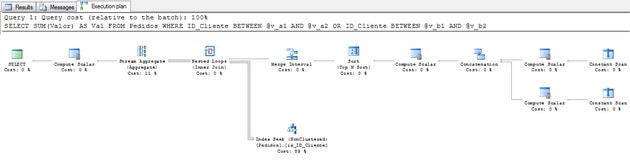
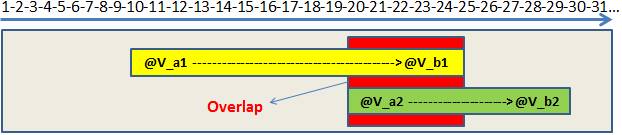
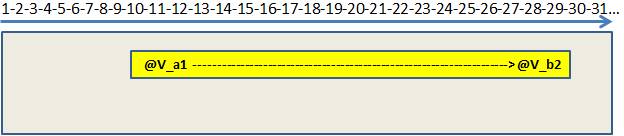
SQL Server에서 매개 변수 스니핑이란 무엇입니까?
임시 또는 저장 프로 시저를 실행하는 모든 배치는 향후 사용을 위해 계획 캐시에 보관되는 쿼리 계획을 생성합니다. SQL Server는 데이터를 검색하기 위해 최상의 쿼리 계획을 만들려고 시도하지만 계획 캐시의 경우 항상 명확 해 보이는 것은 아닙니다.
SQL Server가 최상의 계획을 선택하는 방법은 비용 추정입니다. 예를 들어 어떤 것이 가장 좋은지 물어 보면 인덱스 검색 후 키 조회 또는 테이블 스캔이 첫 번째로 대답 할 수 있지만 조회 횟수에 따라 다릅니다. 즉, 검색되는 데이터의 양에 따라 다릅니다. 따라서 최상의 쿼리 계획은 입력 매개 변수와 통계를 기반으로 한 카디널리티 추정을 고려합니다.
옵티마이 저가 실행 계획을 생성 할 때 매개 변수 값을 스니핑합니다. 이것은 문제가 아닙니다. 사실 최상의 계획을 세우는 데 필요합니다. 쿼리가 다른 데이터 배포에 최적화 된 이전에 생성 된 계획을 사용할 때 문제가 발생합니다.
대부분의 경우 데이터베이스 워크로드는 동종이므로 매개 변수 스니핑은 문제가되지 않습니다. 그러나 소수의 경우에 이것은 문제가되고 그 결과는 극적 일 수 있습니다.
작동중인 SQL Server 매개 변수 스니핑
이제 예제를 통해 매개 변수 스니핑 문제를 설명하겠습니다.
1. CREATE DATABASE script.
USE [master]
GO
CREATE DATABASE [TestDB]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'TestDB', FILENAME = N'E:\MSSQL\TestDB.mdf' ,
SIZE = 5MB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB )
LOG ON
( NAME = N'TestDB_log', FILENAME = N'E:\MSSQL\TestDB.ldf' ,
SIZE = 5MB , MAXSIZE = 2048GB , FILEGROWTH = 1024KB)
GO
ALTER DATABASE [TestDB] SET RECOVERY SIMPLE
2. Create two simple tables.
USE TestDB
GO
IF OBJECT_ID('dbo.Customers', 'U') IS NOT NULL
DROP TABLE dbo.Customers
GO
CREATE TABLE Customers
(
CustomerID INT NOT NULL IDENTITY(1,1) ,
CustomerName VARCHAR(50) NOT NULL ,
CustomerAddress VARCHAR(50) NOT NULL ,
[State] CHAR(2) NOT NULL ,
CustomerCategoryID CHAR(1) NOT NULL ,
LastBuyDate DATETIME ,
PRIMARY KEY CLUSTERED ( CustomerID )
)
IF OBJECT_ID('dbo.CustomerCategory', 'U') IS NOT NULL
DROP TABLE dbo.CustomerCategory
GO
CREATE TABLE CustomerCategory
(
CustomerCategoryID CHAR(1) NOT NULL ,
CategoryDescription VARCHAR(50) NOT NULL ,
PRIMARY KEY CLUSTERED ( CustomerCategoryID )
)
CREATE INDEX IX_Customers_CustomerCategoryID
ON Customers(CustomerCategoryID)
3. The idea with the sample data is to create an odd distribution.
USE TestDB
GO
INSERT INTO [dbo].[Customers] (
[CustomerName],
[CustomerAddress],
[State],
[CustomerCategoryID],
[LastBuyDate])
SELECT
'Desiree Lambert',
'271 Fabien Parkway',
'NY',
'B',
'2013-01-13 21:44:21'
INSERT INTO [dbo].[Customers] (
[CustomerName],
[CustomerAddress],
[State],
[CustomerCategoryID],
[LastBuyDate])
SELECT
'Pablo Terry',
'29 West Milton St.',
'DE',
'A',
GETDATE()
go 150004. Execute the following query and take a look at the query plan.
USE TestDB
GO
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = 'A'
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = 'B'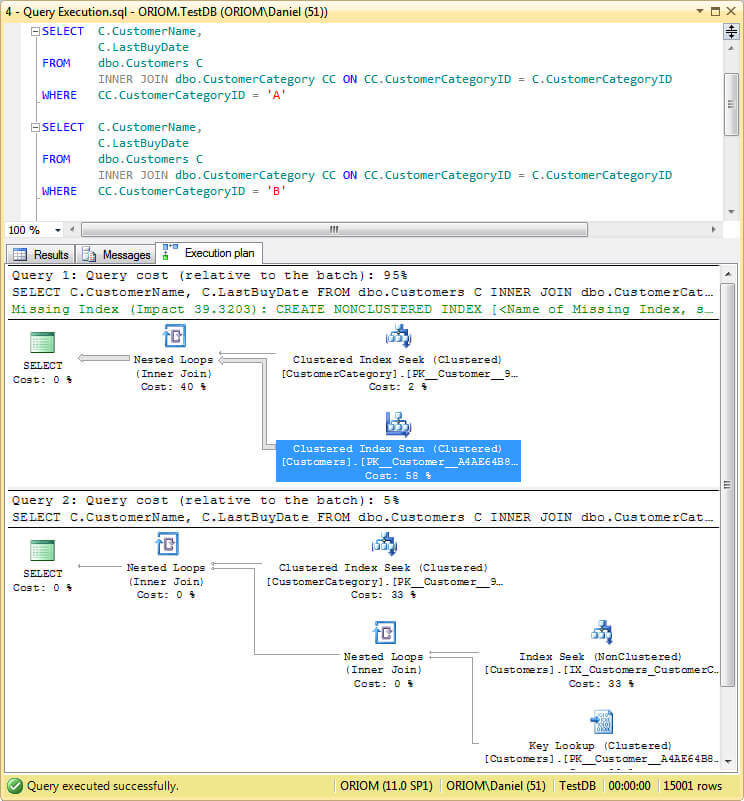
보시다시피 첫 번째 쿼리는 CustomersCategory 테이블에서 클러스터형 인덱스 검색을 수행하고 tghe Customers 테이블에서 클러스터형 인덱스 스캔을 수행하는 반면 두 번째 쿼리는 비 클러스터형 인덱스 (IX_Customers_CustomerCategoryID)를 사용합니다. 그 이유는 쿼리 최적화 프로그램이 주어진 매개 변수에서 쿼리 결과를 예상 할 수있을만큼 똑똑하고 인덱스 검색을 수행 한 후 비 클러스터형 인덱스에 대한 키 조회를 수행하는 대신 클러스터형 인덱스를 스캔하기 때문에 비용이 더 많이 듭니다. 첫 번째 쿼리는 거의 전체 테이블을 반환합니다.
5. Now we create a stored procedure to execute our query.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
GO6. Execute the stored procedure.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing @CustomerCategoryID
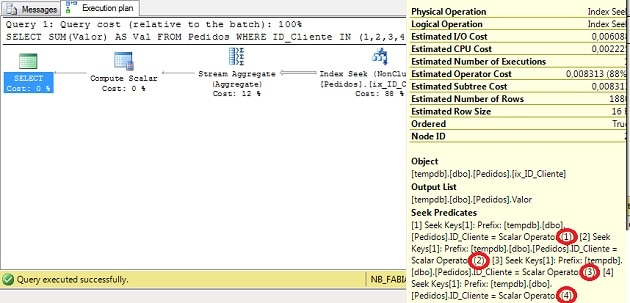
GO스크립트에서 먼저 DBCC FREEPROCCACHE를 실행하여 계획 캐시를 정리 한 다음 저장 프로 시저를 실행합니다. 아래 이미지를 보면 저장된 프로 시저에 대한 두 번째 호출이 주어진 매개 변수를 고려하지 않고 동일한 계획을 사용하는 방법을 볼 수 있습니다.

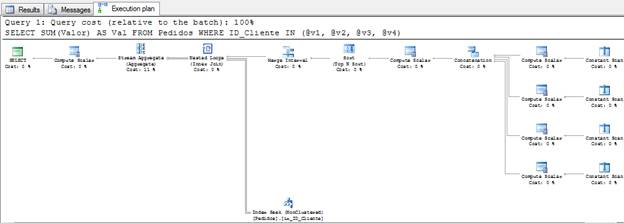
그런 다음 동일한 단계를 수행하지만 매개 변수를 역순으로 사용하면 동일한 동작이 표시되지만 쿼리 계획은 다릅니다.

SQL Server 매개 변수 스니핑에 대한 해결 방법
이제 문제를 해결하는 몇 가지 방법이 있습니다.
- WITH RECOMPILE 옵션을 사용하여 SQL Server 저장 프로 시저 만들기
- SQL Server 힌트 옵션 사용 (권장)
- SQL Server 힌트 옵션 (OPTIMIZE FOR) 사용
- SQL Server 저장 프로 시저에서 더미 변수 사용
- 인스턴스 수준에서 SQL Server 매개 변수 스니핑 비활성화
- 특정 SQL Server 쿼리에 대한 매개 변수 검색 비활성화
WITH RECOMPILE 옵션을 사용하여 SQL Server 저장 프로 시저 만들기
문제가 옵티마이 저가 더 이상 적합하지 않은 매개 변수로 컴파일 된 계획을 사용하는 것이라면 재 컴파일은 새 매개 변수로 새 계획을 생성 할 것입니다. 맞습니까? 이것은 가장 간단한 해결책이지만 최고는 아닙니다. 문제가 저장 프로 시저 코드 내의 단일 쿼리 인 경우 전체 프로 시저를 다시 컴파일하는 것이 최선의 방법이 아닙니다. 문제가있는 쿼리를 수정해야합니다.
또한 재 컴파일은 CPU 부하를 증가시킬 것이며 동시 시스템이 많은 경우 우리가 해결하려는 문제만큼 문제가 될 수 있습니다.
예를 들어, 다음은 재 컴파일 옵션을 사용하여 이전 저장 프로 시저를 만드는 샘플 코드입니다.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Recompile
@CustomerCategoryID CHAR(1)
WITH RECOMPILE
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
GOSQL Server 힌트 옵션 사용 (권장)
이전 단락에서 말했듯이 전체 저장 프로 시저를 다시 컴파일하는 것은 최선의 선택이 아닙니다. 힌트 RECOMPILE을 활용하여 어색한 쿼리 만 다시 컴파일 할 수 있습니다. 아래 샘플 코드를보십시오.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Query_Hint_Option_Recompile
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
OPTION(RECOMPILE)
GO이제 다음 코드를 실행하고 쿼리 계획을 살펴보십시오.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Query_Hint_Option_Recompile @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Query_Hint_Option_Recompile @CustomerCategoryID
GO
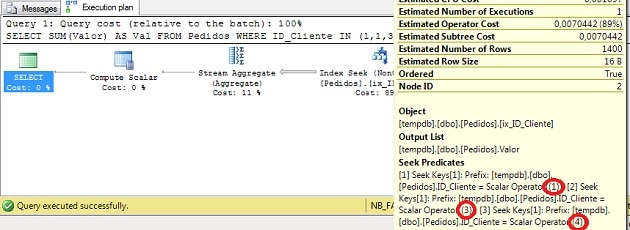
이전 이미지에서 볼 수 있듯이 두 쿼리의 매개 변수에 따라 올바른 계획이 있습니다.
SQL Server 힌트 옵션 (OPTIMIZE FOR) 사용
이 힌트를 통해 최적화를위한 참조로 사용할 매개 변수 값을 설정할 수 있습니다. SQL Server OPTIMIZE FOR Hint를 사용하여 매개 변수 기반 쿼리를 최적화 하는 Greg Robidoux의 팁에서이 힌트를 읽을 수 있습니다 . 우리 시나리오에서는 프로 시저가 실행하는 데 사용할 매개 변수 값을 알지 못하기 때문에이 힌트를 사용할 수 없습니다. 그러나 SQL Server 2008 이상을 사용하는 경우 OPTIMIZE FOR UNKNOWN은 약간의 빛을 가져옵니다. 평신도 용어로 말하면 최상의 계획을 만들지 못할 것이라는 점을 경고해야합니다. 그 결과 계획은 중간에있을 것입니다. 따라서이 힌트를 사용하려면 저장 프로 시저가 잘못된 계획으로 실행되는 빈도와 쿼리가 오래 실행되는 환경에 미치는 영향을 고려해야합니다.
이 힌트를 사용하는 샘플 코드는 다음과 같습니다.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Query_Hint_Optimize_Unknown
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
OPTION(OPTIMIZE FOR UNKNOWN )
GOThe next script is to execute our new Stored Procedure.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Query_Hint_Optimize_Unknown @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Query_Hint_Optimize_Unknown @CustomerCategoryID
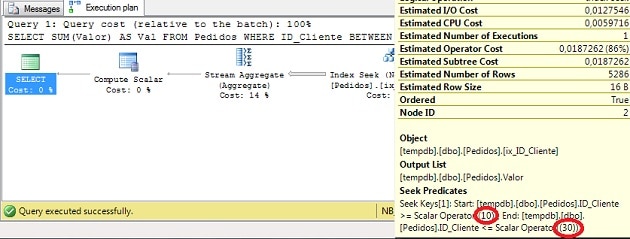
GO다음은 실행 계획의 화면 캡처입니다.

SQL Server 저장 프로 시저에서 더미 변수 사용
이것은 2005 년 이전의 SQL Server 버전에서 사용 된 오래된 방법입니다. 입력 매개 변수를 로컬 변수에 할당하고 매개 변수 대신이 변수를 사용합니다.
아래 샘플 코드를보십시오.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Dummy_Var
@CustomerCategoryID CHAR(1)
AS
DECLARE @Dummy CHAR(1)
SELECT @Dummy = @CustomerCategoryID
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @Dummy
GOTo execute this Stored Procedure you can use this code.
USE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Dummy_Var @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Dummy_Var @CustomerCategoryID
GO결과 계획을보십시오.

인스턴스 수준에서 SQL Server 매개 변수 스니핑 비활성화
아마도 이것은 당신이 할 수있는 최악의 선택 일 것입니다. 앞서 말했듯이 매개 변수 스니핑은 그 자체로 나쁜 것은 아니며 대부분의 경우 최상의 계획을 세우는 데 매우 유용합니다. 그러나 원하는 경우 추적 플래그 4136을 설정하여 인스턴스를 시작하면 매개 변수 스니핑이 비활성화됩니다. SQL Server 2008 R2 누적 업데이트 2, SQL Server 2008 SP1 누적 업데이트 7 및 SQL Server 2005 SP3 누적 업데이트 9에서는 이 플래그를 사용하는 데 필요한 패치 수준과 이에 대한 자세한 내용을 읽을 수 있습니다. "매개 변수 스니핑"프로세스를 비활성화하는 데 사용됩니다 .
이 방법을 사용하기 전에 다음 방법을 살펴보면 훨씬 덜 과감합니다.
특정 SQL Server 쿼리에 대한 매개 변수 검색 비활성화
이것은 사용자에게 알려지지 않았을 수 있지만 쿼리는 추적 플래그를 힌트로 사용하여 쿼리 최적화 프로그램의 동작을 변경할 수 있습니다. 이를 수행하는 방법 은 OPTION 절에 QUERYTRACEON 힌트를 추가하는 것 입니다.
다음은 샘플 저장 프로 시저와 그 실행입니다.
USE TestDB
GO
CREATE PROCEDURE Test_Sniffing_Query_Hint_QUERYTRACEON
@CustomerCategoryID CHAR(1)
AS
SELECT C.CustomerName,
C.LastBuyDate
FROM dbo.Customers C
INNER JOIN dbo.CustomerCategory CC ON CC.CustomerCategoryID = C.CustomerCategoryID
WHERE CC.CustomerCategoryID = @CustomerCategoryID
OPTION(QUERYTRACEON 4136)
GOUSE TestDB
GO
DBCC FREEPROCCACHE()
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'B'
EXEC dbo.Test_Sniffing_Query_Hint_QUERYTRACEON @CustomerCategoryID
GO
DECLARE @CustomerCategoryID CHAR(1)
SET @CustomerCategoryID = 'A'
EXEC dbo.Test_Sniffing_Query_Hint_QUERYTRACEON @CustomerCategoryID
GO
실행 계획의 화면 캡처입니다.

'Database > SQL Server' 카테고리의 다른 글
| 쿼리 (0) | 2021.12.08 |
|---|---|
| MERGE 문 사용법 (DUAL, UPDATE와 INSERT를 한번에) (0) | 2021.07.08 |
| Login을 각 Database의 User와 동기화 하기 (0) | 2021.02.09 |
| Showplan Operator of the Week – Merge Interval (0) | 2021.02.02 |
| Iterators in the Query Execution Plan (0) | 2021.02.02 |