffer_descriptors.database_id
GROUP BY databases.name
ORDER BY COUNT(*)DESC;
이 쿼리는 메모리에있는 대부분의 페이지에서 가장 적은 페이지 순으로 버퍼 캐시의 각 데이터베이스에서 사용하는 메모리 양을 반환합니다.
내 로컬 서버가 지금 그다지 흥미롭지는 않지만 AdventureWorks2014에 대해 다양한 쿼리를 실행하면 위에서부터 쿼리를 다시 실행하여 버퍼 캐시에 미치는 영향을 확인할 수 있습니다.
여기에 너무 미쳐 있지는 않았지만 임의 쿼리로 인해 AdventureWorks2014의 버퍼 캐시에있는 데이터 양이 27MB 증가했습니다.이 쿼리는 버퍼 캐시에서 가장 많은 메모리 사용량을 차지하는 데이터베이스를 빠르게 확인할 수있는 유용한 방법입니다.다중 테넌트 아키텍처 또는 리소스를 공유하는 많은 주요 데이터베이스가있는 서버에서 이는 주어진 시간에 성능이 좋지 않거나 메모리를 많이 차지하는 데이터베이스를 찾는 빠른 방법이 될 수 있습니다.
마찬가지로 전체 합계를 페이지 또는 바이트 수로 볼 수 있습니다.
SELECT
COUNT(*)ASbuffer_cache_pages,
COUNT(*)*8/1024ASbuffer_cache_used_MB
FROM sys.dm_os_buffer_descriptors;
그러면 버퍼 캐시에있는 페이지 수와 사용 된 메모리가 포함 된 단일 행이 반환됩니다.
페이지가 8KB이므로 8을 곱하여 KB를 얻은 다음 1024로 나누어 MB에 도달함으로써 페이지 수를 메가 바이트로 변환 할 수 있습니다.
우리는 이것을 더 세분화하고 특정 객체에서 버퍼 캐시가 어떻게 사용되는지 살펴볼 수 있습니다.이것은 어떤 테이블이 메모리 호그인지 결정할 수 있기 때문에 메모리 사용량에 대한 더 많은 통찰력을 제공 할 수 있습니다.또한 현재 메모리에있는 테이블의 백분율 또는 자주 사용하지 않는 (또는 사용하지 않는) 테이블과 같은 몇 가지 흥미로운 메트릭을 확인할 수 있습니다.다음 쿼리는 테이블별로 버퍼 페이지 및 크기를 반환합니다.
SELECT
objects.name ASobject_name,
objects.type_desc ASobject_type_description,
COUNT(*)ASbuffer_cache_pages,
COUNT(*)*8/1024ASbuffer_cache_used_MB
FROM sys.dm_os_buffer_descriptors
INNER JOIN sys.allocation_units
ON allocation_units.allocation_unit_id=dm_os_buffer_descriptors.allocation_unit_id
시스템 테이블은 제외되며 현재 데이터베이스에 대한 데이터 만 가져옵니다.인덱스가 파생 된 테이블과 구별되는 항목이므로 인덱싱 된 뷰가 포함됩니다.sys.partitions의 조인에는 인덱스와 힙을 고려하기 위해 두 부분이 포함됩니다.여기에 표시된 데이터에는 테이블의 모든 인덱스와 정의 된 것이없는 경우 힙이 포함됩니다.
이 결과의 일부는 다음과 같습니다 (AdventureWorks2014의 경우).
마찬가지로,이 데이터를 테이블이 아닌 인덱스로 분할하여 버퍼 캐시 사용에 대해 더욱 세분화 할 수 있습니다.
SELECT
indexes.name ASindex_name,
objects.name ASobject_name,
objects.type_desc ASobject_type_description,
COUNT(*)ASbuffer_cache_pages,
COUNT(*)*8/1024ASbuffer_cache_used_MB
FROM sys.dm_os_buffer_descriptors
INNER JOIN sys.allocation_units
ON allocation_units.allocation_unit_id=dm_os_buffer_descriptors.allocation_unit_id
이 쿼리는테이블 / 뷰 이름 외에sys.indexes에하나의 추가 조인을 만들고인덱스 이름에 그룹화한다는 점을 제외하면 마지막 쿼리와 거의 동일합니다.결과는 버퍼 캐시가 사용되는 방법에 대한 더 자세한 정보를 제공하며 다양한 용도의 인덱스가 많은 테이블에서 유용 할 수 있습니다.
결과는 주어진 시간에 특정 인덱스에 대한 전체 사용 수준을 확인하려고 할 때 유용 할 수 있습니다.또한 전체 크기와 비교하여 읽고있는 인덱스의 양을 측정 할 수 있습니다.
메모리에있는 각 테이블의 백분율을 수집하기 위해 해당 쿼리를 CTE에 넣고 메모리의 페이지와 각 테이블의 합계를 비교할 수 있습니다.
WITH CTE_BUFFER_CACHE AS(
SELECT
objects.name ASobject_name,
objects.type_desc ASobject_type_description,
objects.object_id,
COUNT(*)ASbuffer_cache_pages,
COUNT(*)*8/1024ASbuffer_cache_used_MB
FROM sys.dm_os_buffer_descriptors
INNER JOIN sys.allocation_units
ON allocation_units.allocation_unit_id=dm_os_buffer_descriptors.allocation_unit_id
ON objects.object_id=dm_db_partition_stats.object_id
WHERE objects.is_ms_shipped=0
GROUP BY objects.name,objects.object_id)PARTITION_STATS
ON PARTITION_STATS.object_id=CTE_BUFFER_CACHE.object_id
ORDER BY CAST(CTE_BUFFER_CACHE.buffer_cache_pages ASDECIMAL)/CAST(PARTITION_STATS.total_number_of_used_pages ASDECIMAL)DESC;
이 쿼리는 이전 데이터 세트를sys.dm_db_partition_stats에대한 쿼리와 조인하여 현재 버퍼 캐시에있는 것과 주어진 테이블에서 사용하는 총 공간을 비교합니다.끝에있는 다양한 CAST 작업은 잘림을 방지하고 최종 결과를 읽기 쉬운 형식으로 만드는 데 도움이됩니다.내 로컬 서버의 결과는 다음과 같습니다.
이 데이터는 데이터베이스에서 어떤 테이블이 핫스팟인지 알려줄 수 있으며, 애플리케이션 사용에 대한 지식을 바탕으로 메모리에 너무 많은 데이터가있는 테이블을 확인할 수 있습니다.작은 테이블은 아마도 여기서 우리에게 그다지 중요하지 않을 것입니다.예를 들어, 위 출력의 상위 4 개는 1 메가 바이트 미만이며이를 생략하려는 경우 특정 관심 크기보다 큰 테이블 만 반환하도록 결과를 필터링 할 수 있습니다.
반면에이 데이터는SalesOrderDetail의3/4가버퍼 캐시에있음을 알려줍니다.이것이 비정상적으로 보이면 쿼리 계획 캐시를 참조하여 *를 선택하는 테이블에 비효율적 인 쿼리가 있는지 또는 지나치게 많은 양의 데이터가 있는지 확인합니다.버퍼 캐시와 계획 캐시의 메트릭을 결합하여 필요한 것보다 훨씬 더 많은 데이터를 가져 오는 잘못된 쿼리 또는 애플리케이션을 찾아내는 새로운 방법을 고안 할 수 있습니다.
이 쿼리는 사용 된 테이블의 백분율을 수집 한 방법과 유사하게 사용중인 인덱스의 백분율을 제공하도록 수정할 수 있습니다.
ORDER BY CAST((CAST(COUNT(*)ASDECIMAL)/CAST(SUM(allocation_units.used_pages)ASDECIMAL)*100)ASDECIMAL(5,2))DESC;
sys.allocation_units는 인덱스에 대한 일부 크기 정보를 제공하므로dm_db_partition_stats에서 추가 CTE 및 데이터 세트가 필요하지않습니다.다음은 인덱스 크기 (MB 및 페이지)와 사용 된 버퍼 캐시 공간 (MB 및 페이지)을 보여주는 결과 조각입니다.
작은 테이블 / 인덱스에 관심이 없다면 특정 크기 (MB 또는 페이지)보다 작은 인덱스로 필터링하기 위해 쿼리에 HAVING 절을 추가 할 수 있습니다.이 데이터는 특정 인덱스에 대한 쿼리의 효율성에 대한 좋은보기를 제공하며 인덱스 정리, 인덱스 조정 또는 SQL Server의 메모리 사용량에 대한보다 세부적인 조정을 지원할 수 있습니다.
dm_os_buffer_descriptors에서 흥미로운 열은free_space_in_bytes열입니다.이는 버퍼 캐시의 각 페이지가 얼마나 가득 차 있는지 알려주므로 잠재적 인 공간 낭비 또는 비 효율성을 나타내는 지표를 제공합니다.서버의 각 데이터베이스에 대해 데이터가 아닌 여유 공간이 차지하는 페이지의 비율을 확인할 수 있습니다.
ORDER BY buffer_cache_free_space_in_MB/NULLIF(buffer_cache_total_MB,0)DESC
그러면 해당 특정 데이터베이스의 버퍼 캐시에있는 모든 페이지에서 합산 된 데이터베이스 당 여유 공간의 집계를 보여주는 데이터베이스 당 행이 반환됩니다.
이것은 흥미롭지 만 아직 그다지 유용하지는 않습니다.그들은 데이터베이스에 약간의 낭비 된 공간이있을 수 있지만 어떤 테이블이 범인인지에 대해서는별로 설명하지 않습니다.이전에했던 것과 동일한 접근 방식을 취하고 주어진 데이터베이스에서 테이블 당 여유 공간을 반환 해 보겠습니다.
이렇게하면 버퍼 캐시에 최소한 하나의 페이지가있는 테이블 또는 인덱싱 된 뷰당 행이 반환되며 메모리에 가장 많은 페이지가있는 페이지부터 순서가 지정됩니다.
이전 예에서와 같이 작은 테이블은 버퍼 캐시 메모리 소비에 미치는 영향이 미미하므로 무시할 수 있습니다.상위 4 개 테이블에는 사용 가능한 공간이 매우 적습니다 (각각 2 % 미만).
이것이 정확히 무엇을 의미합니까?평균적으로 페이지 당 여유 공간이 많을수록 우리가 찾고있는 데이터를 반환하기 위해 더 많은 페이지를 읽어야합니다.또한 데이터를 저장하려면 더 많은 페이지가 필요하므로 데이터를 유지하려면 메모리와 디스크에 더 많은 공간이 필요합니다.낭비 된 공간은 또한 필요한 데이터를 가져 오기위한 더 많은 IO와이 데이터가 검색 될 때 필요한 것보다 오래 실행되는 쿼리를 의미합니다.
여유 공간 과잉의 가장 일반적인 원인은 행이 매우 넓은 테이블입니다.페이지가 8k이기 때문에 행이 5k 인 경우 한 페이지에 단일 행을 넣을 수 없으며 항상 사용할 수없는 추가 ~ 3k 여유 공간이 있습니다.임의 삽입 작업이 많은 테이블도 문제가 될 수 있습니다.예를 들어, 키가 증가하지 않으면 데이터가 순서없이 기록 될 때 페이지 분할이 발생할 수 있습니다.GUID는 최악의 시나리오이지만 본질적으로 증가하지 않는 키는 어느 정도이 문제를 일으킬 수 있습니다.
인덱스가 시간이 지남에 따라 조각화됨에 따라 조각화는 버퍼 캐시의 내용을 볼 때 부분적으로 초과 여유 공간으로 간주됩니다.이러한 문제의 대부분은 스마트 데이터베이스 설계와 합리적인 데이터베이스 유지 관리로 해결됩니다.여기에서 이러한 주제에 대해 자세히 설명 할 수는 없지만 즐거움을 위해 이러한 주제에 대한 많은 기사와 프레젠테이션이 있습니다.
이 기사의 앞부분에서 더티 및 클린 페이지가 무엇인지, 그리고 데이터베이스 내에서 쓰기 작업과의 상관 관계에 대해 간략하게 설명했습니다.dm_os_buffer_descriptors내에서is_modified열을사용하여 페이지가 깨끗한 지 여부를 확인할 수 있습니다.이것은 페이지가 쓰기 작업에 의해 수정되었지만 아직 디스크에 다시 쓰여지지 않았 음을 알려줍니다.이 정보를 사용하여 주어진 데이터베이스에 대한 버퍼 캐시의 깨끗한 페이지와 더티 페이지를 계산할 수 있습니다.
ON dm_os_buffer_descriptors.database_id=databases.database_id
GROUP BY databases.name;
이 쿼리는 페이지 수와 데이터 크기 (MB)를 반환합니다.
내 서버는 현재 너무 많이 진행되지 않습니다.큰 업데이트 문을 실행하면 더 많은 쓰기 작업이 진행될 때 볼 수있는 내용을 설명 할 수 있습니다.다음 쿼리를 실행 해 보겠습니다.
UPDATE Sales.SalesOrderDetail
SET OrderQty=OrderQty
이것은 본질적으로 작동하지 않으며SalesOrderDetail테이블이실제로 변경되지는않지만 SQL Server는이 특정 열에 대한 테이블의 모든 행을 업데이트하는 문제를 겪습니다.위에서 더티 / 클린 페이지 수를 실행하면 더 흥미로운 결과를 얻을 수 있습니다.
버퍼 캐시에있는AdventureWorks2014용 페이지의 약 2/3가 더티페이지입니다.또한TempDB에는 테이블에 대한 업데이트 / 삽입 / 삭제 트리거를 나타내는 상당한 활동이있어 많은 양의 추가 TSQL이 실행되었습니다.트리거로 인해 AdventureWorks2014에 대해 상당히 많은 추가 읽기가 발생했으며이러한 추가 작업을 처리하기 위해TempDB의작업 테이블 공간이 필요했습니다.
이전과 마찬가지로 버퍼 캐시 사용에 대한보다 세분화 된 데이터를 수집하기 위해 테이블 또는 인덱스별로 구분할 수 있습니다.
결과는 인덱스 별 버퍼 캐시 사용량을 보여 주며 메모리의 페이지가 정리되었거나 더럽지 않은지 보여줍니다.
이 데이터는이 시점에서 주어진 인덱스에 대한 쓰기 활동에 대한 아이디어를 제공합니다.며칠 또는 몇 주에 걸쳐 추적했다면 인덱스의 전체 쓰기 활동을 측정하고 추세를 파악할 수 있습니다.이 연구는 데이터베이스에서 사용할 수있는 최상의 격리 수준을 이해하려는 경우 또는 항상 READ UNCOMMITTED로 실행되는 보고서가 원래 생각했던 것보다 더티 읽기에 더 취약 할 수있는 경우 유용 할 수 있습니다.이 특정 경우에 더티 페이지는 모두 이전에 위에서 실행 한 업데이트 쿼리와 관련이 있으므로 다소 제한된 집합으로 구성됩니다.
DBCC DROPCLEANBUFFERS
쿼리를 테스트하고 실행 속도를 정확하게 측정하는 방법으로 자주 사용되는 DBCC 명령은DBCCDROPCLEANBUFFERS입니다.실행되면 전체 데이터베이스 서버의 메모리에서 모든 클린 페이지가 제거되고 일반적으로 소량의 데이터 인 더티 페이지 만 남게됩니다.
DBCC DROPCLEANBUFFERS는 일반적으로 비 프로덕션 환경에서만 실행해야하는 명령이며, 성능이나 부하 테스트가 수행되지 않는 경우에만 실행되어야합니다.이 명령의 결과로 버퍼 캐시가 대부분 비어있게됩니다.이 시점 이후에 실행되는 모든 쿼리는 물리적 읽기를 사용하여 데이터를 스토리지 시스템에서 캐시로 다시 가져와야합니다. 이전에 설정 한 것처럼 메모리보다 훨씬 느릴 수 있습니다.
내 로컬 서버에서이 명령을 실행 한 후 이전의 더티 / 클린 페이지 쿼리는 다음을 반환합니다.
그게 다야!이전 경고를 반복합니다.이 명령을DBCC FREEPROCCACHE와 비슷하게 처리합니다.이 명령은 수행중인 작업을 절대적으로 알지 못하는 경우 프로덕션 서버에서 실행해서는 안됩니다.
이는 메모리의 데이터 캐싱으로 인한 속도 / 효율성 변경없이 성능 테스트 환경에서 쿼리를 반복해서 실행할 수 있다는 점에서 유용한 개발 도구가 될 수 있습니다.실행과 비즈니스 사이에 깨끗한 버퍼 데이터를 삭제하십시오.하지만 프로덕션 환경에서는 항상 버퍼 캐시를 사용하고 필요한 경우가 아니면 스토리지 시스템에서 읽지 않기 때문에 잘못된 결과를 제공 할 수 있습니다.깨끗한 버퍼를 삭제하면 실행 시간이 다른 경우보다 느리지 만 실행될 때마다 일관된 환경에서 쿼리를 테스트하는 방법을 제공 할 수 있습니다.
이러한 모든주의 사항을 이해하고 필요에 따라 쿼리 성능, 쿼리의 결과로 메모리로 읽은 페이지, 쓰기 문에 의해 생성 된 더티 페이지 등에 대한 통찰력을 얻기 위해 필요에 따라 자유롭게 사용하십시오.
페이지 수명
SQL Server의 메모리 성능에 대해 논의 할 때 누군가가 페이지 수명 (줄여서 PLE)에 대해 질문하기까지 몇 분이 걸리지 않을 것입니다.PLE는 평균적으로 페이지가 액세스되지 않고 메모리에 남아있는 시간 (초)을 측정 한 후 제거됩니다.이는 중요한 데이터가 가능한 한 오랫동안 버퍼 캐시에 남아 있기를 바라기 때문에 더 높이고 자하는 지표입니다.PLE가 너무 낮아지면 데이터가 디스크에서 버퍼 캐시로 지속적으로 읽혀지고 (즉, 느리게) 캐시에서 제거되고, 가까운 장래에 디스크에서 다시 읽을 가능성이 높습니다.이것은 느리고 실망스러운 SQL Server의 비결입니다!
서버의 현재 PLE를 보려면 다음 쿼리를 실행하면 성능 카운터 동적 관리보기에서 현재 값을 가져옵니다.
SELECT
*
FROM sys.dm_os_performance_counters
WHERE dm_os_performance_counters.object_name LIKE'%Buffer Manager%'
ANDdm_os_performance_counters.counter_name='Page life expectancy';
결과는 다음과 같습니다.
cntr_value는 성능 카운터의 값이고 조용한 로컬 서버의 경우 210,275 초입니다.SQL Server에서 읽거나 쓰는 데이터가 매우 적기 때문에 버퍼 캐시에서 데이터를 제거해야 할 필요성이 적기 때문에 PLE가 엄청나게 높습니다.더 많이 사용되는 프로덕션 서버에서 PLE는 거의 확실히 더 낮습니다.
서버에 NUMA (비 균일 메모리 액세스) 아키텍처가있는 경우 다음 쿼리로 수행 할 수있는 각 노드에 대해 PLE를 개별적으로 고려할 수 있습니다.
SELECT
*
FROM sys.dm_os_performance_counters
WHERE dm_os_performance_counters.object_name LIKE'%Buffer Node%'
ANDdm_os_performance_counters.counter_name='Page life expectancy';
NUMA가없는 서버에서는 이러한 값이 동일합니다.NUMA 아키텍처를 사용하는 서버에서는 여러 PLE 행이 반환되며,이 행은 모두 버퍼 관리자 전체에 대해 제공된 합계에 합산됩니다.NUMA로 작업하는 경우 전체 합계가 허용되는 반면 하나의 노드에 병목 현상이 발생할 수 있으므로 합계 외에도 각 노드에서 PLE를 고려해야합니다.
지금 가장 분명한 질문은 "PLE의 좋은 가치는 무엇입니까?"입니다.이 질문에 답하려면 서버에 얼마나 많은 메모리가 있는지, 그리고 쓰고 읽는 데이터의 예상 볼륨이 얼마인지 확인하기 위해 서버를 더 자세히 조사해야합니다.300 초는 종종 PLE에 대한 좋은 값으로 던져 지지만 빠르고 쉬운 답변처럼 잘못된 것 같습니다.
PLE가 어떻게 생겼는지 고려하기 전에 그것이 의미하는 바에 대해 좀 더 고려해 봅시다.256GB RAM이있는 서버를 가정 해 보겠습니다.이 중 192GB는 구성에서 SQL Server에 할당됩니다.dm_os_sys_info뷰를확인하고현재 버퍼 캐시에 약 163GB가 커밋되어 있음을 알았습니다.마지막으로 위의 성능 카운터를 확인한 결과이 서버의 PLE가 2000 초임을 확인했습니다.
이러한 메트릭을 기반으로 우리는 버퍼 캐시에 163GB의 메모리를 사용할 수 있으며 데이터는 약 2000 초 동안 존재합니다.이것은 우리가 평균적으로 2000 초당 163GB를 읽고 있다는 것을 의미합니다. 이는 약 83MB / 초로 나옵니다.이 숫자는 응용 프로그램이나 프로세스에서 SQL Server에 얼마나 많이 액세스하고 있는지를 명확하게 보여주기 때문에 매우 유용합니다.좋은 PLE가 무엇인지 고려하기 전에 몇 가지 질문을해야합니다.
애플리케이션 / 서비스에서 예상하는 평균 데이터 트래픽은 얼마나됩니까?
백업, 인덱스 유지 관리, 보관, DBCC CheckDB 또는 기타 프로세스로 인해 PLE가 매우 낮아질 수있는 "특별한"시간이 있습니까?
지연이 문제입니까?응용 프로그램의 성능을 저하시키는 측정 가능한 대기가 있습니까?
서버에 상당한 IO 대기가 있습니까?
가장 많은 데이터를 읽을 것으로 예상되는 쿼리는 무엇입니까?
즉, 씬 데이터를 아십시오!PLE 질문에 대한 유일한 정답은 PLE의 좋은 가치는 사용량 증가 및 급증을 고려할 수있는 충분한 여유 공간을 갖춘 최적의 서버 성능을 나타내는 것입니다.예를 들어, 버퍼 캐시에 할당 된 163GB의 메모리, 2000 초의 평균 PLE, 83MB / 초의 외삽 처리량을 가진 이전 서버를 살펴 보겠습니다.몇 가지 추가 연구 끝에 PLE가 1500 초 미만으로 떨어지면 성능이 저하되기 시작한다는 것을 발견했습니다.이 시점에서 추가 실사를 수행하고 애플리케이션이 한 달에 1 % 씩 증가한다는 것을 알게되었습니다 (데이터 크기 및 처리량 측면에서).결과적으로 6 개월 후에는 현재와 유사한 수준의 PLE를 유지하기 위해 SQL Server 전용 172GB RAM이 필요하다고 추정 할 수 있습니다.시간이 흐르면서
이러한 계산은 용량 계획의 중요한 부분이며 모든 조직이 미래에 대비할 수 있도록합니다.이를 통해 우리는 일이 참을 수 없을 정도로 느려질 때 단순히 서버에 RAM을 추가하는 것이 아니라 능동적으로 유지할 수 있습니다.애플리케이션이 한 달에 1 % 씩 영원히 성장하는 경우는 거의 없습니다.오히려 데이터 증가, 새로운 기능, 아키텍처 변경 및 인프라 변경의 혼합을 기반으로 성장합니다.즉, 응용 프로그램이 한 달에 1 % 씩 증가 할 수 있지만 주요 소프트웨어 릴리스 이후에는 한 번만 증가하면 10 % 증가 할 수 있습니다.
결론
버퍼 캐시를들여다보는 것은 애플리케이션과 프로세스의 성능에 대해 자세히 알아볼 수있는 좋은 방법입니다.이 정보를 사용하여 성능이 저조한 쿼리를 추적하고 예상보다 더 많은 메모리를 사용하는 개체를 식별하며 향후 서버 계획을 개선 할 수 있습니다.이 지식은 누가 영향을 미치고 누가 영향을받을 수 있는지 측면에서 개발, 관리, 아키텍처 및 디자인에 걸쳐 있습니다.결과적으로 서버의 메모리 관리를 효과적으로 관리하면 SQL Server를 사용하는 모든 사람의 경험이 향상되는 동시에 생활이 더 쉬워집니다.
우리는 버퍼 캐시에 대한 유용한 정보를 반환 할 수 있지만 관련된 뷰 및 TSQL에 대해 반드시 자세히 설명하지는 않는 몇 가지 스크립트에 뛰어 들었습니다.향후 기사에서는 우리가 더 자세히 사용한 시스템 뷰 중 일부를 다시 살펴보고 페이지 데이터와이 정보를 큰 이익을 위해이 정보를 사용하는 몇 가지 추가 방법을 살펴볼 것입니다.나는 이것이 한꺼번에 흥미롭고 끔찍할 것이라고 기대하므로 다른 방법은 없을 것입니다.
MSSQL 을 사용하다 유지관리계획의 작업을 삭제를 하려고 하면 아래와 같은 에러 메시지가 나온다.
DELETE 문이 REFERENCE 제약 조건 “FK_subplan_job_id”과(와) 충돌했습니다. 데이터베이스 “msdb”, 테이블 “dbo.sysmaintplan_subplans”, column ‘job_id’에서 충돌이 발생했습니다. 문이 종료되었습니다. (Microsoft SQL Server, 오류: 547)
아래 이미지와 같이 작업에서 DAY_BACKUP 작업관리를 삭제하려면 에레메시지가 발생된다. 원인은 sysmainplan_plans 테이블의 ID값과 해당 작업의 로그가 쌓이는 sysmaintplan_log의 ID값이 서로 다르기 때문에 발생한다. 그럼 이제 이럴경우 삭제하는 방법을 간단하게 알아보자.
1.먼저 삭제할 작업의 목록을 선택 후 작업 스크립팅 -> DROP -> 새쿼리 편집기 창을 클릭한다.
운영환경에서 데이터가 증가하면서 혹은 통계업데이트에 의해 실행계획이 변경되어 쿼리가 갑자기 이전보다 확 느려질 수 있다.
아래와 같은 방법으로 실행계획을 확인할 수 있다.
1) 문제의 쿼리 찾기
--spid 찾기
select hostname, hostprocess, spid from master..sysprocesses where hostname = '호스트네임'
SELECT client_net_address, session_id FROM sys.dm_exec_connections WHERE client_net_address = 'IP'
--실행중인 쿼리 확인 SELECT sqltext.TEXT, req.status, req.command, req.cpu_time, req.total_elapsed_time, req.blocking_session_id, req.percent_complete, req.plan_handle -- 실행계획 확인할 때 사용 FROM sys.dm_exec_requests req CROSS APPLY sys.dm_exec_sql_text(sql_handle) AS sqltext where req.session_id = SPID
2) 실행계획 확인하기
SELECT * FROM sys.dm_exec_query_plan (req.plan_handle);